理解SQL SERVER中的逻辑读,预读和物理读
SQL SERVER数据存储的形式
在谈到几种不同的读取方式之前,首先要理解SQL SERVER数据存储的方式.SQL SERVER存储的最小单位为页(Page).每一页大小为8k,SQL SERVER对于页的读取是原子性,要么读完一页,要么完全不读,不会有中间状态。而页之间的数据组织结构为B树(请参考我之前的博文).所以SQL SERVER对于逻辑读,预读,和物理读的单位是页.
SQL SERVER一页的总大小为:8K
但是这一页存储的数据会是:8K=8192字节-96字节(页头)-36字节(行偏移)=8060字节
所以每一页用于存储的实际大小为8060字节.
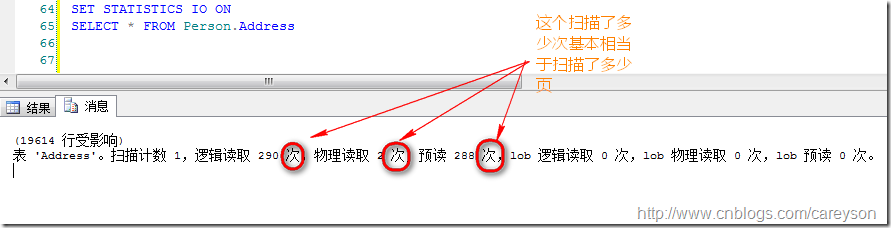
比如上面AdventureWorks中的Person.Address表,通过SSMS看到这个表的数据空间为:
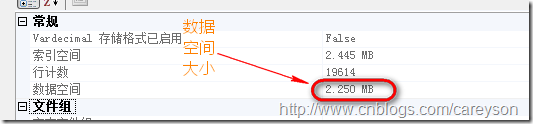
我们可以通过公式大概推算出占用了多少页:2.250*1024*1024/8060(每页的数据容量)≈293 - 表中非数据占用的空间≈290(上图中的逻辑读取数)
SQL SERVER查询语句执行的顺序
SQL SERVER查询执行的步骤如果从微观来看,那将会非常多。这里为了讲述逻辑读等概念,我从比较高的抽象层次来看:
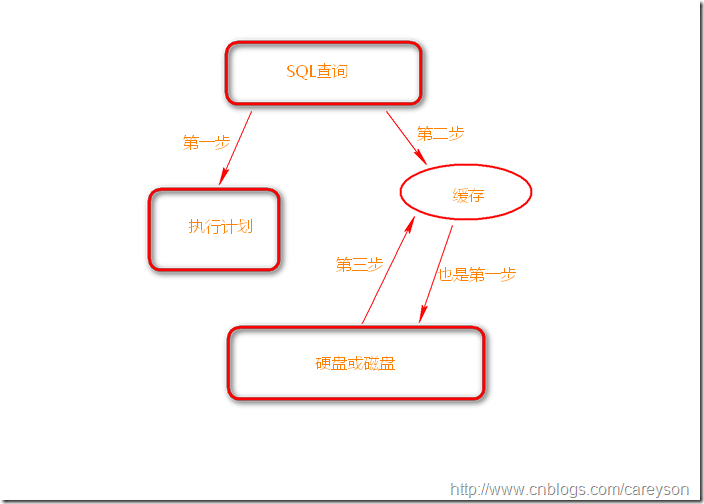
图有些粗糙。
下面我解释一下图。当遇到一个查询语句时,SQL SERVER会走第一步,分别为生成执行计划(占用CPU和内存资源),同步的用估计的数据去磁盘中取得需要取的数据(占用IO资源,这就是预读),注意,两个第一步是并行的,SQL SERVER通过这种方式来提高查询性能.
然后查询计划生成好了以后去缓存读取数据.当发现缓存缺少所需要的数据后让缓存再次去读硬盘(物理读)
最后从缓存中取出所有数据(逻辑读)。
下面我再通过一个简单的例子说明一下:
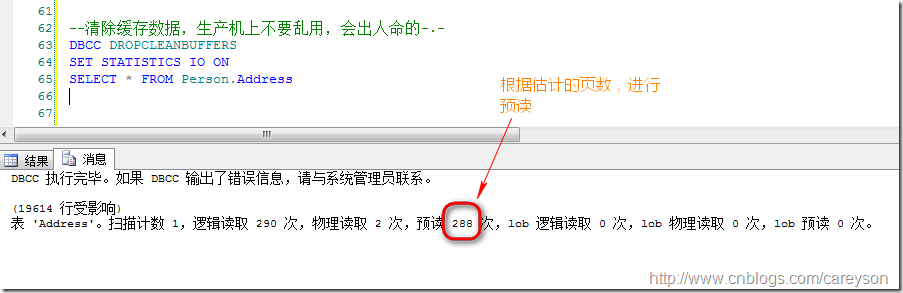
这个估计的页数数据可以通过这个DMV看到:
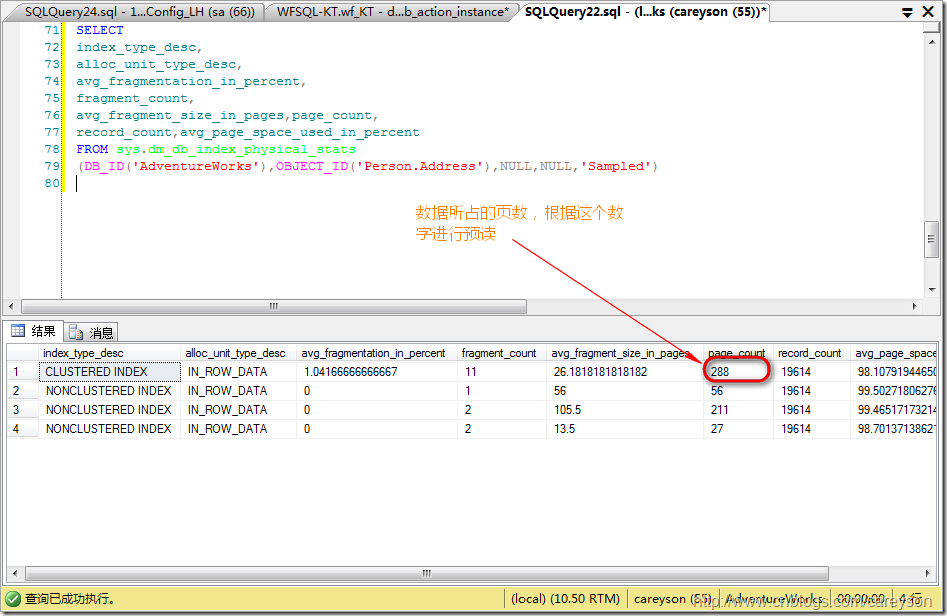
当我们第一次查询完成后,再次进行查询时,所有请求的数据这时已经在缓存中,SQL SERVER这时只要对缓存进行读取就行了,也就是只用进行逻辑读:
相关推荐
-

理解SQL SERVER中的逻辑读,预读和物理读
SQL SERVER数据存储的形式 在谈到几种不同的读取方式之前,首先要理解SQL SERVER数据存储的方式.SQL SERVER存储的最小单位为页(Page).每一页大小为8k,SQL SERVER对于页的读取是原子性,要么读完一页,要么完全不读,不会有中间状态.而页之间的数据组织结构为B树(请参考我之前的博文).所以SQL SERVER对于逻辑读,预读,和物理读的单位是页. SQL SERVER一页的总大小为:8K 但是这一页存储的数据会是:8K=8192字节-96字节(页头)-36字节(
-
SQL Server中的逻辑函数介绍
IIF: 根据布尔表达式计算为 true 还是 false,返回其中一个值. IIF 是一种用于编写 CASE 表达式的快速方法. 它将传递的布尔表达式计算为第一个参数,然后根据计算结果返回其他两个参数之一.也即,如果布尔表达式为 true,则返回 true_value:如果布尔表达式为 false 或未知,则返回 false_value. true_value 和 false_value 可以是任何类型. 语法: IIF ( boolean_expression, true_value, fa
-
理解Sql Server中的聚集索引
说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆....问题就在这里,我们不是学文科,,,不需要去死记硬背,,,我们需要的就是能看到在眼里面的真实东西.....我们都喜欢聚集索引,因为它能够把无序的堆表记录变成有序,还玩起了B树...这样就把复杂度从N降低到了LogMN... 这样的话逻辑读,物理读就下来了. 一:现象 1:无索引的情况 还是老规矩,看个例子感受下,首先我有一个Prod
-
深入理解Sql Server中的表扫描
很久以前我们在写sql的时候,最怕的一件事情就是sql莫名奇妙的超级慢,慢的是撸一管子回来,那个小球还在一直转...这个着急也只有当事人才明白,后来听说有个什么"评估执行计划",后来的后来才明白应该避免表扫描... 一:表扫描 1.现象 "表扫描"听起来很简单,不就是一行一行的扫嘛,你要说"执行计划"的话,我也会玩,为了更可观,我build一个表,再插入三行数据,如下图: 上面的Person我是一个索引都没建,然后where一下,看看表扫描是啥样
-
SQL Server中分区表的用法
目录 一.分区表简介 二.对表分区的理由 三.分区表的操作步骤 第一步.定义分区函数: 第二步.定义分区构架 第三步.定义分区表 四.分区表的分割 五.分区表的合并 一.分区表简介 分区表是SQL Server2005新引入的概念,这个特性在逻辑上将一个表在物理上分为多个部分.(即它允许将一个表存储在不同的物理磁盘里).在SQL Server2005之前,分区表实际上是分布式视图,也就是多个表做union操作. 分区表在逻辑上是一个表,而物理上是多个表.在用户的角度,分区表和普通表是一样的,用户
-
SQL Server中的SQL语句优化与效率问题
很多人不知道SQL语句在SQL SERVER中是如何执行的,他们担心自己所写的SQL语句会被SQL SERVER误解.比如: select * from table1 where name='zhangsan' and tID > 10000 和执行: select * from table1 where tID > 10000 and name='zhangsan' 一些人不知道以上两条语句的执行效率是否一样,因为如果简单的从语句先后上看,这两个语句的确是不一样,如果tID是一个聚合索引,那
-
详解SQL Server中的事务与锁问题
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章试图采用图文的方式来与大家一起探讨. "浅谈SQL Server 事务与锁"这个专题共分两篇,上篇主讲事务及事务一致性问题,并简略的提及一下锁的种类和锁的控制级别. 下篇主讲SQL Server中的锁机制,锁控制级别和死锁的若干问题. 二 事务 1 何为事务 预览众多书籍,对于事务的定义,不同文献不同作者对其虽有细微差别却大致统一,我们将其抽象概括为: 事务:指封装且执行单个或多个操作的
-
细说SQL Server中的视图
1,什么是视图? 2,为什么要用视图: 3,视图中的ORDER BY; 4,刷新视图: 5,更新视图: 6,视图选项: 7,索引视图: 1.什么是视图 视图是由一个查询所定义的虚拟表,它与物理表不同的是,视图中的数据没有物理表现形式,除非你为其创建一个索引:如果查询一个没有索引的视图,Sql Server实际访问的是基础表. 如果你要创建一个视图,为其指定一个名称和查询即可.Sql Server只保存视图的元数据,用户描述这个对象,以及它所包含的列,安全,依赖等.当你查询视图时,无论是获取数据还
-
SQL Server中的Forwarded Record计数器影响IO性能的解决方法
一.简介 最近在一个客户那里注意到一个计数器很高(Forwarded Records/Sec),伴随着间歇性的磁盘等待队列的波动.本篇文章分享什么是forwarded record,并从原理上谈一谈为什么Forwarded record会造成额外的IO. 二.存放原理 在SQL Server中,当数据是以堆的形式存放时,数据是无序的,所有非聚集索引的指针存放指向物理地址的RID.当数据行中的变长列增长使得原有页无法容纳下数据行时,数据将会移动到新的页中,并在原位置留下一个指向新页的指针,这么做的
-
在SQL SERVER中导致索引查找变成索引扫描的问题分析
SQL Server 中什么情况会导致其执行计划从索引查找(Index Seek)变成索引扫描(Index Scan)呢? 下面从几个方面结合上下文具体场景做了下测试.总结.归纳. 1:隐式转换会导致执行计划从索引查找(Index Seek)变为索引扫描(Index Scan) Implicit Conversion will cause index scan instead of index seek. While implicit conversions occur in SQL Serve