Oracle和MySQL的高可用方案对比分析
关于Oracle和MySQL的高可用方案,其实一直想要总结了,就会分为几个系列来简单说说。通过这样的对比,会对两种数据库架构设计上的细节差异有一个基本的认识。Oracle有一套很成熟的解决方案。用我在OOW上的ppt来看,是MAA的方案,今年是这个方案的16周年了。

而MySQL因为开源的特点,社区里推出了更多的解决方案,个人的见解,InnoDB Cluster会是MySQL以后的高可用方案标配。
而目前来看,MGR固然不错,MySQL Cluster方案也有,PXC,Galera等方案,个人还是更倾向于MHA.
所以本文会分为几个部分来解读,先拿RAC和MHA来做一个基本的对比。
Oracle的解决方案在阿里快速发展时期支撑起了核心业务的需求。大概是这样的架构体系,看起来很庞大。里面的RAC算是一个贵族,用昂贵的商业存储,网络带宽要求极高,前端大量的小机业务还有不菲的licence费用。非常典型的IOE的经典架构。
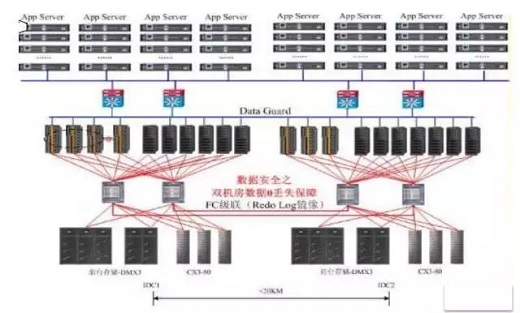
如果要考虑异地容灾,那么资源配置要double,预算翻番。
MySQL的架构方案相对来说更加平民化,普通的pc就可以,但是数量级要高,做业务拆分,水平拆分就能够横向扩展出非常多的节点,很多大互联网公司的MySQL集群规模都是几百几百的规模,上千都不稀奇。如此之多的服务资源,发生故障的概率还是有的,保证业务服务的可持续性访问,是技术方案的关键。如果按照MHA的架构,基本上就是MHA Manager节点来负责整个集群的状态,好比一个居委会大妈,对住户的大大小小的事情都了如指掌包打听。
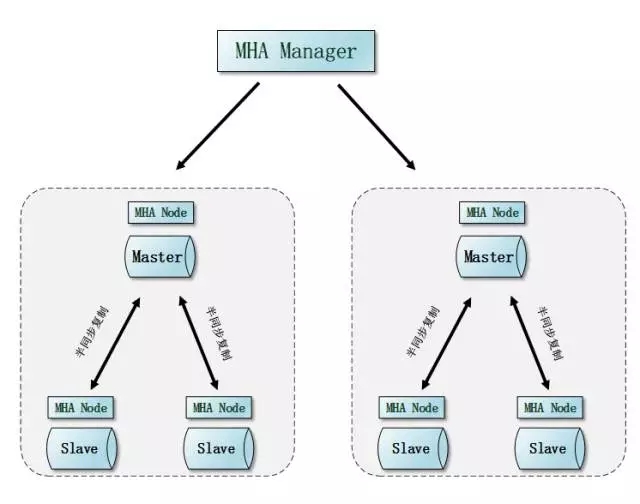
当然上面的说法过于笼统,我们从一些细节入手。比如先来说说网络的事情。
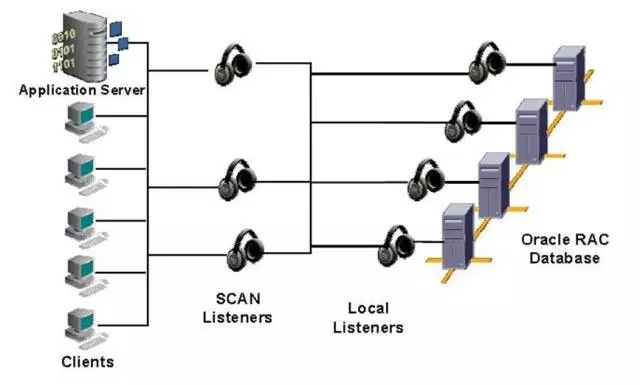
Oracle对于网络的要求还是很严格的,一般都是要2块物理网卡,每台服务器需要至少3个IP, Public IP,private IP,VIP,除了共享存储,至少需要2个计算节点。
private IP是节点间互信的,Public IP和VIP在一个网段,简单来说,VIP是对外的,是public IP所在网络的漂移IP,在10g里面都是通过VIP来做负载均衡的,11g开始有了scan-IP,原来的VIP还是保留,所以Oracle里面的网络配置要求还是很高的。抛开共享存储,搭建的核心就是网络配置了,网络通则通。
scan-IP还可以继续扩展,最多支持3个scan-ip,如下图所示
当然网络层面不只是这些,这方面的亮点Oracle就很专业了。我们有必要了解下TAF,在我的书中《Oracle DBA工作笔记》中,我这样写道:
TAF(Transparent Application Failover)是Oracle中对应用透明的故障转移,在RAC环境中使用尤其广泛。在RAC中Load Balance这块确实做了很大的改进,从10g版本开始的多个VIP地址的Load Balance,到11g版本中的SCAN,做了很大的简化。
而在Failover的实现中,还是有一定的使用限定,比如11g中默认的SCAN-IP的实现其实默认没有Failover的选项,如果两个节点中的其中一个节点挂了,那么原有的连接中继续查询就会提示session已经断开,需要重新连接。客户端TAF主要会讨论Failover Method和Failover Type的一些简单内容。
(1)Failover Method
Failover Method的主要思路就是换取故障转移时间,或者换取资源来实现。
可以这样来理解,假设我们存在两个节点,如果某个session连接到了节点2,然而节点2突然挂了,为了更快处理Failover这种情况,Failover Method有preconnect和basic两种。
— preconnect这种预连接方式还是会占用较多的资源使用,在各个节点上会预先占用一部分额外的资源,在切换时会相对更加平滑,速度更快。
— basic这种方式,则在发生Failover时,再去切换对应的资源,中间会有一些卡顿,但是对于资源的消耗相对来说要小很多。
简单来说,basic方式会在故障发生时才去判断,而preconnect则是未雨绸缪;从实际的应用来说,basic这种方式更加通用,也是默认的故障转移方式。
(2)Failover Type
Failover Type实现更加丰富而且灵活,非常强大。这个时候控制粒度可以针对用户SQL的执行情况进行控制,有select和session两种;通过一个小例子说明一下。
比如,我们有个很大的查询在节点2上进行,结果节点2突然挂了,对于正在执行的查询,比如说有10 000条数据,结果刚好故障发生的时候查出了8 000条,那么剩下的2 000该怎么处理。
第一种方式就是使用select;即会完成故障切换,继续把剩下的2 000条记录返回,当然中间会有一些上下文环境的切换,对于用户是透明的。
第二种方式是session;即直接断开连接,要求重新查询。
在10g版本中借助于VIP的配置达到Load Balance+Failover的配置如下:
racdb= (DESCRIPTION = (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521)) (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521)) (LOAD_BALANCE = yes) (FAILOVER = ON) (CONNECT_DATA = (SERVER= DEDICATED) (SERVICE_NAME = racdb) (FAILOVER_MODE = (TYPE= SELECT) (METHOD= BASIC) (RETRIES = 30) (DELAY = 5)))) 如果11g的SCAN-IP也想进一步扩展Failover,同样也需要设置failover_mode和对应的类型。 RACDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = RACDB) ) )
从这个角度来看Oracle的方案真是精细。再来看看MySQL的方案。
分布式的方案,让MySQL看起来像一把瑞士牛刀,对于网络层面的要求,几乎可以说MySQL没有什么要求,申请一主一从,那么就只需要4个IP即可(主,从,VIP,MHA_Manager(考虑一个manager节点)),一主两从是5个。

这一点上MySQL原生并不支持所谓的负载均衡,可以通过前端的业务来分流,比如使用中间件proxy,或者持续的拆分,达到一定的粒度后,通过架构设计的方式来满足需求。因为基于逻辑的复制,很容易扩展,一主多从都是很常见的,代价也不高,延迟不能说没有,只是很低,能够适应绝大部分的互联网业务需求。
而说到触发MHA切换的条件,从网络层面来看,如下的红点都是潜在的隐患,有的是网络的中断,有的是网络的延迟,发生故障的时候,保数据还是保性能稳定,都可以基于自己的需求来定制。从这一点上来说,丢失数据的概率是有的。绝对不是强一致性的无损复制。

整体来看两种方案,RAC是集中共享,除了存储层面的共享外,网络层面的组播其实也会提高节点间通信的成本,所以RAC对于网络的需求很大,如果存在延迟是很危险的,发生了脑裂就很尴尬了。MySQL MHA的方案是分布式的。支持大批量的环境,节点间通信的成本相对来说要低很多。但是从数据架构的角度来说,因为是复制的数据分布方式,所以对于存储尽管不是共享存储,但是对于存储的成本还是高于RAC(不是说存储的价格,是存储的数据量大小).
相关推荐
-
Oracle、MySQL和SqlServe三种数据库分页查询语句的区别介绍
先来定义分页语句将要用到的几个参数: int currentPage ; //当前页 int pageRecord ; //每页显示记录数 以之前的ADDRESSBOOK数据表为例(每页显示10条记录): 一.SqlServe下载 分页语句 String sql = "select top "+pageRecord +" * from addressbook where id not in (select top "+(currentPage-)*pageRecor
-
MySQL与Oracle数据类型对应关系(表格形式)
MySQL与Oracle两种数据库在工作中,都是用的比较多的数据库,由于MySQL与Oracle在数据类型上有部分差异,在我们迁移数据库时,会遇上一定的麻烦,下面介绍MySQL与Oracle数据库数据类型的对应关系. 一.常见数据类型在MySQL与Oracle数据库中的表现形式 说明 mysql oracle 变长字符串 VARCHAR[0-65535] 定义长度默认按字符长度计算,如果是GBK编码的汉字将占用2个字节 VARCHAR2[1-4000] VARCHAR是VARCHAR2的同义词
-

oracle数据库迁移到MySQL的方法总结
前言 之前搭建了一个ExtJS + spring + Oracle 的这样一个报表系统的框架. 因为其他部门的要求, 也需要这个Framework 进行一些特殊的定制. 但是有一个问题是 Oracle 的数据库是需要收费的, 个人使用倒没什么问题, 公司使用的话就会有侵权的问题了. 而MySQL 则是完全免费的. 所以使用 ExtJS + Spring + MySQL 这样的组合应该就没什么问题了. 理论上来说, MySQL 已经被Oracle 收购, 这两者之间的Migrate 应该比较容易
-
Linux下通过python访问MySQL、Oracle、SQL Server数据库的方法
本文档主要描述了Linux下python数据库驱动的安装和配置,用来实现在Linux平台下通过python访问MySQL.Oracle.SQL Server数据库. 其中包括以下几个软件的安装及配置: unixODBC FreeTDS pyodbc cx_Oracle 欢迎转载,请注明作者.出处. 作者:张正 QQ:176036317 如有疑问,欢迎联系. 本文档主要描述了Linux下python数据库驱动的安装和配置,用来实现在Linux平台下通过python访问MySQL.Oracle.SQ
-
mysql数据库迁移至Oracle数据库
本文实例为大家分享了java获取不同路径的方法,供大家参考,具体内容如下 1.使用工具: (1) Navicat Premium (2) PL/SQL Developer 11.0 (3) Oracle SQL Developer 4.0.0.12.84(点击可进入下载页面) 特别说明:最初我用的一直是高版本的SQL Developer,但在数据库移植到大概两分钟的时候,总是报错,而错误信息又不明确.最后换成 Oracle SQL Developer 4.0.0.12.84,才把问题解决掉!如果
-
SQL获取第一条记录的方法(sqlserver、oracle、mysql数据库)
Sqlserver 获取每组中的第一条记录 在日常生活方面,我们经常需要记录一些操作,类似于日志的操作,最后的记录才是有效数据,而且可能它们属于不同的方面.功能下面,从数据库的术语来说,就是查找出每组中的一条数据.下面我们要实现的就是在sqlserver中实现从每组中取出第一条数据. 例子 我们要从上面获得的有效数据为: 对应的sql语句如下所示: select * from t1 t where id = (select top 1 id from t1 where grp = t.grp o
-
c#几种数据库的大数据批量插入(SqlServer、Oracle、SQLite和MySql)
在之前只知道SqlServer支持数据批量插入,殊不知道Oracle.SQLite和MySql也是支持的,不过Oracle需要使用Orace.DataAccess驱动,今天就贴出几种数据库的批量插入解决方法. 首先说一下,IProvider里有一个用于实现批量插入的插件服务接口IBatcherProvider,此接口在前一篇文章中已经提到过了. /// <summary> /// 提供数据批量处理的方法. /// </summary> public interface IBatch
-
Oracle和MySQL的高可用方案对比分析
关于Oracle和MySQL的高可用方案,其实一直想要总结了,就会分为几个系列来简单说说.通过这样的对比,会对两种数据库架构设计上的细节差异有一个基本的认识.Oracle有一套很成熟的解决方案.用我在OOW上的ppt来看,是MAA的方案,今年是这个方案的16周年了. 而MySQL因为开源的特点,社区里推出了更多的解决方案,个人的见解,InnoDB Cluster会是MySQL以后的高可用方案标配. 而目前来看,MGR固然不错,MySQL Cluster方案也有,PXC,Galera等方案,个人还
-
MySQL数据库的高可用方案总结
高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.虽然互联网服务号称7*24小时不间断服务,但多多少少有一些时候服务不可用,比如某些时候网页打不开,百度不能搜索或者无法发微博,发微信等.一般而言,衡量高可用做到什么程度可以通过一年内服务不可用时间作为参考,要做到3个9的可用性,一年内只能累计有8个小时不可服务,而如果要做到5个9的可用性,则一年内只能累计5分钟服务中断.所以虽说每个公司都说自己的服务是7*24不间断的,但实际上能做到5个9的屈指可数,甚至根本做不到
-
MySQL下高可用故障转移方案MHA的超级部署教程
MHA介绍 MHA是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库系统的高可用.在宕机的时间内(通常10-30秒内),完成故障切换,部署MHA,可避免主从一致性问题,节约购买新服务器的费用,不影响服务器性能,易安装,不改变现有部署. 还支持在线切换,从当前运行master切换到一个新的master上面,只需要很短的时间(0.5-2秒内),此时仅仅阻塞写操作,并不影响读操作,便于主机硬件维护. 在有高可用,数据一致性要求的系统上,MHA 提供了有用的功能
-
生产环境之Nginx高可用方案实现过程解析
准备工作: 192.168.16.128 192.168.16.129 两台虚拟机.安装好Nginx 安装Nginx 更新yum源文件: rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7
-
MySQL系列之十四 MySQL的高可用实现
一.MHA 对主节点进行监控,可实现自动故障转移至其它从节点:通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库. 1.MHA工作原理 从宕机崩溃的master保存二进制日志事件(binlog events) 识别含有最新更新的slave 应用差异的中继日志(relay log)到其他的slave 应用从
-
Ubuntu搭建Mysql+Keepalived高可用的实现(双主热备)
Mysql5.5双机热备 实现方案 安装两台Mysql 安装Mysql5.5 sudo apt-get update apt-get install aptitude aptitude install mysql-server-5.5 或 sudo apt-cache search mariadb-server apt-get install -y mariadb-server-5.5 卸载 sudo apt-get remove mysql-* dpkg -l |grep ^rc|awk '{
-
MySQL之高可用架构详解
目录 引言 MySQL高可用 一主一备: MySQL主从同步的几种模式: 总结 引言 "高可用"是互联网一个永恒的话题,先避开MySQL不谈,为了保证各种服务的高可用有几种常用的解决方案. 服务冗余:把服务部署多份,当某个节点不可用时,切换到其他节点.服务冗余对于无状态的服务是相对容易的. 服务备份:有些服务是无法同时存在多个运行时的,比如说:Nginx的反向代理,一些集群的leader节点.这时可以存在一个备份服务,处于随时待命状态. 自动切换:服务冗余之后,当某个节点不可用时,要做
-
MySQL之高可用集群部署及故障切换实现
一.MHA 1.概念 2.MHA 的组成 3.MHA 的特点 二.搭建MySQL+MHA 思路和准备工作 1.MHA架构 数据库安装 一主两从 MHA搭建 2.故障模拟 模拟主库失效 备选主库成为主库 原故障主库恢复重新加入到MHA成为从库 3.准备4台安装MySQL虚拟机 MHA高可用集群相关软件包 MHAmanager IP:192.168.221.30 MySQL1 IP:192.168.221.20 MySQL2 IP:192.168.221.100 MySQL3 IP: 192.168
-
MySQL数据库高可用HA实现小结
目录 MySQL数据库高可用HA实现 1. 数据库高可用分析 2.MySQL主从复制的容灾处理 1. 什么是数据库高可用 1.1. 什么是高可用集群 1.2. 高可用集群的衡量标准 1.3. 实现高可用的三种方式 1.4. MySQL数据的高可用实现 1.4.1. 主从方式(⾮对称) 1.4.2. 配置主从服务步骤 Master服务器配置 Slave服务器配置 主库授权 初始化数据 创建复制链路 从库的binlog是否写⼊? 问题:只同步其中三个表 1.4.2.1. GTID的⽅式来进⾏主从复制
-
MySQL Binlog 日志处理工具对比分析
Canal 定位:基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql. 原理: canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议 mysql master收到dump请求,开始推送binary log给slave(也就是canal) canal解析binary log对象(原始为byte流) 整个parser过程大致可分为几步: Connection获取上一次解析成功的位置(如果第一次启动,则获取初