python爬虫之验证码篇3-滑动验证码识别技术
滑动验证码介绍
本篇涉及到的验证码为滑动验证码,不同于极验证,本验证码难度略低,需要的将滑块拖动到矩形区域右侧即可完成。
这类验证码不常见了,官方介绍地址为:https://promotion.aliyun.com/ntms/act/captchaIntroAndDemo.html
使用起来肯定是非常安全的了,不是很好通过机器检测
如何判断验证码类型
这个验证码的标识一般比较明显,在页面源码中一般存在一个 nc.js 基本可以判定是阿里云的验证码了
<script type="text/javascript" src="https://g.alicdn.com/sd/ncpc/nc.js?t=1552906749855"></script>
识别套路
截止到2019年3月18日,本验证码加入了大量的selenium关键字验证,所以单纯的模拟拖拽被反爬的概率满高的,你也知道一般情况爬虫具备时效性 不确保这种手段过一段时间还可以使用!
导入selenium必备的一些模块与方法 from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait # from selenium.webdriver.support import expected_conditions as EC # from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options from selenium.webdriver import ActionChains import time import random
在启动selenium之前必须要设置一个本机的代理,进行基本的反[反爬] 处理,很多爬虫在获取用户指纹的时候,都比较喜欢selenium,因为使用selenium模拟浏览器进行数据抓取,能够绕过客户JS加密,绕过爬虫检测,绕过签名机制
但是selenium越来越多的被各种网站进行了相关屏蔽,因为selenium在运行的时候会暴露出一些预定义的Javascript变量(特征字符串),例如"window.navigator.webdriver",在非selenium环境下其值为undefined,而在selenium环境下,其值为true
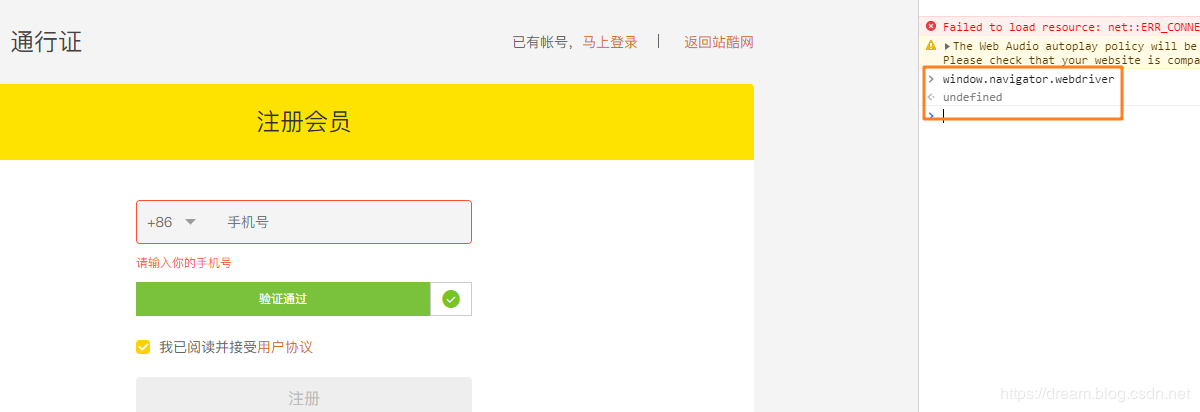
下图所示为selenium驱动下Chrome控制台打印出的值
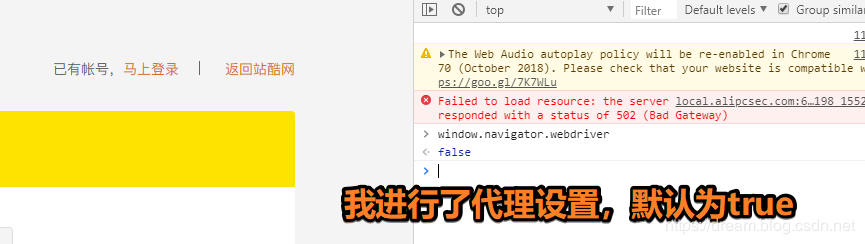
细致的绕过去的方法,可能需要单独的一篇博客进行赘述了,这里我只对上面的参数进行屏蔽,使用到的是之前博客中涉及的mitmdump进行代理
https://docs.mitmproxy.org/stable/concepts-certificates/
mitmdump进行代理
技术参考来源:https://zhuanlan.zhihu.com/p/43581988
关于这个模块的基本使用,参考我前面的博客即可,这里核心使用了如下代码
indject_js_proxy.py
from mitmproxy import ctx
injected_javascript = '''
// overwrite the `languages` property to use a custom getter
Object.defineProperty(navigator, "languages", {
get: function() {
return ["zh-CN","zh","zh-TW","en-US","en"];
}
});
// Overwrite the `plugins` property to use a custom getter.
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
});
// Pass the Webdriver test
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
// Pass the Chrome Test.
// We can mock this in as much depth as we need for the test.
window.navigator.chrome = {
runtime: {},
// etc.
};
// Pass the Permissions Test.
const originalQuery = window.navigator.permissions.query;
window.navigator.permissions.query = (parameters) => (
parameters.name === 'notifications' ?
Promise.resolve({ state: Notification.permission }) :
originalQuery(parameters)
);
'''
def response(flow):
# Only process 200 responses of HTML content.
if not flow.response.status_code == 200:
return
# Inject a script tag containing the JavaScript.
html = flow.response.text
html = html.replace('<head>', '<head><script>%s</script>' % injected_javascript)
flow.response.text = str(html)
ctx.log.info('>>>> js代码插入成功 <<<<')
# 只要url链接以target开头,则将网页内容替换为目前网址
# target = 'https://target-url.com'
# if flow.url.startswith(target):
# flow.response.text = flow.url
上述脚本放置任意目录,之后进行mitmdump的启动即可
C:\user>mitmdump -s indject_js_proxy.py
Loading script indject_js_proxy.py
Proxy server listening at http://*:8080
启动之后,通过webdriver访问
测试网站:https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html
如果webDriver是绿色,也说明代理起作用了
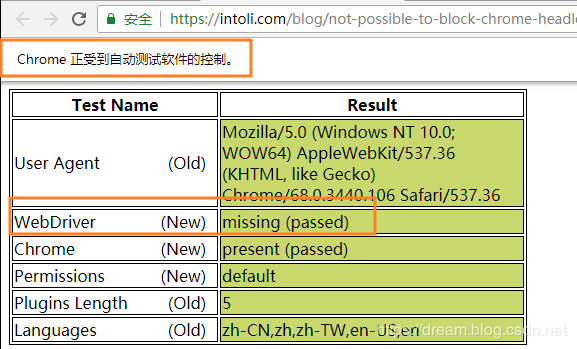
selenium爬取
接下来就是通过selenium进行一些模拟行为的操作了,这部分代码比较简单,编写的时候参考一下注释即可。
# 实例化一个启动参数对象
chrome_options = Options()
# 添加启动参数
chrome_options.add_argument('--proxy-server=127.0.0.1:8080')
# 将参数对象传入Chrome,则启动了一个设置了窗口大小的Chrome
driver = webdriver.Chrome(chrome_options=chrome_options)
关键函数
def move_to_gap(tracks):
driver.get("https://passport.zcool.com.cn/regPhone.do?appId=1006&cback=https://my.zcool.com.cn/focus/activity")
# 找到滑块span
need_move_span = driver.find_element_by_xpath('//*[@id="nc_1_n1t"]/span')
# 模拟按住鼠标左键
ActionChains(driver).click_and_hold(need_move_span).perform()
for x in tracks: # 模拟人的拖动轨迹
print(x)
ActionChains(driver).move_by_offset(xoffset=x,yoffset=random.randint(1,3)).perform()
time.sleep(1)
ActionChains(driver).release().perform() # 释放左键
注意看到上述代码中有何核心的点 --- 拖拽距离的 列表tracks
if __name__ == '__main__': move_to_gap(get_track(295))
这个地方可以借鉴网上的方案即可
def get_track(distance):
'''
拿到移动轨迹,模仿人的滑动行为,先匀加速后匀减速
匀变速运动基本公式:
①v=v0+at
②s=v0t+(1/2)at²
③v²-v0²=2as
:param distance: 需要移动的距离
:return: 存放每0.2秒移动的距离
'''
# 初速度
v=0
# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移
t=0.1
# 位移/轨迹列表,列表内的一个元素代表0.2s的位移
tracks=[]
# 当前的位移
current=0
# 到达mid值开始减速
mid=distance * 4/5
distance += 10 # 先滑过一点,最后再反着滑动回来
while current < distance:
if current < mid:
# 加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
a = 2 # 加速运动
else:
a = -3 # 减速运动
# 初速度
v0 = v
# 0.2秒时间内的位移
s = v0*t+0.5*a*(t**2)
# 当前的位置
current += s
# 添加到轨迹列表
tracks.append(round(s))
# 速度已经达到v,该速度作为下次的初速度
v= v0+a*t
# 反着滑动到大概准确位置
for i in range(3):
tracks.append(-2)
for i in range(4):
tracks.append(-1)
return tracks
代码注释已经添加好,可以自行查阅,临摹一下即可明白
最后开始进行尝试,实测中,发现可以自动拖动,但是,出现一个问题是最后被识别为机器,这个地方,我进行了多次的修改与调整,最终从代码层面发现实现确实有些复杂,所以改变策略,找一下chromedriver.exe是否有修改过的版本,中间去除了selenium的一些关键字,运气不错,被我找到了。
目前只有windows10版本和linux16.04版本
gitee地址:https://gitee.com/bobozhangyx/java-crawler/tree/master/file/%E7%BC%96%E8%AF%91%E5%90%8E%E7%9A%84chromedriver
下载之后,替换你的 chromedriver.exe

再次运行,成功验证
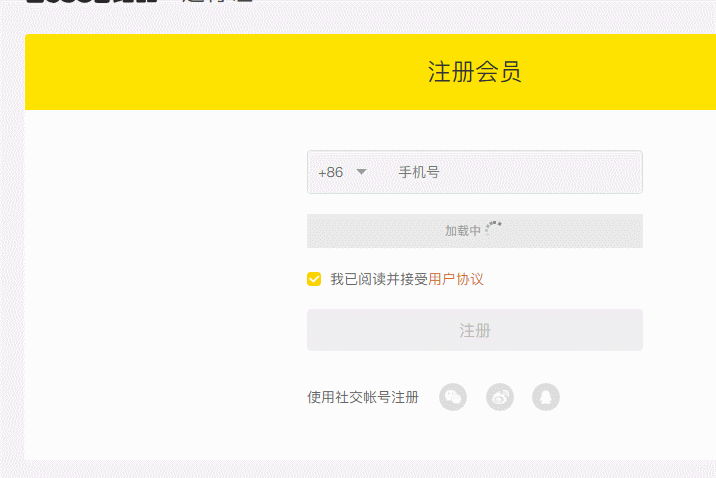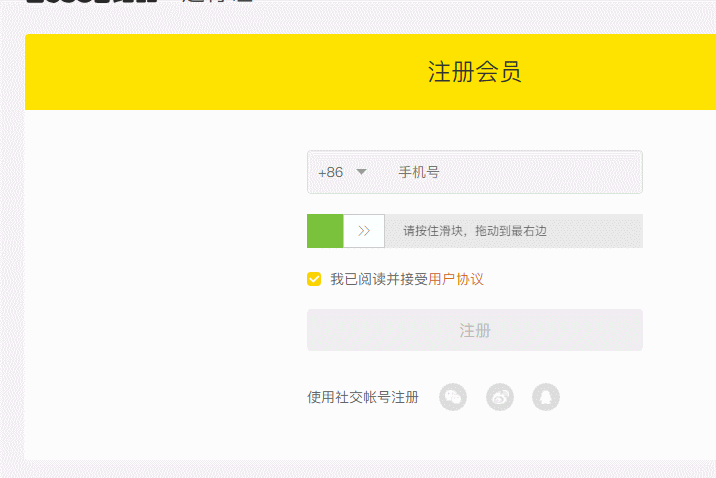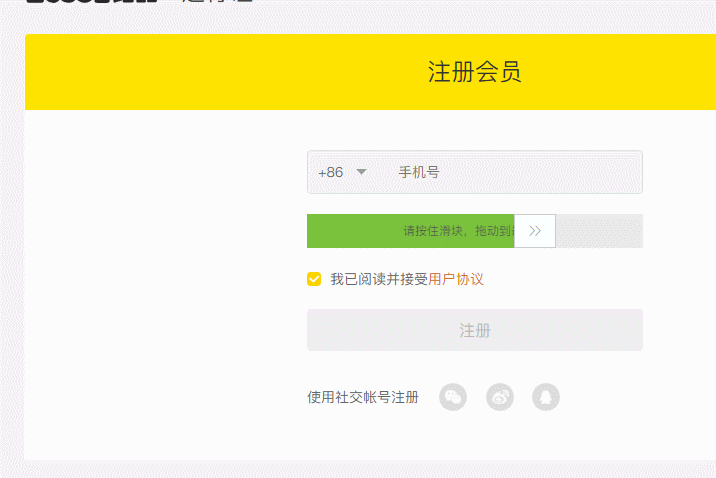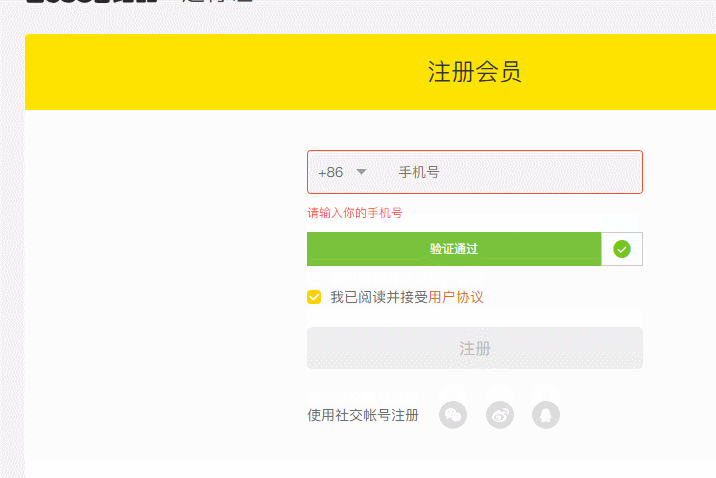
总结
以上所述是小编给大家介绍的python爬虫之验证码篇3-滑动验证码识别技术,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python3简单爬虫抓取网页图片代码实例
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到大家,并希望大家批评指正. import urllib.request import re import os import urllib #根据给定的网址来获取网页详细信息,得到的html就是网页的源代码 def getHtml(url): page = urllib.request.urlope
-
33个Python爬虫项目实战(推荐)
今天为大家整理了32个Python爬虫项目. 整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- 豆瓣读书爬虫.可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1
-

Python 3实战爬虫之爬取京东图书的图片详解
前言 最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫. 实现分析 首先,打开要爬取的第一个网页,这个网页将作为要爬取的起始页面.我们打开京东,选择图书分类,由于图书所有种类的图书有很多,我们选择爬取所有编程语言的图书图片吧,网址为:https://list.jd.com/list.html?cat=1713
-
Python爬虫实战之12306抢票开源
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 余票查询界面 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-2
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
python3.7简单的爬虫实例详解
python3.7简单的爬虫,具体代码如下所示: #https://www.runoob.com/w3cnote/python-spider-intro.html #Python 爬虫介绍 import urllib.parse import urllib.request from http import cookiejar url = "http://www.baidu.com" response1 = urllib.request.urlopen(url) print("
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
python爬虫之验证码篇3-滑动验证码识别技术
滑动验证码介绍 本篇涉及到的验证码为滑动验证码,不同于极验证,本验证码难度略低,需要的将滑块拖动到矩形区域右侧即可完成. 这类验证码不常见了,官方介绍地址为:https://promotion.aliyun.com/ntms/act/captchaIntroAndDemo.html 使用起来肯定是非常安全的了,不是很好通过机器检测 如何判断验证码类型 这个验证码的标识一般比较明显,在页面源码中一般存在一个 nc.js 基本可以判定是阿里云的验证码了 <script type="text/j
-
python+selenium行为链登录12306(滑动验证码滑块)
使用python网络爬虫登录12306,网站界面如下.因为网站的反爬是不断升级的,以下代码虽然当前可用,但早晚必将会不再能满足登录需求.但是知识的价值,是不容置疑的. from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time from selenium.webdriver import ChromeOptions # 去除浏览器识别 opt
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此
-
Python爬虫番外篇之Cookie和Session详解
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么是Cookie 其实简单的说就是当用户通过http协议访问一个服务器的时候,这个服务器会将一些Name/Value键值对返回给客户端浏览器,并将这些数据加上一些限制条件.在条件符合时,这个用户下次再访问服务器的时候,数据又被完整的带给服务器. 因为http是一种无状态协议,用户首次访问web站点的时
-
Python 200行代码实现一个滑动验证码过程详解
前言 做网络爬虫的同学肯定见过各种各样的验证码,比较高级的有滑动.点选等样式,看起来好像挺复杂的,但实际上它们的核心原理还是还是很清晰的,本文章大致说明下这些验证码的原理以及带大家实现一个滑动验证码. 实际上这类验证码的校验是分为两个步骤的: 1.第一步就是前端的校验.一般来说,登录注册页面在点击提交的时候都会伴随着一个表单提交,在表单提交的时候会有 JavaScript 事件的触发.如果加入了验证码,那么在表单提交的时候会多加一个额外的验证,判断这个验证码是否已经成功完成了操作.如果没有的话,
-
Python3网络爬虫开发实战之极验滑动验证码的识别
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-
python自动化操作之动态验证码、滑动验证码的降噪和识别
目录 前言 一.动态验证码 二.滑动验证码 三.验证码的降噪 四.验证码的识别 总结 前言 python对动态验证码.滑动验证码的降噪和识别,在各种自动化操作中,我们经常要遇到沿跳过验证码的操作,而对于验证码的降噪和识别,的确困然了很多的人.这里我们就详细讲解一下不同验证码的降噪和识别. 一.动态验证码 动态验证码是服务端生成的,点击一次,就会更换一次,这就会造成很多人在识别的时候,会发现验证码一直过期 这是因为,如果你是把图片下载下来,进行识别的话,其实在下载的这个请求中,其实相当于点击了一次
-
python识别和降噪动态验证码与滑动验证码
目录 一.动态验证码 二.滑动验证码 三.验证码的降噪 四.验证码的识别 〝 古人学问遗无力,少壮功夫老始成 〞 python对动态验证码.滑动验证码的降噪和识别,在各种自动化操作中,我们经常要遇到沿跳过验证码的操作,而对于验证码的降噪和识别,的确困然了很多的人.这里我们就详细讲解一下不同验证码的降噪和识别.如果这篇文章能给你带来一点帮助,希望各位小伙伴们多多支持我们. 一.动态验证码 动态验证码是服务端生成的,点击一次,就会更换一次,这就会造成很多人在识别的时候,会发现验证码一直过期 这是因为
-
Python3爬虫关于识别检验滑动验证码的实例
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-
用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium