SQLServer性能优化--间接实现函数索引或者Hash索引
SQLServer中没有函数索引,在某些场景下查询的时候要根据字段的某一部分做查询或者经过某种计算之后做查询,如果使用函数或者其他方式作用在字段上之后,就会限制到索引的使用,不过我们可以间接地实现类似于函数索引的功能。
另外一个就是如果查询字段较大或者字段较多的时候,所建立的索引就显得有点笨重,效率也不高,就需要考虑使用一个较小的"替代性"字段做等价替换,类似于Hash索引,
本文粗浅地介绍两种上述两种问题的解决方式,仅供参考。
1,在计算列上建索引,实现“函数索引”的功能
SQLServer在建表的时候允许使用计算列,可以借助这个计算列来实现函数索引的功能,这里举例说明一下
Create Table TestFunctionIndex ( id int identity(1,1), val varchar(50), subval as LOWER(SUBSTRING(val,10,4)) persisted --增加一个持久化计算列 ) GO --在持久化计算列上建立索引 create index idx_subvar on TestFunctionIndex(subval) GO --插入10W行测试数据 insert into TestFunctionIndex(val) values (NEWID()) go 100000
在有索引的字段上使用函数之后,是无法使用索引的
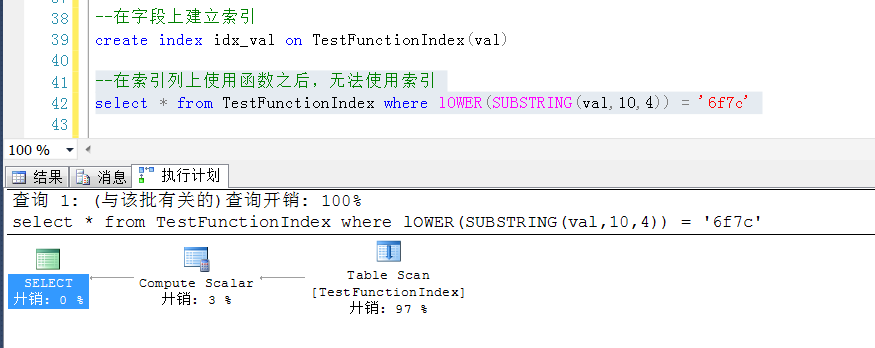
如果直接在计算列上查询,就可以正常地使用到索引了
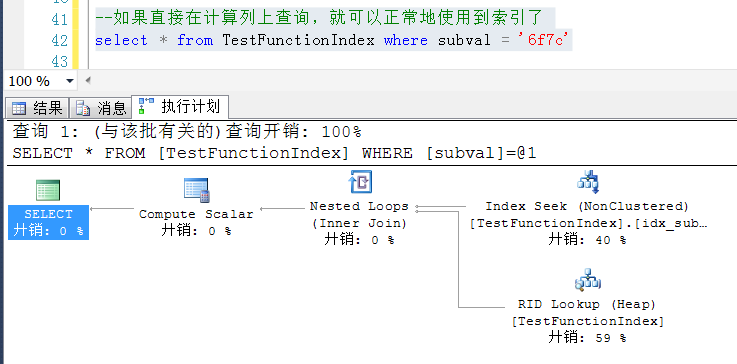
以上通过在计算列上建立一个索引,可以根据计算列上的索引做查找,避免了直接在字段上使用函数或者其他操作,造成即便字段上有索引也用不到的情况
补充:
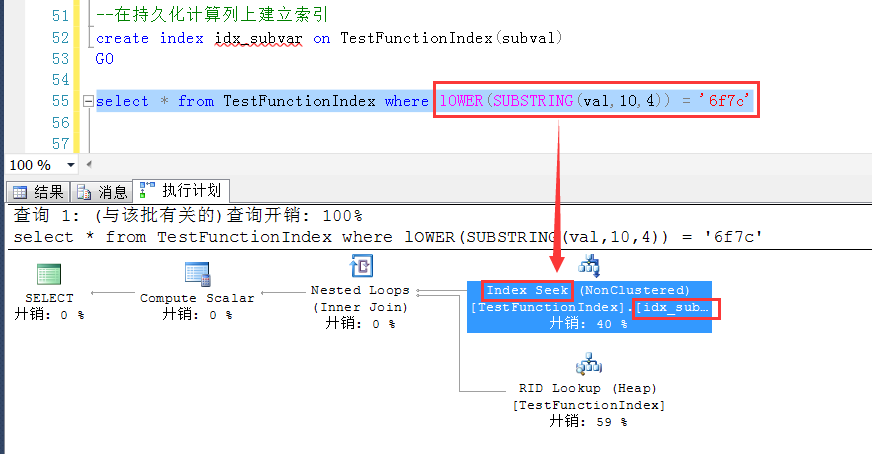
测试中神奇地发现,如果计算列字段上建立了索引,在原始字段上使用函数与计算列的函数一样的时候,可以神奇地使用到计算列上的索引。可见SQLServer在我们没有注意的地方也是下了不少功夫的啊
2,生成较长字段或者多个字段的Hash值替代原始字段做查询或者连接来提升查询效率
开发中遇到另外一种常见的情况是经常使用到的查询条件字段较长,或者是表连接的时候连接条件字段较多,
即便是字段或者查询条件上有索引,但是因为字段较长或者条件较多,此时有可能会影响到查询的效率
这种情况就适当考虑将原始的较长的字段生成一个较小的字段(但是要确保唯一性),或者是讲多个字段生成一个较短的数据类型做替代,以提高查询的效率
举个例子,假如有这么一张表,Name字段是我模拟出来的,Name是一个比较长的字段,又要用来做检索
意思就是查询字段较长,索引代价太大,此时就需要考虑用一种较小的等价字段来替代
下面通过某种方式计算较长字段的Hash值,来做等价替换
模拟生成一下测试数据
Create table testHashColumn
(
id int identity(1,1),
QueryName nvarchar(100),
HashName AS CAST( HASHBYTES('MD2',QueryName) AS UNIQUEIDENTIFIER) persisted
)
GO
create index idx_HashName ON testHashColumn(HashName)
GO
--这里模拟生成一个较长的名字字段
DECLARE @i int = 0
while @i<10000
begin
INSERT INTO testHashColumn (QueryName) VALUES (CONCAT('北京新视点科技文化传媒有限公司',@i))
set @i = @i+1
end
我们知道,Name这个名字是nvarchar(100)的,这个字段做索引不是不可以,如果情况复杂,实际中有可能比这个字段更大,做索引显得太宽了,造成索引空间过大,在效率上有一定程度的影响。
这里就可以考虑在Name这个字段上生成一个“替代”字段(上述HashName AS CAST( HASHBYTES('MD2',QueryName) AS UNIQUEIDENTIFIER) persisted这个计算列),
这个字段首选是要跟实际值一一对应的,另外就是要求“替代”的字段类型要求相对较小,当然方法也有多种,比如生成利用checksum函数生成一个校验值,但是据实际观察checksum生成的校验值是有可能重复的,也就是说两个不同的字符串,生成同一个校验值
比如这样,很容易验证出来这个问题,可以认为是对于不同的字符串,计算之后得到同一个校验和
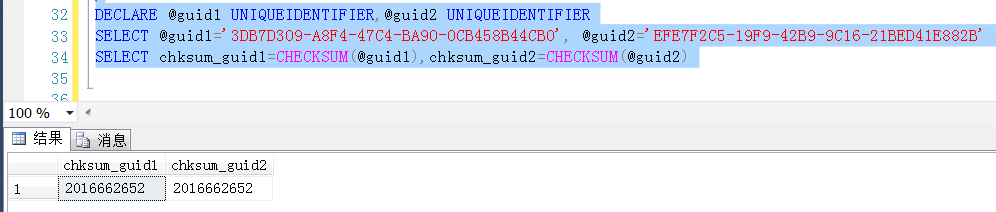
因此在生成“替代”字段的时候,需要考虑计算值的唯一性
这里使用的是HASHBYTES加密函数,对字符串加密,然后对加密之后的数据生成一个UNIQUEIDENTIFIER,重复的概率就小的多的多了
演示这里通过CAST( HASHBYTES('MD2','北京新视点科技文化传媒有限公司999') AS UNIQUEIDENTIFIER)的方式,就可以给这个较长的字段生成一个UNIQUEIDENTIFIER类型的字段,
当然也不一定只有这一种方法,甚至可以做的跟复杂,只要能保证一个唯一的长字段生成的较短的字段也是唯一的就可以达到目的了
参考如下查询,就可以使用HashName计算出来的值与计算列做比较,在一定程度上可以减少检索字段索引的大小,又能达到目的的效果
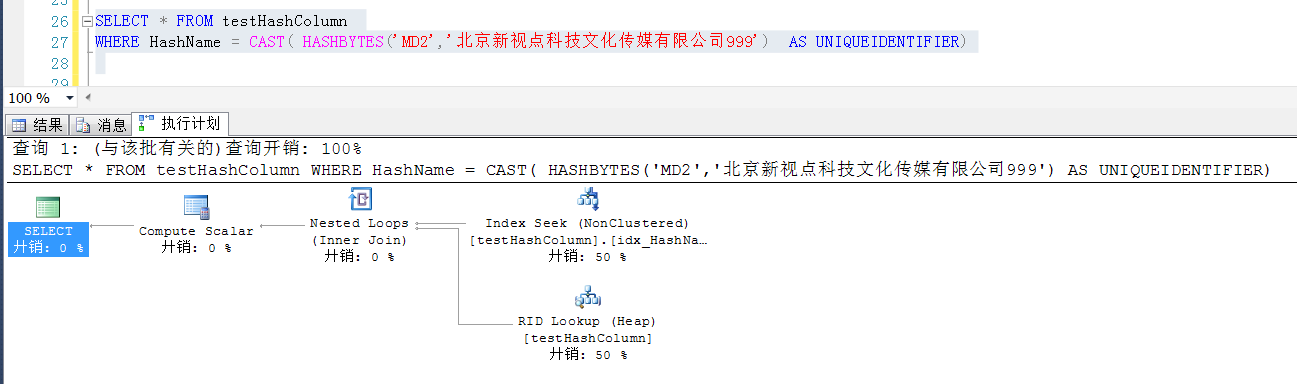
如截图,就可以使用HashName字段上的索引了,同时也避免了在原始的QueryName这个较长的字段上建索引,节约了空间并提高了查询效率
3, 逻辑主键为多个字段的时候,在多了字段上生成一个“替代”性的唯一字段
某些情况下业务需求或者设计也好(比如没有达到第三范式,BC范式,第四范式,甚至是第五范式),在表连接的时候往往会有多个字段
比如这种样子:
SELECT *
FROM TableNameA a
INNER JOIN TableNameB b
ON a.key=b.key
AND a.Type = b.Type
AND a.Status = b.Staus
AND a.CreationTime = b.CreationTime
AND a.***=b.***
where ***
在表关联的时候,连接条件很多,如果是这样子,最好的情况就是建立一个较宽的复合索引,但是这样的话,索引的宽度和体积就变得很大,使用的时候效率也有一定的影响。这种情况就可以考虑在TableNameA 和 TableNameB 上,利用多个连接的字段(Key+Type +Status +CreationTime+***)做了类似于示例2中的一个计算列,在计算列上建立一个索引,然后再表连接的时候就可以用如下的方式替代
SELECT * FROM TableNameA a INNER JOIN TableNameB b ON a.HashValue=b.HashValue WHERE ***
总是,这是一种以空间换时间的思路(冗余存储一个类似于标识符的字段,提高查询效率),在生成“替代”字段的思想有两点,第一要足够的小,第二要原始值生成替代字段的唯一性
总结:SQLServer 中没有函数索引和Hash索引,而某些业务需求或者说是为了性能考虑,又需要类似的功能,通过类似于空间换时间的方法来实现,可以变通地来实现类似于函数索引或者Hash索引的功能,已达到其他数据库中函数索引和Hash索引的效果(虽然原理可能不一样)。需要注意的就是在生成计算列或者说Hash值替代的时候要注意计算方式,确保生成之后的Key值的唯一性。当然实现方式就可以根据需要自行选择了,条条大路通罗马。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-

人工智能自动sql优化工具--SQLTuning for SQL Server
针对这种情况,人工智能自动SQL优化工具应运而生.现在我就向大家介绍这样一款工具:SQLTuning for SQL Server. 1. SQL Tuning 简介 SQL Turning是Quest公司出品的Quest Central软件中的一个工具. QuestCentral(图1)是一款集成化.图形化.跨平台的数据库管理解决方案,可以同时管理Oracle.DB2 和 SQL server 数据库.它包含了如下的多个工具: 数据库管理(DBA) 数据库监控(Monitoring Pack
-
谈谈Tempdb对SQL Server性能优化有何影响
先给大家巩固tempdb的基础知识 简介: tempdb是SQLServer的系统数据库一直都是SQLServer的重要组成部分,用来存储临时对象.可以简单理解tempdb是SQLServer的速写板.应用程序与数据库都可以使用tempdb作为临时的数据存储区.一个实例的所有用户都共享一个Tempdb.很明显,这样的设计不是很好.当多个应用程序的数据库部署在同一台服务器上的时候,应用程序共享tempdb,如果开发人员不注意对Tempdb的使用就会造成这些数据库相互影响从而影响应用程序. 特性:
-
SQLServer 优化SQL语句 in 和not in的替代方案
但是用IN的SQL性能总是比较低的,从SQL执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别: SQL试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询.由此可见用IN的SQL至少多了一个转换的过程.一般的SQL都可以转换成功,但对于含有分组统计等方面的SQL就不能转换了. 推荐在业务密集的SQL当中尽量不采用IN操作符 NOT IN 此操作是强列推荐不使用的,因为它不能应用表的索引.推荐用NOT EXIS
-
SQL SERVER性能优化综述(很好的总结,不要错过哦)第1/3页
一.分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性.可用性.可靠性.安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求.响应时间的需求.硬件的配置等.最好能有各种需求的量化的指标. 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统). 二.设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎
-
SQL Server中的SQL语句优化与效率问题
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhangsan' and tID > 10000 和执行: select * from table1 where tID > 10000 and name='zhangsan' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那
-
SQL Server游标的使用/关闭/释放/优化小结
游标是邪恶的! 在关系数据库中,我们对于查询的思考是面向集合的.而游标打破了这一规则,游标使得我们思考方式变为逐行进行.对于类C的开发人员来着,这样的思考方式会更加舒服. 正常面向集合的思维方式是: 而对于游标来说: 这也是为什么游标是邪恶的,它会使开发人员变懒,懒得去想用面向集合的查询方式实现某些功能. 同样的,在性能上,游标会吃更多的内存,减少可用的并发,占用宽带,锁定资源,当然还有更多的代码量-- 从游标对数据库的读取方式来说,不难看出游标为什么占用更多的资源,打个比方: 当你从ATM取钱
-
win2008 r2 服务器php+mysql+sqlserver2008运行环境配置(从安装、优化、安全等)
win2008 r2 安装 http://www.jb51.net/article/38048.htm iis的安装 http://www.jb51.net/article/86390.htm php的安装注意事项: 下载非安全线程 版本 nts php 5.2.17 http://www.jb51.net/softs/268745.html 其它版本可以到 http://museum.php.net/php5/里面很多经典的老版本. PHP 5.5 (5.5.36) VC11 x64 Non
-
sql语句优化之SQL Server(详细整理)
MS SQL Server查询优化方法 查询速度慢的原因很多,常见如下几种 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 5.网络速度慢 6.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量) 7.锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷) 8.sp_lock,sp_who,活动的用户查看,原因是读写竞争资源. 9.返回了不必要的行和列 10.查询语句不好,
-
SQL Server 2016 查询存储性能优化小结
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释.在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源. 但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变.昨天SQL Serv
-
SQL SERVER 的SQL语句优化方式小结
1.SQL SERVER 2005的性能工具中有SQL Server Profiler和数据库引擎优化顾问,极好的东东,必须熟练使用. 2.查询SQL语句时打开"显示估计的执行计划",分析每个步骤的情况 3.初级做法,在CPU占用率高的时候,打开SQL Server Profiler运行,将跑下来的数据存到文件中,然后打开数据库引擎优化顾问调用那个文件进行分析,由SQL SERVER提供索引优化建议.采纳它的INDEX索引优化部分. 4.但上面的做法经常不会跑出你所需要的,在最近的优化