sql server排查死锁优化性能
一.概述
记得以前客户在使用软件时,有偶发出现死锁问题,因为发生的时间不确定,不好做问题的重现,当时解决问题有点棘手了。现总结下查看死锁的常用二种方式。
1.1 第一种是图形化监听:
sqlserver -->工具--> sql server profiler 登录后在跟踪属性中选择如下图:
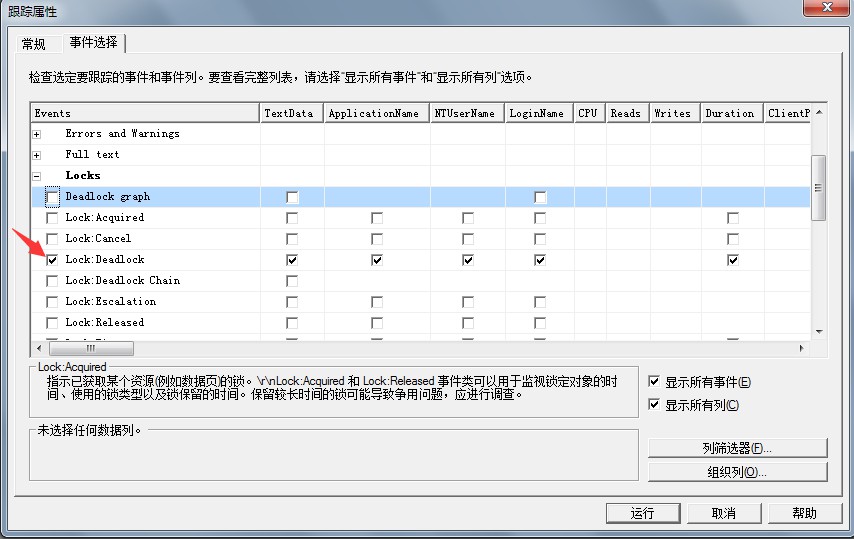
监听到的死锁图形如下图


这里的描述大致是:有二个进程 一个进程ID是96, 另一个ID是348. 系统自动kill 掉了进程ID:96,保留了进程ID:348 的事务Commit。
上面死锁是由于批量更新出现PAG范围锁, 双方进程在同一分区索引资源上。ID96,348都请求想获取更新锁(U),各占排它锁(x)不释放,直到锁超时。
1.2 第二种是使用日志跟踪(errorlog)
以全局方式打开指定的跟踪标记
DBCC TRACEON(1222,-1) DBCC TRACEON(1204,-1)
使用 EXEC master..xp_readerrorlog 查看日志。
Deadlock encountered .... Printing deadlock information Wait-for graph NULL Node:1 PAGE: 7:1:6229275 CleanCnt:2 Mode:IX Flags: 0x3 Grant List 3: Owner:0x00000004E99B7880 Mode: IX Flg:0x40 Ref:1 Life:02000000 SPID:219 ECID:0 XactLockInfo: 0x0000000575C7E970 SPID: 219 ECID: 0 Statement Type: UPDATE Line #: 84 Input Buf: Language Event: exec proc_PUB_StockDataImport Requested by: ResType:LockOwner Stype:'OR'Xdes:0x0000000C7A905D30 Mode: U SPID:64 BatchID:0 ECID:59 TaskProxy:(0x0000000E440AAFE0) Value:0x8d160240 Cost:(0/0) NULL Node:2 PAGE: 7:1:5692366 CleanCnt:2 Mode:U Flags: 0x3 Grant List 3: Owner:0x0000000D12099B80 Mode: U Flg:0x40 Ref:0 Life:00000001 SPID:64 ECID:0 XactLockInfo: 0x000000136B4758F0 SPID: 64 ECID: 0 Statement Type: UPDATE Line #: 108 Input Buf: RPC Event: Proc [Database Id = 7 Object Id = 907150277]
node:1 部分显示的几个关键信息:
PAGE 7:1:6229275(所在数据库ID 7, 1分区, 6229275行数)
Mode: IX 锁的模式 意向排它锁
SPID: 219 进程ID
Event: exec proc_PUB_StockDataImport 执行的存储过程名
node:2 部分显示的几个关键信息
PAGE 7:1:5692366 (所在数据库ID 7, 1分区,5692366行数)
Mode:U锁的模式 更新锁
RPC Event: Proc 远程调用
SPID: 64 进程ID
Victim Resource Owner: ResType:LockOwner Stype:'OR'Xdes:0x0000000C7A905D30 Mode: U SPID:64 BatchID:0 ECID:59 TaskProxy:(0x0000000E440AAFE0) Value:0x8d160240 Cost:(0/0) deadlock-list deadlock victim=process956f4c8 process-list process id=process956f4c8 taskpriority=0 logused=0 waitresource=PAGE: 7:1:6229275 waittime=2034 ownerId=2988267079 transactionname=UPDATE lasttranstarted=2018-04-19T13:54:00.360 XDES=0xc7a905d30 lockMode=U schedulerid=24 kpid=1308 status=suspended spid=64 sbid=0 ecid=59 priority=0 trancount=0 lastbatchstarted=2018-04-19T13:53:58.033 lastbatchcompleted=2018-04-19T13:53:58.033 clientapp=.Net SqlClient Data Provider hostname=VMSERVER76 hostpid=16328 isolationlevel=read committed (2) xactid=2988267079 currentdb=7 lockTimeout=4294967295 clientoption1=671088672 clientoption2=128056 executionStack frame procname=Test.dbo.proc_CnofStock line=108 stmtstart=9068 stmtend=9336 sqlhandle=0x03000700c503123601ba25019ca800000100000000000000 update dbo.pub_stock set UpdateTime=GETDATE() from pub_stock a join PUB_PlatfromStocktemp b on a.GUID=b.StockGuid
从上面的信息能看到kill 掉的是进程id是process956f4c8,
进程spid=64
lockMode=U 获取更新锁
isolationlevel=read committed
executionStack 执行的堆信息:
存储名 procname=Test.dbo.proc_CnofStock
语句 update dbo.pub_stock set UpdateTime=GETDATE() ..
clientapp 发起事件的来源
1.3 最后总结 避免死锁的解决方法
按同一顺序访问对象。
优化索引,避免全表扫描,减少锁的申请数目.
避免事务中的用户交互。
使用基于行版本控制的隔离级别。
将事务默认隔离级别的已提交读改成快照
SET TRANSACTION ISOLATION LEVEL SNAPSHOT
使用nolock去掉共享锁,但死锁发生在u锁或x锁上,则nolock不起作用
升级锁颗粒度(页锁,表锁), 以阻塞还代替死锁
到此这篇关于sql server排查死锁优化性能的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

SQLServer RANK() 排名函数的使用
本文主要介绍了SQLServer RANK() 排名函数的使用,具体如下: -- 例子表数据 SELECT * FROM test; -- 统计分数 SELECT name,SUM(achievement) achievement FROM test GROUP BY name; -- 按统计分数做排行 SELECT RANK() OVER( ORDER BY SUM(achievement) desc) 排行,name,SUM(achievement) achievement FROM tes
-
SQL SERVER使用表分区优化性能
目录 1.简介 2.表分区 2.1分区范围 2.2分区键 2.3索引分区 3.创建表分区 3.1创建文件组 3.2指定文件组存放路径 3.3创建分区函数 3.4创建分区方案 3.5创建分区表 3.6创建分区索引 4.表分区的优缺点 1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护
-
SQL Server中常用截取字符串函数介绍
SQL Server中一共提供了三个字符串截取函数:LEFT().RIGHT().SUBSTRING(). 一.LEFT()函数 函数说明如下: 语法:LEFT(character,integer). 参数介绍:参数1:要截取的字符串,参数2:截取字符个数. 返回值:返回从字符串左边开始指定个数的字符. 示例SQL:select LEFT('SQLServer_2012',3). 返回:SQL. 二.RIGHT()函数 函数说明如下: 语法:RIGHT(character,integer). 参
-
SQL Server远程连接的设置步骤(图文)
SQL Server正常连接时,若不需要远程操控其他电脑,可以用Windows身份验证模式,但是涉及到远程处理时,需要通过SQL Server身份验证登录.具体操作如下. 首先,我们在登录时,选择Windows身份验证,然后连接到服务器. 进入到登录主页面后,右击当前的对象资源管理器,选择属性,弹出如下图所示的页面,选择安全性,将服务器身份验证勾选为SQL Server和Windows身份验证模式,(若在安装软件时已选择第二种验证模式,可直接通过账号登录)如图2所示. 图2. 图3. 如图3所示
-
SQL Server内存机制详解
1.前言 对于数据库引擎来说,内存是一个性能提升的重要解决手段.把数据缓存起来,可以避免在查询或更新数据时花费多余的时间,而这时间通常是从磁盘获取数据时用来等待磁盘寻址的.把执行计划缓存起来,可以避免重复分析执行计划时带来额外的CPU及各种资源的开销.通过在内存中开辟查询内存空间,可以迅速地完成排序.哈希等计算,达到快速返回运算结果的目的.若没有足够的内存空间,数据库引擎将无法快速地响应用户的请求. 2.SQL Server如何从操作系统层面分配内存 SQL Server存储引擎本身是一个Win
-
MySQL Server 层四个日志
一.MySQL Server层日志简介 一个mysql client发起一个连接请求,处理请求的过程如下图所示: MySQL日志是在MySQL server上生成的,不管更改哪个存储引擎,这些日志都是需要有的,包括: 错误日志:记录mysqld服务运行过程中出现的cordump.error.exception等 查询日志:记录客户端所有的SQL.由于上线项目的SQL太多了,开启查询日志IO太多导致MySQL效率低下,我们一般都不会开启,只有调试时才开启 二进制日志:记录数据的更改(insert.
-
SQL Server表空间碎片化回收的实现
目录 1 锁片化的产生 1.1 产生碎片化的原因 1.2 碎片化的影响 1.3 定位碎片化 2 碎片化处理 2.1 删除并重建聚集索引 2.2 DROP_EXISTING 2.3 DBCC DBREINDEX 2.4 DBCC INDEXDEFRAG 3 空间回收 参考链接: 1 锁片化的产生 1.1 产生碎片化的原因 1.在B-tree索引中,表数据按照聚集索引的排序进行物理存储,若聚集索引离散化比较严重,那么可能会出现较为严重的碎片化问题: 2.随着业务的DML操作,会伴随着数据页分裂的情况
-
SQL Server中函数、存储过程与触发器的用法
一.函数 函数分为(1)系统函数,(2)自定义函数. 其中自定义函数又可以分为(1)标量值函数(返回单个值),(2)表值函数(返回查询结果) 本文主要介绍自定义函数的使用. (1)编写一个函数求该银行的金额总和 create function GetSumCardMoney() returns money as begin declare @AllMOney money select @AllMOney = (select SUM(CardMoney) from BankCard) return
-
MySQL Server层四个日志的实现
目录 一.MySQL Server层日志简介 二.配置文件参数 三.错误日志 四.查询日志 五.二进制日志 1. 演示binlog记录更改 2. 演示binlog数据恢复 六.慢查询日志 一.MySQL Server层日志简介 一个mysql client发起一个连接请求,处理请求的过程如下图所示: MySQL日志是在MySQL server上生成的,不管更改哪个存储引擎,这些日志都是需要有的,包括: 错误日志:记录mysqld服务运行过程中出现的cordump.error.exception等
-
SQL Server使用导出向导功能
1.前言 有时候,我们需要把A库A1表某一部分或全部数据导出到B库B1表中,如果系统运维工程师没打通两个库链接,我们执行T-SQL是处理数据导入时会发生如下错误: 这时候SQL Server导出功能很好弥补这一点,而该章节重点介绍该功能. 2.操作 数据库版本:Microsoft SQL Server Management Studio 17:源头数据库:[172.168.16.xxx].[PartInChina_cn].[dbo].[PUB_Stock]目标数据库:[local].[dbo].