浅析顺序结构存储的栈
栈定义:仅限在表尾进行插入和删除的线性表
栈的特点:
1)一般来说能在表尾进行进栈和出栈的数据
2)先进后出(last in first out )
3)栈会有栈顶,栈底,通常栈底为高地址,栈顶为高地址,如下图所示
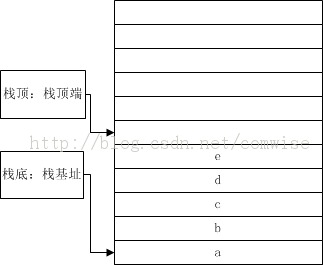
操作系统一般会在内存划出一块,专门用于栈操作,当然这个跟普通的操作有些区别:比如存放数组,地址是增加的;但是在存入数据到栈,地址则是不断减小的
typedef struct _SQSTACK
{
SElemType* base;
SElemType* top;
int stacksize;
}
SqStack;
//默认的存储空间的大小和空间增长大小
#define STACK_INIT_SIZE 100
#define STACK_INCREMENT 10
//存储数据的类型定义
#ifndef INT_TYPE
#define INT_TYPE
#endif // INT_TYPE
#ifdef INT_TYPE
typedef int SElemType;
#elif defined FLOAT_TYPE
typedef float SElemType;
#elif defined STRING_TYPE
typedef char* SElemType;
#elif defined STRUCT_TYPE
typedef void* SElemType;
#endif
栈的操作,会涉及到初始化栈,销毁栈,进栈(入栈),出栈,还有判断栈空,栈大小,以及清空栈,如下:
栈的初始化:
代码如下:
//初始化栈
int InitStack(SqStack *S)
{
S->base = (SElemType*)malloc(STACK_INIT_SIZE*sizeof(SElemType));
if (!S->base)
{
return -1;
}
S->top = S->base;
S->stacksize = STACK_INIT_SIZE;
return 0;
}
栈才初始化,里面还没有数据,这时候top,base都指向分配空间的基地址,表示栈空
销毁栈:
代码如下:
//销毁栈
int DestroyStack(SqStack *S)
{
if (S->base)
{
free(S->base);
S->base = NULL;
S->top = NULL;
S->stacksize = 0;
}
return 0;
}
int Push(SqStack *S, const SElemType data)
{
assert(S->base != NULL);
if (S->top - S->base >= STACK_INIT_SIZE)
{
S->base = (SElemType*)realloc(S->base,
(STACK_INIT_SIZE + STACK_INCREMENT) * sizeof(SElemType));
if (!S->base)
{
return -1;
}
S->top = S->base + S->stacksize;
S->stacksize += STACK_INCREMENT;
}
*S->top++ = data;
return 0;
}
int Push(SqStack *S, const SElemType data)
{
assert(S->base != NULL);
if (S->top - S->base >= STACK_INIT_SIZE)
{
S->base = (SElemType*)realloc(S->base,
(STACK_INIT_SIZE + STACK_INCREMENT) * sizeof(SElemType));
if (!S->base)
{
return -1;
}
S->top = S->base + S->stacksize;
S->stacksize += STACK_INCREMENT;
}
*S->top++ = data;
return 0;
}
如果栈的大小大于已分配长度,重新分配空间,并使栈顶重新指向新的位置,之后就将数据存入当前栈顶指向的位置,然后栈顶+1
出栈:
代码如下:
//出栈
int Pop(SqStack *S, SElemType *data)
{
assert(S->base != NULL);
if (S->base == S->top)
{
return -1;
}
*data = *(--S->top);
return 0;
}
首先将栈顶位置-1,然后取得当前位置的值
以下为辅助函数,如下:
代码如下:
//栈是否为空
int IsStackEmpty(const SqStack &S)
{
return ((S.base == S.top) ? true:false);
}
//得到栈的长度
int GetStackLength(const SqStack &S)
{
assert(S.base != NULL);
return S.stacksize;
}
//清空栈
int ClearStack(SqStack *S)
{
assert(S->base != NULL);
if (S->base != S->top)
{
S->top = S->base;
}
S->stacksize = 0;
return 0;
}
相关推荐
-

浅析顺序结构存储的栈
栈定义:仅限在表尾进行插入和删除的线性表 栈的特点: 1)一般来说能在表尾进行进栈和出栈的数据 2)先进后出(last in first out ) 3)栈会有栈顶,栈底,通常栈底为高地址,栈顶为高地址,如下图所示 操作系统一般会在内存划出一块,专门用于栈操作,当然这个跟普通的操作有些区别:比如存放数组,地址是增加的:但是在存入数据到栈,地址则是不断减小的 栈的存储结构: 复制代码 代码如下: typedef struct _SQSTACK{ SElemType* base; SElemType
-
C语言栈顺序结构实现代码
复制代码 代码如下: /*** @brief C语言实现的顺序结构类型的栈* @author wid* @date 2013-10-29** @note 若代码存在 bug 或程序缺陷, 请留言反馈, 谢谢!*/ #include <stdio.h>#include <stdlib.h>#include <string.h> #define TRUE 1#define FALSE 0 typedef struct Point2D{ int x; int y;
-
浅析C# 结构体struct
结构体 有时候我们仅需要一个小的数据结构,类提供的功能多于我们需要的功能:考虑到性能原因,最好使用结构体. 结构体是值类型,存储在栈中或存储为内联(如果结构体是存储在堆中的另一个对象的一部分). 例如类class: public class Dimensions { public Dimensions(double length, double width) { Length = length; Width = width; } public double Length { get; set;
-
详细聊一聊mysql的树形结构存储以及查询
目录 序 存储parent 存储path MPTT(Modified Preorder Tree Traversal) 小结 doc 序 本文主要研究一下mysql的树形结构存储及查询 存储parent 这种方式就是每个节点存储自己的parent_id信息 建表及数据准备 CREATE TABLE `menu` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) NOT NULL, `parent_id` int(11) NOT
-
php浅析反序列化结构
目录 简介 反序列化中常见的魔术方法 反序列化绕过小Trick 绕过_wakeup(CVE-2016-7124) 绕过部分正则 利用引用 16进制绕过字符的过滤 简介 序列化的目的是方便数据的传输和存储,在PHP中,序列化和反序列化一般用做缓存,比如session缓存,cookie等. 反序列化中常见的魔术方法 __wakeup() //执行unserialize()时,先会调用这个函数 __sleep() //执行serialize()时,先会调用这个函数 __destruct() //对象被
-
java实现顺序结构线性列表的函数代码
废话不多说,直接上代码 复制代码 代码如下: package com.ncu.list; /** * * 顺序结构线性列表 * * */public class SquenceList<T> { private int size; // 线性表的长度 private Object[] listArray; private int currenSize = 0; // 当前线性表中的数据 public SquenceList() { } public SquenceLis
-
C++程序的执行顺序结构以及关系和逻辑运算符讲解
C++顺序结构程序 [例]求一元二次方程式ax2+bx+c=0的根.a,b,c的值在运行时由键盘输入,它们的值满足b2-4ac≥0.根据求x1,x2的算法.它可以编写出以下C++程序: #include <iostream> #include <cmath> //由于程序要用到数学函数sqrt,故应包含头文件cmath using namespace std; int main( ) { float a,b,c,x1,x2; cin>>a>>b>>
-
Java流程控制顺序结构原理解析
这篇文章主要介绍了Java流程控制顺序结构原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 流程控制的概念 在一个程序执行的过程中,各条语句的执行顺序对程序的结果是有直接影响的.也就是说,程序的流程对运行结果有直接的影响.所以,我们必须清楚每条语句的执行流程.而且,很多时候我们要通过控制语句的执行顺序来实现我们要完成的功能. 流程控制之顺序结构 根据代码的编写顺序,从上往下,依次执行. 顺序结构之流程图 需求 举例说明顺序结构的执行
-
浅析Android文件存储
一.内部存储 内部存储,位于data/data/包名/路径下 是否需要用户权限:否 是否能被其他应用访问:否 卸载应用数据是否被删除:是 内部存储控件不需要用户权限,这意味着我们不需要用户去授权下面的权限: android.permission.WRITE_EXTERNAL_STORAGE android.permission.READ_EXTERNAL_STORAGE 对于设备中每一个安装的 App,系统都会在 data/data 目录下以应用程序包名自动创建与之对应的文件夹,可以直接读写该目
-
Java流程控制之顺序结构
目录 1.关于顺序结构 2.顺序结构简单图示 3.示例助解 Java中的流程控制语句可以这样分类:顺序结构,选择结构,循环结构. 1.关于顺序结构 JAVA的基本结构就是顺序结构,除非特别指明,否则就按照顺序一句一句执行. 语句与语句之间,框与框之间是按从上到下的顺序进行的,它是由若干个依次执行的处理步骤组成的. 它是任何一个算法都离不开的一种基本算法结构. 2.顺序结构简单图示 顺序结构在程序流程图中的体现就是用流程线将程序框自上而地连接起来,按顺序执行算法步骤. 如图: 3.示例助解 pub