使用phantomjs进行网页抓取的实现代码
phantomjs因为是无头浏览器可以跑js,所以同样可以跑dom节点,用来进行网页抓取是再好不过了。
比如我们要批量抓取网页 “历史上的今天” 的内容。网站

对dom结构的观察发现,我们只需要取到 .list li a的title值即可。因此我们利用高级选择器构建dom片段
var d= ''
var c = document.querySelectorAll('.list li a')
var l = c.length;
for(var i =0;i<l;i++){
d=d+c[i].title+'\n'
}
之后只需要让js代码在phantomjs里跑起来即可~
var page = require('webpage').create();
page.open('http://www.todayonhistory.com/', function (status) { //打开页面
if (status !== 'success') {
console.log('FAIL to load the address');
} else {
console.log(page.evaluate(function () {
var d= ''
var c = document.querySelectorAll('.list li a')
var l = c.length;
for(var i =0;i<l;i++){
d=d+c[i].title+'\n'
}
return d
}))
}
phantom.exit();
});
最终我们另存为catch.js,在dos里面执行一下,输出内容到txt文件(也可以用phantomjs的文件api来写)
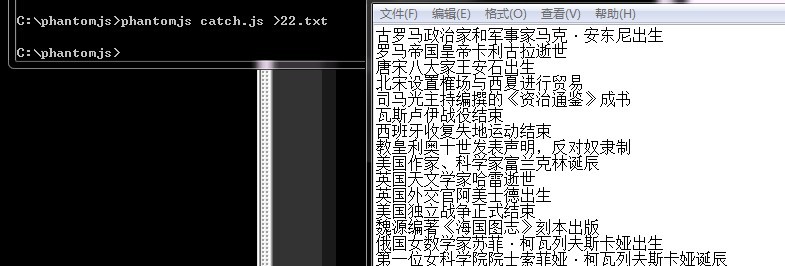
相关推荐
-
Node.JS利用PhantomJs抓取网页入门教程
前言 当想用 nodejs 抓取一些网页 , 我第一反应想到的就是使用 http 模块 , 比如抓取百度首页: var http = require('http'); var req = http.request('http://www.baidu.com/', function (res) { res.setEncoding('utf8'); res.on('data', function (chunk) { //响应内容 console.log(chunk) }); }); req.end(
-
Node.js实现的简易网页抓取功能示例
现今,网页抓取已经是一种人所共知的技术了,然而依然存在着诸多复杂性, 简单的网页爬虫依然难以胜任Ajax轮训.XMLHttpRequest,WebSockets,Flash Sockets等各种复杂技术所开发出来的现代化网站. 我们以我们在Hubdoc这个项目上的基础需求为例,在这个项目中,我们从银行,公共事业和信用卡公司的网站上抓取帐单金额,到期日期,账户号码,以及最重要的:近期账单的pdf.对于这个项目,我一开始采用了很简单的方案(暂时并没有使用我们正在评估的昂贵的商业化产品)--我以前在M
-
Node.js抓取中文网页乱码问题和解决方法
Node.js 抓取非 utf-8 的中文网页时会出现乱码问题,比如网易的首页编码是 gb2312,抓取时会出现乱码 复制代码 代码如下: var request = require('request') var url = 'http://www.163.com' request(url, function (err, res, body) { console.log(body) }) 可以使用 iconv-lite来解决 安装 复制代码 代码如下: npm install ico
-
node.js抓取并分析网页内容有无特殊内容的js文件
nodejs获取网页内容绑定data事件,获取到的数据会分几次相应,如果想全局内容匹配,需要等待请求结束,在end结束事件里把累积起来的全局数据进行操作! 举个例子,比如要在页面中找有没有www.baidu.com,不多说了,直接放代码: //引入模块 var http = require("http"), fs = require('fs'), url = require('url'); //写入文件,把结果写入不同的文件 var writeRes = function(p, r)
-
nodejs通过phantomjs实现下载网页
功能其实很见简单,通过 phantomjs.exe 采集 url 加载的资源,通过子进程的方式,启动nodejs 加载所有的资源,对于css的资源,匹配css内容,下载里面的url资源 当然功能还是很简单的,在响应式设计和异步加载的情况下,还是有很多资源没有能够下载,需要根据实际情况处理下 首先当然是下载 nodejs 和 phantomjs 下面是 phantomjs.exe 执行的 down.js var page = require('webpage').create(), system
-

利用NodeJS和PhantomJS抓取网站页面信息以及网站截图
利用PhantomJS做网页截图经济适用,但其API较少,做其他功能就比较吃力了.例如,其自带的Web Server Mongoose最高只能同时支持10个请求,指望他能独立成为一个服务是不怎么实际的.所以这里需要另一个语言来支撑服务,这里选用NodeJS来完成. 安装PhantomJS 首先,去PhantomJS官网下载对应平台的版本,或者下载源代码自行编译.然后将PhantomJS配置进环境变量,输入 $ phantomjs 如果有反应,那么就可以进行下一步了. 利用PhantomJS进行简
-
使用phantomjs进行网页抓取的实现代码
phantomjs因为是无头浏览器可以跑js,所以同样可以跑dom节点,用来进行网页抓取是再好不过了. 比如我们要批量抓取网页 "历史上的今天" 的内容.网站 对dom结构的观察发现,我们只需要取到 .list li a的title值即可.因此我们利用高级选择器构建dom片段 var d= '' var c = document.querySelectorAll('.list li a') var l = c.length; for(var i =0;i<l;i++){ d=d+
-
java简单网页抓取的实现方法
本文实例讲述了java简单网页抓取的实现方法.分享给大家供大家参考.具体分析如下: 背景介绍 一 tcp简介 1 tcp 实现网络中点对点的传输 2 传输是通过ports和sockets ports提供了不同类型的传输(例如 http的port是80) 1)sockets可以绑定在特定端口上,并且提供传输功能 2)一个port可以连接多个socket 二 URL简介 URL 是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址. 互联网上的每个文件都有一个唯一的
-
C#基于正则表达式实现获取网页中所有信息的网页抓取类实例
本文实例讲述了C#基于正则表达式实现获取网页中所有信息的网页抓取类.分享给大家供大家参考,具体如下: 类的代码: using System; using System.Data; using System.Configuration; using System.Net; using System.IO; using System.Text; using System.Collections.Generic; using System.Text.RegularExpressions; using
-
学习Python selenium自动化网页抓取器
直接入正题---Python selenium自动控制浏览器对网页的数据进行抓取,其中包含按钮点击.跳转页面.搜索框的输入.页面的价值数据存储.mongodb自动id标识等等等. 1.首先介绍一下 Python selenium ---自动化测试工具,用来控制浏览器来对网页的操作,在爬虫中与BeautifulSoup结合那就是天衣无缝,除去国外的一些变态的验证网页,对于图片验证码我有自己写的破解图片验证码的源代码,成功率在85%. 详情请咨询QQ群--607021567(这不算广告,群里有好多P
-
PHP网页抓取之抓取百度贴吧邮箱数据代码分享
百度贴吧大家都经常逛,去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发. 对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些回复的邮箱,然后再粘贴发送邮件,不是被折磨死就是被累死.无聊至极写了一个抓取百度贴吧邮箱数据的程序,需要的拿走. 程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,界面懒得做了,效果如下: 老规矩,直接贴源码 <?php $url2=""; $page=""; if($_GET['url
-
php 论坛采集程序 模拟登陆,抓取页面 实现代码
复制代码 代码如下: <?php // 吴燕军 // 2009-06-27 // 采集程序php set_time_limit(0); //cookie保存目录 $cookie_jar = '/tmp/cookie.tmp'; /*函数------------------------------------------------------------------------------------------------------------*/ //模拟请求数据 function req
-
asp中利用xmlhttp抓取网页内容的代码
需要分件html源代码 此例中的被抓取的html源代码如下 <p align=left>2004年8月24日星期二:白天:晴有时多云南风3-4级:夜间:晴南风3-4级:气温:最高29℃最低19℃ </p> 而程序中是从 以2004年8月24日为关键字搜索,直到</p>结速 而抓取的内容就变成了"2004年8月24日星期二:白天:晴有时多云南风3-4级:夜间:晴南风3-4级:气温:最高29℃最低19℃ " 干干净净的了.记录一下. 复制代码 代码如下:
-
php抓取页面与代码解析 推荐
得到数据我们不能直接输出,往往需要对内容进行提取,然后再进行格式化,以更加友好的方式显现出来.下面先简单说一下本文的主要内容: 一. PHP抓取页面的主要方法: 1. file()函数 2. file_get_contents()函数 3. fopen()->fread()->fclose()模式 4.curl方式 5. fsockopen()函数 socket模式 6. 使用插件(如:http://sourceforge.net/projects/snoopy/) 二.PHP解析html或x
-
java 抓取网页内容实现代码
复制代码 代码如下: package test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.Authenticator; import java.net.HttpURLConnection; import java.net.PasswordAuthentication