scrapy中的spider传参实现增量的方法
有时候需要根据项目的实际需求向spider传递参数来控制spider的运行方式。
比如说,1.根据用户提交的url来控制spider爬取的网站。2.根据需求增量爬取数据。
今天就写一个增量(augmenter)的方式:
Spider参数通过 crawl 命令的 -a 选项来传递,比如:
scrapy crawl xxx -a augmenter=xxxxxx
注:augmenter=不为空
1.首先在spider里添加

注:在网上也看了不少的博客,最后发现*args, **kwargs这两个必须加上,要不然会出现bug,不信的话可以试试哦!
如果想减少代码量的话,可以写到类里面去继承!那这样的话,spider里面就不要在写了!!!要不然就不起作用了!!!
还有
super(eval(self.__class__.__name__), self).__init__(*args, **kwargs)
这里的eval()获取的是类名,这样写必须是最后一个是你要的类名,中间有继承什么的,就会出错!或者直接把类名粘过来!
2.spider实现方式:
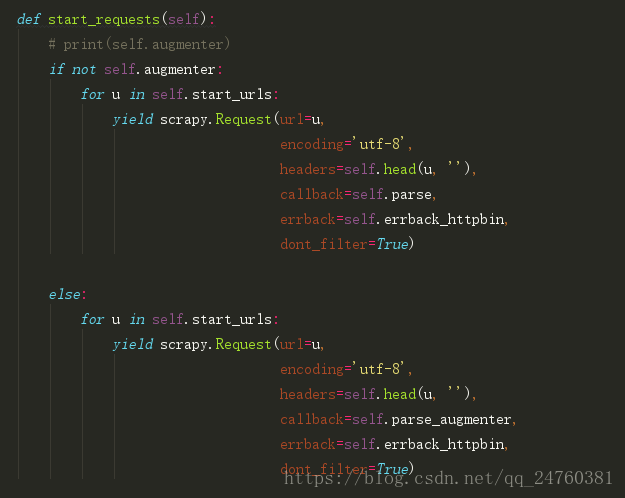
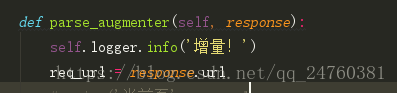
这样就实现了简单的增量!增量的方式有很多,常见的:时间、计数、爬取特定的几页!
选择自己需要的增量方式写在这个parse_augmenter()里面,
这样需要从头开始run和增量run就不受影响!
到此这篇关于scrapy中的spider传参实现增量的方法的文章就介绍到这了,更多相关scrapy spider传参增量内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解向scrapy中的spider传递参数的几种方法(2种)
有时需要根据项目的实际需求向spider传递参数以控制spider的行为,比如说,根据用户提交的url来控制spider爬取的网站.在这种情况下,可以使用两种方法向spider传递参数. 第一种方法,在命令行用crawl控制spider爬取的时候,加上-a选项,例如: scrapy crawl myspider -a category=electronics 然后在spider里这样写: import scrapy class MySpider(scrapy.Spider): name = 'm
-
如何向scrapy中的spider传递参数的几种方法
有时需要根据项目的实际需求向spider传递参数以控制spider的行为,比如说,根据用户提交的url来控制spider爬取的网站.在这种情况下,可以使用两种方法向spider传递参数. 第一种方法,在命令行用crawl控制spider爬取的时候,加上-a选项,例如: scrapy crawl myspider -a category=electronics 然后在spider里这样写: import scrapy class MySpider(scrapy.Spider): name = 'm
-
Scrapy中如何向Spider传入参数的方法实现
在使用Scrapy爬取数据时,有时会碰到需要根据传递给Spider的参数来决定爬取哪些Url或者爬取哪些页的情况. 例如,百度贴吧的放置奇兵吧的地址如下,其中 kw参数用来指定贴吧名称.pn参数用来对帖子进行翻页. https://tieba.baidu.com/f?kw=放置奇兵&ie=utf-8&pn=250 如果我们希望通过参数传递的方式将贴吧名称和页数等参数传给Spider,来控制我们要爬取哪一个贴吧.爬取哪些页.遇到这种情况,有以下两种方法向Spider传递参数. 方式一 通过
-
scrapy redis配置文件setting参数详解
scrapy项目 setting.py #Resis 设置 #使能Redis调度器 SCHEDULER = 'scrapy_redis.scheduler.Scheduler' #所有spider通过redis使用同一个去重过滤器 DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' #不清除Redis队列.这样可以暂停/恢复 爬取 #SCHEDULER_PERSIST = True #SCHEDULER_QUEUE_CLASS =
-
scrapy爬虫:scrapy.FormRequest中formdata参数详解
1. 背景 在网页爬取的时候,有时候会使用scrapy.FormRequest向目标网站提交数据(表单提交).参照scrapy官方文档的标准写法是: # header信息 unicornHeader = { 'Host': 'www.example.com', 'Referer': 'http://www.example.com/', } # 表单需要提交的数据 myFormData = {'name': 'John Doe', 'age': '27'} # 自定义信息,向下层响应(respon
-

scrapy中的spider传参实现增量的方法
有时候需要根据项目的实际需求向spider传递参数来控制spider的运行方式. 比如说,1.根据用户提交的url来控制spider爬取的网站.2.根据需求增量爬取数据. 今天就写一个增量(augmenter)的方式: Spider参数通过 crawl 命令的 -a 选项来传递,比如: scrapy crawl xxx -a augmenter=xxxxxx 注:augmenter=不为空 1.首先在spider里添加 注:在网上也看了不少的博客,最后发现*args, **kwargs这两个必须
-
在axios中使用params传参的时候传入数组的方法
如下: changeList为一个数组 此时请求的参数格式为下图 解决方案为 将数组json序列化 此时参数格式为 以上这篇在axios中使用params传参的时候传入数组的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
vue 中的动态传参和query传参操作
Vue router 如何传参 params.query 是什么? params:/router1/:id,这里的 id 叫做 params.例如/router1/123, /router1/789 query:/router1?id=123,这里的 id 叫做 query.例如/router1?id=456 query 方式传参和接收参数 传参: this.$router.push({ path:'/xxx' query:{ id:id } }) this.$router.push 传参时,
-
在scrapy中使用phantomJS实现异步爬取的方法
使用selenium能够非常方便的获取网页的ajax内容,并且能够模拟用户点击和输入文本等诸多操作,这在使用scrapy爬取网页的过程中非常有用. 网上将selenium集成到scrapy的文章很多,但是很少有能够实现异步爬取的,下面这段代码就重写了scrapy的downloader,同时实现了selenium的集成以及异步. 使用时需要PhantomJSDownloadHandler添加到配置文件的DOWNLOADER中. # encoding: utf-8 from __future__ i
-
jsp页面传参乱码的解决方法
jsp页面传参乱码的解决方法 jsp页面js: encodeURIComponent要使用两次encodeURIComponent(encodeURIComponent(userAccount)); java:String userAccount = java.net.URLDecoder.decode(userAccount,"UTF-8");/*需要处理异常*/ 纯属个人备注,以便后期使用
-
php获取'/'传参的值简单方法
通过输出$GLOBALS可以看到'/'后的参数都存在于$_SERVER['PATH_INFO']里: 声明一个数组来获取我们在'/'后传递的参数 $arr = explode('/', $_SERVER['PATH_INFO']); //print_r($arr)查看详细信息 以上这篇php获取'/'传参的值简单方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
微信小程序url传参写变量的方法
具体代码如下所示: <navigator url="../../pages/newsDetail/newsDetail?id={{news.id}}"> <view class="list-item"> <view class="little-item"> <view class="left-box"> <image src="{{news.thumb[0]}}&
-
详解Angular5 路由传参的3种方法
本文介绍了Angular5 路由传参,一共3种方法.分享给大家,具体如下: 1.问号后面带的参数,获取参数的方式:ActivatedRoute.queryParams[id] 例如:/product?id=1&name=iphone还可以是: [ routerLink]= "['/books']" [ queryParams]= "{bookname:'<活着>'} 代码:html <h4>Messages</h4> <p&g