python 中 os.walk() 函数详解
os.walk()是一种遍历目录数的函数,它以一种深度优先的策略(depth-first)访问指定的目录。
其返回的是(root,dirs, files),
- root代表当前遍历的目录路径,string类型
- dirs代表root路径下的所有子目录名称,list类型,列表中的每个元素是string类型,代表子目录名称。
- files代表root路径下的所有子文件名称,返回list类型,列表中的每个元素是string类型,代表子文件名称。
加入我当前的目录如下。
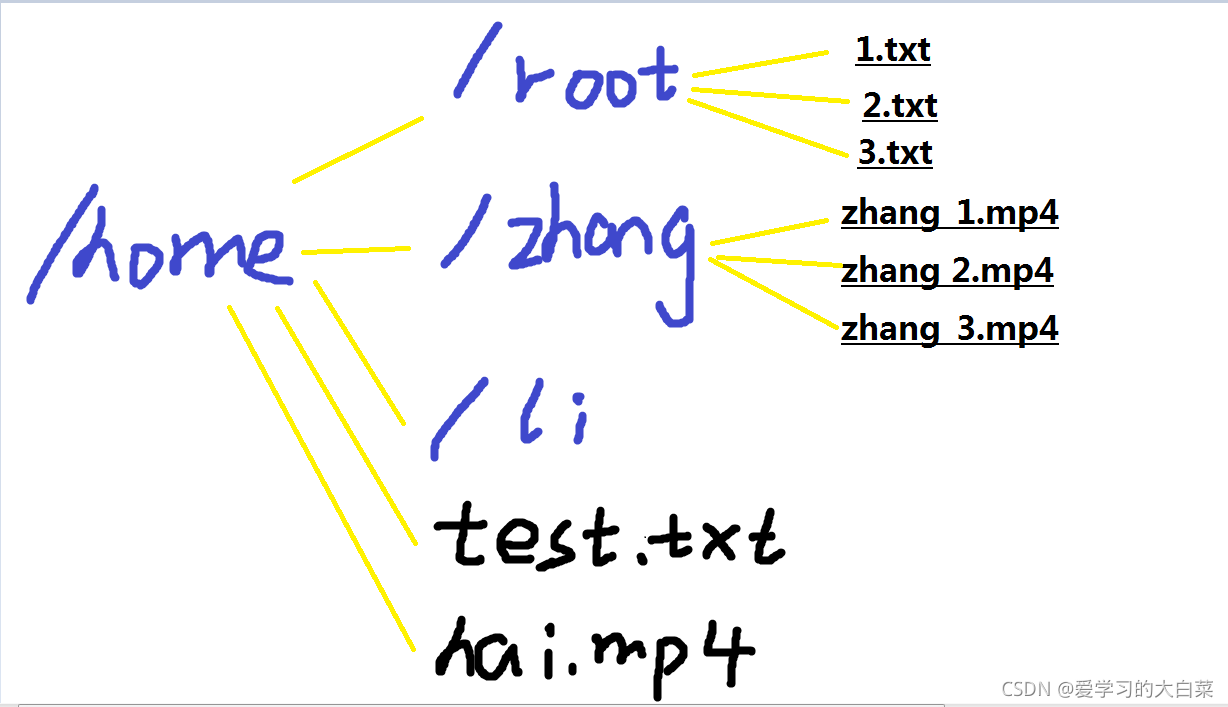
可以先打印一下其是怎么遍历的:
import os
from os.path import join
home_path = "/home"
for (root, dirs, files) in os.walk(home_path):
print(root)
print(dirs)
print(files)
print("=" * 50)
输出如下:
/home
['root', 'zhang', 'li']
['test.txt', 'hai.mp4']
==================================================
/home/root
[]
['1.txt', '2.txt', '3.txt']
==================================================
/hoome/zhang
[]
['zhang_1.mp4', 'zhang_2.mp4', 'zhang_3.mp4']
==================================================
/home/li
[]
[]
==================================================
一共三行,
第1行代表当前遍历的目录,我们称为root目录,
第2行代表root目录下的子目录列表,我们称为dirs,
第3行代表root目录下的子文件列表,我们称为files,
上面的列表为空就代表当前遍历的root目录下没有子目录或者没有子文件。
另外,如果我想遍历home目录下所有的目录和文件的绝对路径,则直接用os.path.join()方法对 子目录或子文件名 和 root目录 进行拼接即可,则代码如下:
import os
from os.path import join
home_path = "/home"
for (root, dirs, files) in os.walk(home_path):
for dir in dirs:
print(join(root, dir))
for file in files:
print(join(root, file))
输出:
/home
/home/root
/home/zhang
/home/li
/home/test.txt
/home/hai.mp4
/home/root/1.txt
/home/root/2.txt
/home/root/3.txt
/home/zhang/zhang_1.mp4
/home/zhang/zhang_2.mp4
/home/zhang/zhang_3.mp4
到此这篇关于python 中 os.walk() 函数的文章就介绍到这了,更多相关python os.walk() 函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 获取文件下所有文件或目录os.walk()的实例
在python3.6版本中去掉了os.path.walk()函数 os.walk() 函数声明:walk(top,topdown=True,oneerror=None) 1.参数top表示需要遍历的目录树的路径 2.参数农户topdown默认是"True",表示首先返回根目录树下的文件,然后,再遍历目录树的子目录.topdown的值为"False",则表示先遍历目录树的子目录,返回子目录下的文件,最后返回根目录下的文件 3.参数oneerror的默认值是"
-

Python使用os.listdir()和os.walk()获取文件路径与文件下所有目录的方法
在python3.6版本中去掉了os.path.walk()函数 os.walk() 函数声明:walk(top,topdown=True,oneerror=None) 1.参数top表示需要遍历的目录树的路径 2.参数农户topdown默认是"True",表示首先返回根目录树下的文件,然后,再遍历目录树的子目录.topdown的值为"False",则表示先遍历目录树的子目录,返回子目录下的文件,最后返回根目录下的文件 3.参数oneerror的默认值是"
-
详解python os.walk()方法的使用
python os.walk()方法 os.walk方法是python中帮助我们高效管理文件.目录的工具,在深度学习中数据整理应用的很频繁,如数据集的名称格式化.将数据集的按一定比例划分训练集train_set.测试集test_set. 1.导入文件(使用os.walk方法前需要导入以下包) import os import random # 后续用来将数据随机打乱和生成确定随机种子,保证每次生成的随机数据一样便于测试模型精准度 2.os.walk()参数解释 os.walk(top, topd
-
python 中 os.walk() 函数详解
os.walk()是一种遍历目录数的函数,它以一种深度优先的策略(depth-first)访问指定的目录. 其返回的是(root,dirs, files), root代表当前遍历的目录路径,string类型 dirs代表root路径下的所有子目录名称,list类型,列表中的每个元素是string类型,代表子目录名称. files代表root路径下的所有子文件名称,返回list类型,列表中的每个元素是string类型,代表子文件名称. 加入我当前的目录如下. 可以先打印一下其是怎么遍历的: imp
-
python中的 zip函数详解及用法举例
python中zip()函数用法举例 定义:zip([iterable, ...]) zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压),看下面的例子就明白了: 示例1 x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] x
-
python中lambda匿名函数详解
在Python中,不通过def来声明函数名字,而是通过lambda关键字来定义的函数称为匿名函数 关键字lambda表示匿名函数 语法 lambda 参数:表达式 先写lambda关键字,然后依次写匿名函数的参数,多个参数中间用逗号连接,然后是一个冒号,冒号后面写返回的表达式 lambda函数比普通函数更简洁 匿名函数有个好处:函数没有名字,不必担心函数名冲突 匿名函数与普通函数的对比 : def sum_func(a, b, c): return a + b + c sum_lambda =
-
对python中的os.getpid()和os.fork()函数详解
如下所示: import os import sys import time processNmae = 'parent' print "Program executing ntpid:%d,processNmae:%s"%(os.gitpid(),processNmae) #attempt to fork child process try: forkPid = os.fork() except OSError: sys.exit("Unable to create new
-
Python中logger日志模块详解
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息: print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据:logging则可以由开发者决定将信息输出到什么地方,以及怎么输出: Logger从来不直接实例化,经常通过logging模块级方法(Modu
-
python中模块导入模式详解
目录 模块导入 1.1 import导入模块 1.2 from 模块名 import 导入模板的方法 1.3 as 关键字 OS模块操作文件 OS模块的作用 模块的制作.发布.安装 3.1 模块制作 3.2 模块的分 3.3 示例 3.4 测试方法 3.5 all魔术方法 模块导入 1.1 import导入模块 所谓的模块其实就是一个外部的工具包,其中存在的其实就是Python文件,这些文件都实现了某种特定的功能,我们导入包之后直接使用即可,非常的方便. 在开发中使用最多的就是使用: impor
-
javascript中Array()数组函数详解
在程序语言中数组的重要性不言而喻,JavaScript中数组也是最常使用的对象之一,数组是值的有序集合,由于弱类型的原因,JavaScript中数组十分灵活.强大,不像是Java等强类型高级语言数组只能存放同一类型或其子类型元素,JavaScript在同一个数组中可以存放多种类型的元素,而且是长度也是可以动态调整的,可以随着数据增加或减少自动对数组长度做更改. Array()是一个用来构建数组的内建构造器函数.数组主要由如下三种创建方式: array = new Array() array =
-
Python中格式化format()方法详解
Python中格式化format()方法详解 Python中格式化输出字符串使用format()函数, 字符串即类, 可以使用方法; Python是完全面向对象的语言, 任何东西都是对象; 字符串的参数使用{NUM}进行表示,0, 表示第一个参数,1, 表示第二个参数, 以后顺次递加; 使用":", 指定代表元素需要的操作, 如":.3"小数点三位, ":8"占8个字符空间等; 还可以添加特定的字母, 如: 'b' - 二进制. 将数字以2为基
-
对Python3中的input函数详解
下面介绍python3中的input函数及其在python2及pyhton3中的不同. python3中的ininput函数,首先利用help(input)函数查看函数信息: 以上信息说明input函数在python中是一个内建函数,其从标准输入中读入一个字符串,并自动忽略换行符. 也就是说所有形式的输入按字符串处理,如果想要得到其他类型的数据进行强制类型转化.默认情况下没有 提示字符串(prompt string),在给定提示字符串下,会在读入标准输入前标准输出提示字符串.如果遇 文件结束符
-
Python中的asyncio代码详解
asyncio介绍 熟悉c#的同学可能知道,在c#中可以很方便的使用 async 和 await 来实现异步编程,那么在python中应该怎么做呢,其实python也支持异步编程,一般使用 asyncio 这个库,下面介绍下什么是 asyncio : asyncio 是用来编写 并发 代码的库,使用 async/await 语法. asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等. asyncio 往往是构建 IO 密集型和