利用NodeJS和PhantomJS抓取网站页面信息以及网站截图
利用PhantomJS做网页截图经济适用,但其API较少,做其他功能就比较吃力了。例如,其自带的Web Server Mongoose最高只能同时支持10个请求,指望他能独立成为一个服务是不怎么实际的。所以这里需要另一个语言来支撑服务,这里选用NodeJS来完成。
安装PhantomJS
首先,去PhantomJS官网下载对应平台的版本,或者下载源代码自行编译。然后将PhantomJS配置进环境变量,输入
$ phantomjs
如果有反应,那么就可以进行下一步了。
利用PhantomJS进行简单截图
var webpage = require('webpage') , page = webpage.create(); page.viewportSize = { width: 1024, height: 800 }; page.clipRect = { top: 0, left: 0, width: 1024, height: 800 }; page.settings = { javascriptEnabled: false, loadImages: true, userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0' }; page.open('http://www.baidu.com', function (status) { var data; if (status === 'fail') { console.log('open page fail!'); } else { page.render('./snapshot/test.png'); } // release the memory page.close(); });
这里我们设置了窗口大小为1024 * 800:
page.viewportSize = { width: 1024, height: 800 };
截取从(0, 0)为起点的1024 * 800大小的图像:
page.clipRect = { top: 0, left: 0, width: 1024, height: 800 };
禁止Javascript,允许图片载入,并将userAgent改为"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0":
page.settings = { javascriptEnabled: false, loadImages: true, userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/19.0'};
然后利用page.open打开页面,最后截图输出到./snapshot/test.png中:
page.render('./snapshot/test.png') ;
NodeJS与PhantomJS通讯
我们先来看看PhantomJS能做什么通讯。
例如:
phantomjs snapshot.js http://www.baidu.com
命令行传参只能在PhantomJS开启时进行传参,在运行过程中就无能为力了。
标准输出能从PhantomJS向NodeJS输出数据,但却没法从NodeJS传数据给PhantomJS。
不过测试中,标准输出是这几种方式传输最快的,在大量数据传输中应当考虑。
PhantomJS向NodeJS服务发出HTTP请求,然后NodeJS返回相应的数据。
这种方式很简单,但是请求只能由PhantomJS发出。
值得注意的是PhantomJS 1.9.0支持Websocket了,不过可惜是hixie-76 Websocket,不过毕竟还是提供了一种NodeJS主动向PhantomJS通讯的方案了。
测试中,我们发现PhantomJS连上本地的Websocket服务居然需要1秒左右,暂时不考虑这种方法吧。
phantomjs-node成功将PhantomJS作为NodeJS的一个模块来使用,但我们看看作者的原理解释:
I will answer that question with a question. How do you communicate with a process that doesn't support shared memory, sockets, FIFOs, or standard input?
Well, there's one thing PhantomJS does support, and that's opening webpages. In fact, it's really good at opening web pages. So we communicate with PhantomJS by spinning up an instance of ExpressJS, opening Phantom in a subprocess, and pointing it at a special webpage that turns socket.io messages into alert()calls. Those alert() calls are picked up by Phantom and there you go!
The communication itself happens via James Halliday's fantastic dnode library, which fortunately works well enough when combined with browserify to run straight out of PhantomJS's pidgin Javascript environment.
实际上phantomjs-node使用的也是HTTP或者Websocket来进行通讯,不过其依赖庞大,我们只想做一个简单的东西,暂时还是不考虑这个东东吧。
设计图
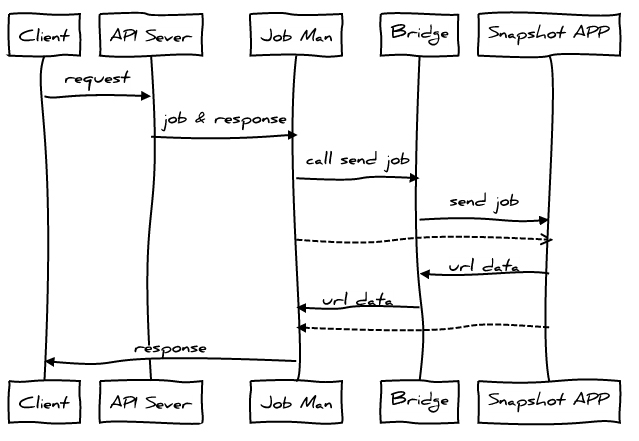
让我们开始吧
我们在第一版中选用HTTP进行实现。
首先利用cluster进行简单的进程守护(index.js):
module.exports = (function () {
"use strict"
var cluster = require('cluster')
, fs = require('fs');
if(!fs.existsSync('./snapshot')) {
fs.mkdirSync('./snapshot');
}
if (cluster.isMaster) {
cluster.fork();
cluster.on('exit', function (worker) {
console.log('Worker' + worker.id + ' died :(');
process.nextTick(function () {
cluster.fork();
});
})
} else {
require('./extract.js');
}
})();
然后利用connect做我们的对外API(extract.js):
module.exports = (function () {
"use strict"
var connect = require('connect')
, fs = require('fs')
, spawn = require('child_process').spawn
, jobMan = require('./lib/jobMan.js')
, bridge = require('./lib/bridge.js')
, pkg = JSON.parse(fs.readFileSync('./package.json'));
var app = connect()
.use(connect.logger('dev'))
.use('/snapshot', connect.static(__dirname + '/snapshot', { maxAge: pkg.maxAge }))
.use(connect.bodyParser())
.use('/bridge', bridge)
.use('/api', function (req, res, next) {
if (req.method !== "POST" || !req.body.campaignId) return next();
if (!req.body.urls || !req.body.urls.length) return jobMan.watch(req.body.campaignId, req, res, next);
var campaignId = req.body.campaignId
, imagesPath = './snapshot/' + campaignId + '/'
, urls = []
, url
, imagePath;
function _deal(id, url, imagePath) {
// just push into urls list
urls.push({
id: id,
url: url,
imagePath: imagePath
});
}
for (var i = req.body.urls.length; i--;) {
url = req.body.urls[i];
imagePath = imagesPath + i + '.png';
_deal(i, url, imagePath);
}
jobMan.register(campaignId, urls, req, res, next);
var snapshot = spawn('phantomjs', ['snapshot.js', campaignId]);
snapshot.stdout.on('data', function (data) {
console.log('stdout: ' + data);
});
snapshot.stderr.on('data', function (data) {
console.log('stderr: ' + data);
});
snapshot.on('close', function (code) {
console.log('snapshot exited with code ' + code);
});
})
.use(connect.static(__dirname + '/html', { maxAge: pkg.maxAge }))
.listen(pkg.port, function () { console.log('listen: ' + 'http://localhost:' + pkg.port); });
})();
这里我们引用了两个模块bridge和jobMan。
其中bridge是HTTP通讯桥梁,jobMan是工作管理器。我们通过campaignId来对应一个job,然后将job和response委托给jobMan管理。然后启动PhantomJS进行处理。
通讯桥梁负责接受或者返回job的相关信息,并交给jobMan(bridge.js):
module.exports = (function () {
"use strict"
var jobMan = require('./jobMan.js')
, fs = require('fs')
, pkg = JSON.parse(fs.readFileSync('./package.json'));
return function (req, res, next) {
if (req.headers.secret !== pkg.secret) return next();
// Snapshot APP can post url information
if (req.method === "POST") {
var body = JSON.parse(JSON.stringify(req.body));
jobMan.fire(body);
res.end('');
// Snapshot APP can get the urls should extract
} else {
var urls = jobMan.getUrls(req.url.match(/campaignId=([^&]*)(\s|&|$)/)[1]);
res.writeHead(200, {'Content-Type': 'application/json'});
res.statuCode = 200;
res.end(JSON.stringify({ urls: urls }));
}
};
})();
如果request method为POST,则我们认为PhantomJS正在给我们推送job的相关信息。而为GET时,则认为其要获取job的信息。
jobMan负责管理job,并发送目前得到的job信息通过response返回给client(jobMan.js):
module.exports = (function () {
"use strict"
var fs = require('fs')
, fetch = require('./fetch.js')
, _jobs = {};
function _send(campaignId){
var job = _jobs[campaignId];
if (!job) return;
if (job.waiting) {
job.waiting = false;
clearTimeout(job.timeout);
var finished = (job.urlsNum === job.finishNum)
, data = {
campaignId: campaignId,
urls: job.urls,
finished: finished
};
job.urls = [];
var res = job.res;
if (finished) {
_jobs[campaignId] = null;
delete _jobs[campaignId]
}
res.writeHead(200, {'Content-Type': 'application/json'});
res.statuCode = 200;
res.end(JSON.stringify(data));
}
}
function register(campaignId, urls, req, res, next) {
_jobs[campaignId] = {
urlsNum: urls.length,
finishNum: 0,
urls: [],
cacheUrls: urls,
res: null,
waiting: false,
timeout: null
};
watch(campaignId, req, res, next);
}
function watch(campaignId, req, res, next) {
_jobs[campaignId].res = res;
// 20s timeout
_jobs[campaignId].timeout = setTimeout(function () {
_send(campaignId);
}, 20000);
}
function fire(opts) {
var campaignId = opts.campaignId
, job = _jobs[campaignId]
, fetchObj = fetch(opts.html);
if (job) {
if (+opts.status && fetchObj.title) {
job.urls.push({
id: opts.id,
url: opts.url,
image: opts.image,
title: fetchObj.title,
description: fetchObj.description,
status: +opts.status
});
} else {
job.urls.push({
id: opts.id,
url: opts.url,
status: +opts.status
});
}
if (!job.waiting) {
job.waiting = true;
setTimeout(function () {
_send(campaignId);
}, 500);
}
job.finishNum ++;
} else {
console.log('job can not found!');
}
}
function getUrls(campaignId) {
var job = _jobs[campaignId];
if (job) return job.cacheUrls;
}
return {
register: register,
watch: watch,
fire: fire,
getUrls: getUrls
};
})();
这里我们用到fetch对html进行抓取其title和description,fetch实现比较简单(fetch.js):
module.exports = (function () {
"use strict"
return function (html) {
if (!html) return { title: false, description: false };
var title = html.match(/\<title\>(.*?)\<\/title\>/)
, meta = html.match(/\<meta\s(.*?)\/?\>/g)
, description;
if (meta) {
for (var i = meta.length; i--;) {
if(meta[i].indexOf('name="description"') > -1 || meta[i].indexOf('name="Description"') > -1){
description = meta[i].match(/content\=\"(.*?)\"/)[1];
}
}
}
(title && title[1] !== '') ? (title = title[1]) : (title = 'No Title');
description || (description = 'No Description');
return {
title: title,
description: description
};
};
})();
最后是PhantomJS运行的源代码,其启动后通过HTTP向bridge获取job信息,然后每完成job的其中一个url就通过HTTP返回给bridge(snapshot.js):
var webpage = require('webpage')
, args = require('system').args
, fs = require('fs')
, campaignId = args[1]
, pkg = JSON.parse(fs.read('./package.json'));
function snapshot(id, url, imagePath) {
var page = webpage.create()
, send
, begin
, save
, end;
page.viewportSize = { width: 1024, height: 800 };
page.clipRect = { top: 0, left: 0, width: 1024, height: 800 };
page.settings = {
javascriptEnabled: false,
loadImages: true,
userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.31 (KHTML, like Gecko) PhantomJS/1.9.0'
};
page.open(url, function (status) {
var data;
if (status === 'fail') {
data = [
'campaignId=',
campaignId,
'&url=',
encodeURIComponent(url),
'&id=',
id,
'&status=',
].join('');
postPage.open('http://localhost:' + pkg.port + '/bridge', 'POST', data, function () {});
} else {
page.render(imagePath);
var html = page.content;
// callback NodeJS
data = [
'campaignId=',
campaignId,
'&html=',
encodeURIComponent(html),
'&url=',
encodeURIComponent(url),
'&image=',
encodeURIComponent(imagePath),
'&id=',
id,
'&status=',
].join('');
postMan.post(data);
}
// release the memory
page.close();
});
}
var postMan = {
postPage: null,
posting: false,
datas: [],
len: 0,
currentNum: 0,
init: function (snapshot) {
var postPage = webpage.create();
postPage.customHeaders = {
'secret': pkg.secret
};
postPage.open('http://localhost:' + pkg.port + '/bridge?campaignId=' + campaignId, function () {
var urls = JSON.parse(postPage.plainText).urls
, url;
this.len = urls.length;
if (this.len) {
for (var i = this.len; i--;) {
url = urls[i];
snapshot(url.id, url.url, url.imagePath);
}
}
});
this.postPage = postPage;
},
post: function (data) {
this.datas.push(data);
if (!this.posting) {
this.posting = true;
this.fire();
}
},
fire: function () {
if (this.datas.length) {
var data = this.datas.shift()
, that = this;
this.postPage.open('http://localhost:' + pkg.port + '/bridge', 'POST', data, function () {
that.fire();
// kill child process
setTimeout(function () {
if (++this.currentNum === this.len) {
that.postPage.close();
phantom.exit();
}
}, 500);
});
} else {
this.posting = false;
}
}
};
postMan.init(snapshot);
效果
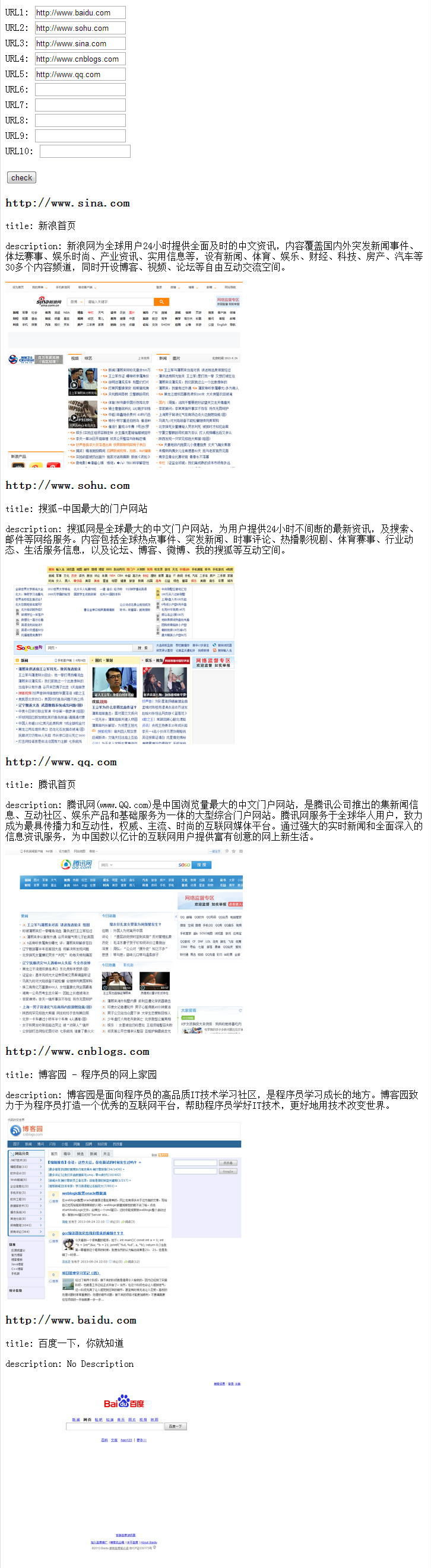
相关推荐
-

THINKPHP+JS实现缩放图片式截图的实现
作者:杨鑫奇 原始链接:http://www.cnblogs.com/scotoma/archive/2010/03/05/1679477.html 今晚TP论坛的一位大哥加我了,说也遇到这个方面的问题,呵呵!想想其实很多东西都遇到了,是不是应该分享出来呢?其实自己的很多东西都是别人那来的,取之于网络用之于网络!只有大家多分享,才能够提高! 实现方式 上传图片 -- 保存并显示图片 -- JS获取缩略图参数 -- 提交位置参数 -- 图片缩放保存类处理图片 -- 保存截取的图片--更新数据库 -
-
javascript在网页中实现读取剪贴板粘贴截图功能
见某网站的输入框支持截屏粘贴的功能,觉得有点意思,于是将代码扒出来分享下. 可惜,目前仅有高版本的 Chrome 浏览器支持这样直接粘贴,其他浏览器目前为止还无法粘贴( IE11没测试过 ),当然这种增强型的用户体验功能有总比没有好. 输入框的结构代码: 复制代码 代码如下: <input type="text" id="testInput" /> 为输入框绑定粘贴事件: 复制代码 代码如下: var input = document.getElemen
-
JavaScript实现网页截图功能
使用JavaScript截图,这里我要推荐两款开源组件:一个是Canvas2Image,它可以将Canvas绘图编程PNG/JPEG/BMP的图像:但是光有它还不够,我们需要给任意DOM(至少是绝大部分)截图,这就需要html2canvas,它可以将DOM对象转换成一个canvas对象.两者的功能结合起来,就可以把页面上的DOM截图成PNG或者JPEG图像了,很酷. Canvas2Image 它的原理是利用了HTML5的canvas对象提供了toDataURL()的API: 复制代码 代码如下:
-
JS实现div模块的截图并下载功能
当需要实现html页面部分模块截图并具有保存图片功能时,前台直接生成截图并下载会方便的多.多的不说,直接看代码 首先我们需要引入2个js文件: <script type="text/javascript" src="js/html2canvas.js"></script> <script type="text/javascript" src="js/jquery-1.12.3.min.js">
-
分享js粘帖屏幕截图到web页面插件screenshot-paste
在很多场合下,我们可能有这样的需求:提供个屏幕截图上传到系统,作为一个凭证.传统的操作方式是:屏幕截图,保存文件到本地,在web页面上选择本地文件并上传,这里至少需要三步.有没有可能直接将截图粘帖到web页面上,然后上传?答案是:可以的.这就是本文要介绍的内容了. 由于我的项目有上传屏幕截图这样的需求,为了用户体验更佳,减少操作步骤,我在网上搜了一遍之后,找到了一些眉目.为了便于复用和共享,我又对该功能做了一些封装,于是便有了这个插件 screenshot-paste.运行效果如下图: 插件调用
-
JavaScript+html5 canvas实现本地截图教程
最近有时间了解了下html5的各API,发现新浪微博的头像设置是使用canvas实现截图的,加之前段时间了解了下html5的File API使用File API 之FileReader实现文件上传<JavaScript File API文件上传预览>,更加觉得html5好玩了,想着也试试写写这功能权当学习canvas吧. 下面奉上我自己写的一个demo,代码写得比较少,很多细节不会处理.如果有不得当的地方恳请指教,谢谢啦 ^_^ ^_^ 功能实现步奏: 一.获取文件,读取文件并生成url 二.
-
js+HTML5实现视频截图的方法
本文实例讲述了js+HTML5实现视频截图的方法.分享给大家供大家参考.具体如下: 1. HTML部分: <video id="video" controls="controls"> <source src=".mp4" /> </video> <button id="capture">Capture</button> <div id="output&
-
JS图片自动轮换效果实现思路附截图
今天不在状态,安静五一快到了,俺就特想玩了.好了,天色已晚,闲话不多说,看下用javaScript 实现的图片自动轮换效果,先看图片 下面是具体的代码,还是比较简单的. 复制代码 代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html x
-
利用NodeJS和PhantomJS抓取网站页面信息以及网站截图
利用PhantomJS做网页截图经济适用,但其API较少,做其他功能就比较吃力了.例如,其自带的Web Server Mongoose最高只能同时支持10个请求,指望他能独立成为一个服务是不怎么实际的.所以这里需要另一个语言来支撑服务,这里选用NodeJS来完成. 安装PhantomJS 首先,去PhantomJS官网下载对应平台的版本,或者下载源代码自行编译.然后将PhantomJS配置进环境变量,输入 $ phantomjs 如果有反应,那么就可以进行下一步了. 利用PhantomJS进行简
-
Nodejs抓取html页面内容(推荐)
废话不多说,直接给大家贴node.js抓取html页面内容的核心代码了. 具体代码如下所示: var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option,
-
利用curl抓取远程页面内容的示例代码
最基本的操作如下 复制代码 代码如下: $curlPost = 'a=1&b=2';//模拟POST数据$ch = curl_init();curl_setopt($ch, CURLOPT_HTTPHEADER, array('X-FORWARDED-FOR:0.0.0.0', 'CLIENT-IP:0.0.0.0')); //构造IPcurl_setopt($ch, CURLOPT_REFERER, "http://www.jb51.net/"); //构造来路 cur
-
Nodejs实现爬虫抓取数据实例解析
开始之前请先确保自己安装了Node.js环境,如果没有安装,大家可以到我们下载安装. 1.在项目文件夹安装两个必须的依赖包 npm install superagent --save-dev superagent 是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于nodejs环境下 npm install cheerio --save-dev cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速.灵活.实施的jQuery核心
-
python+selenium+PhantomJS抓取网页动态加载内容
环境搭建 准备工具:pyton3.5,selenium,phantomjs 我的电脑里面已经装好了python3.5 安装Selenium pip3 install selenium 安装Phantomjs 按照系统环境下载phantomjs,下载完成之后,将phantomjs.exe解压到python的script文件夹下 使用selenium+phantomjs实现简单爬虫 from selenium import webdriver driver = webdriver.PhantomJS
-
Winform实现抓取web页面内容的方法
本文以一个非常简单的实例讲述了Winform实现抓取web页面内容的方法,代码简洁易懂,非常实用!分享给大家供大家参考. 具体实现代码如下: WebRequest request = WebRequest.Create("http://1.bjapp.sinaapp.com/play.php?a=" + PageUrl); WebResponse response = request.GetResponse(); Stream resStream = response.GetRespo
-
解决Python3 抓取微信账单信息问题
这段时间有个朋友想导出微信里面的账单信息,后来发现微信的反爬虫还是很厉害的,花了点时间去分析. 一.采用传统模拟http抓取 抓取的主要URL:https://wx.tenpay.com/userroll/userrolllist,其中后面带上三个参数,具体参数见代码,其中exportkey这参数是会过期的,userroll_encryption和userroll_pass_ticket 这两个参数需要从cookie中获得,应该是作为获取数据的标识,通过抓包也看不出端倪,应该是微信程序内部生成的
-
Python爬虫实现抓取京东店铺信息及下载图片功能示例
本文实例讲述了Python爬虫实现抓取京东店铺信息及下载图片功能.分享给大家供大家参考,具体如下: 这个是抓取信息的 from bs4 import BeautifulSoup import requests url = 'https://list.tmall.com/search_product.htm?q=%CB%AE%BA%F8+%C9%D5%CB%AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal
-
基于python3抓取pinpoint应用信息入库
这篇文章主要介绍了基于python3抓取pinpoint应用信息入库,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pinpoint是用Java编写的大型分布式系统的APM(应用程序性能管理)工具. 受Dapper的启发,Pinpoint提供了一种解决方案,通过在分布式应用程序中跟踪事务来帮助分析系统的整体结构以及它们中的组件之间的相互关系. pinpoint api: /applications.pinpoint 获取applications
-
Node.JS利用PhantomJs抓取网页入门教程
前言 当想用 nodejs 抓取一些网页 , 我第一反应想到的就是使用 http 模块 , 比如抓取百度首页: var http = require('http'); var req = http.request('http://www.baidu.com/', function (res) { res.setEncoding('utf8'); res.on('data', function (chunk) { //响应内容 console.log(chunk) }); }); req.end(