MySQL聚簇索引和非聚簇索引的区别详情
目录
- 聚簇索引
- 非聚簇索引
- 总结
前言:
在 MySQL 默认引擎 InnoDB 中,索引大致可分为两类:聚簇索引和非聚簇索引,它们的区别也是常见的面试题,所以我们今天就来盘它们。
聚簇索引
聚簇索引(Clustered Index)一般指的是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引。
聚簇索引在 InnoDB 中是使用 B+ 树实现的,比如我们创建一张 student 表,它的构建 SQL 如下:
drop table if exists student;
create table student(
id int primary key,
name varchar(16),
class_id int not null,
index (class_id)
)engine=InnoDB;
-- 添加测试数据
insert into student(id,name,class_id) values(1,'张三',100),
(2,'李四',200),(3,'王五',300);
以上 student 表中有一个聚簇索引(也就是主键索引)id,和一个非聚簇索引 class_id。
聚簇索引 id 对应的 B+ 树如下图所示:
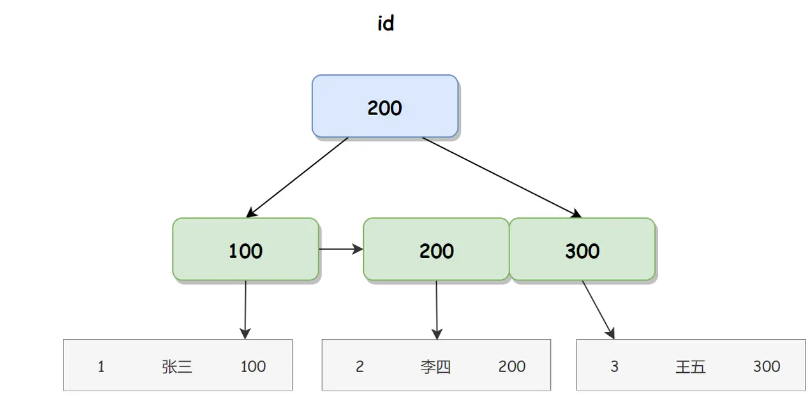
在聚簇索引的叶子节点直接存储用户信息的内存地址,我们使用内存地址可以直接找到相应的行数据。
非聚簇索引
非聚簇索引在 InnoDB 引擎中,也叫二级索引,以上面 student 表为例,
在 student 中非聚簇索引 class_id 对应 B+ 树如下图所示:
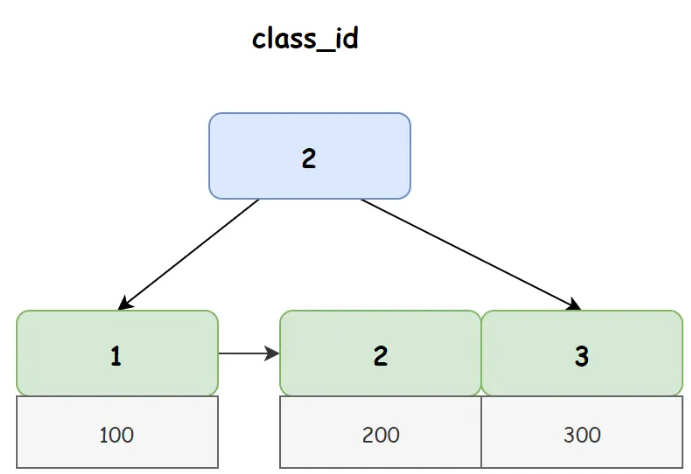
从上图我们可以看出,在非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID,所以当我们使用非聚簇索引进行查询时,首先会得到一个主键 ID,然后再使用主键 ID 去聚簇索引上找到真正的行数据,我们把这个过程称之为回表查询。
总结
在 MySQL 的 InnoDB 引擎中,每个索引都会对应一颗 B+ 树,而聚簇索引和非聚簇索引最大的区别在于叶子节点存储的数据不同,聚簇索引叶子节点存储的是行数据,因此通过聚簇索引可以直接找到真正的行数据;而非聚簇索引叶子节点存储的是主键信息,所以使用非聚簇索引还需要回表查询,因此我们可以得出聚簇索引和非聚簇索引的区别主要有以下几个:
- 聚簇索引叶子节点存储的是行数据;而非聚簇索引叶子节点存储的是聚簇索引(通常是主键 ID)。
- 聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,因此性能不如聚簇索引。
- 聚簇索引一般为主键索引,而主键一个表中只能有一个,因此聚簇索引一个表中也只能有一个,而非聚簇索引则没有数量上的限制。
到此这篇关于MySQL聚簇索引和非聚簇索引的区别详情的文章就介绍到这了,更多相关MySQL聚簇索引和非聚簇索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解MySQL 聚簇索引与非聚簇索引
1.聚集索引 表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致.对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页. 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种. 从物理文件也可以看出 InnoDB(聚集索引)的数据文件只有数据结构文件.frm和数据文件.idb 其中.idb中存放的是数据和索引信息 是存放在一起的. 2.非聚集索引 表数据存储顺序与索引顺序无关.对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,
-

MySQL之MyISAM存储引擎的非聚簇索引详解
在InnoDB中索引即数据,也就是聚簇索引的那颗B+树的叶子节点中已经包含了所有完整的用户记录.MyISAM的索引方案虽然也是使用树形结构,但是却将索引和数据分开存储,这种索引也叫非聚簇索引. create table index_demo( c1 int, c2 int, c3 char(1), primary key(c1) ) ROW_FORMAT=COMPACT; 将表中的记录按照记录的插入顺序单独存储在一个文件中,这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少个记录,这
-
MySQL聚簇索引和非聚簇索引的区别详情
目录 聚簇索引 非聚簇索引 总结 前言: 在 MySQL 默认引擎 InnoDB 中,索引大致可分为两类:聚簇索引和非聚簇索引,它们的区别也是常见的面试题,所以我们今天就来盘它们. 聚簇索引 聚簇索引(Clustered Index)一般指的是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引. 聚簇索引在 InnoDB 中是使用 B+ 树实现的,比如我们创建一张 student 表,它的构建 SQL 如下: drop table if exists student; create t
-
数据库中聚簇索引与非聚簇索引的区别[图文]
在<数据库原理>里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关.正式因为如此,所以一个表最多只能有一个聚簇索引. 不过这个定义太抽象了.在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点.而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块.如下图: 非聚簇索引 聚簇索引 聚簇索引与非聚簇索引的本质区别到底是什么?什么时候用聚簇索引,什么时候用非
-
MySQL学习教程之聚簇索引
聚簇,其实是相对于InnoDB这个数据库引擎来说的,因此在将聚簇索引的时候,我们通过InnoDB和MyISAM这两个MySQL的数据库引擎展开. InnoDB和MyISAM的数据分布对比 CREATE TABLE test (col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2)); 首先通过以上SQL语句创建出一个表格,其中col1是主键,两列数据均创建了索引.然后我们数据的主键取值为1-10000,按照随机的顺序插
-
MySQL中interactive_timeout和wait_timeout的区别
在用mysql客户端对数据库进行操作时,打开终端窗口,如果一段时间没有操作,再次操作时,常常会报如下错误: ERROR 2013 (HY000): Lost connection to MySQL server during query ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect... 这个报错信息就意味着当前的连接已经断开,需要重新建立连接. 那么,连接的时长是如何确认的?
-
全面了解mysql中utf8和utf8mb4的区别
一.简介 MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode.好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换.当然,为了节省空间,一般情况下使用utf8也就够了. 二.内容描述 那上面说了既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了.三个字节的 UT
-
Mysql中where与on的区别及何时使用详析
之前在写连表查询的时候,老是分不清楚where和on的区别,导致有时写的SQL会出现一点小的问题,这里专门写篇文章做下记录,如果你也分不清,那么请参考 二者的区别及什么时候使用 说明:区分on和where首先我们将连接分为内部连接和非内部连接,内部连接时on和where的作用是一样的,通常我们分不清它们的区别说的是非内部连接 一般on用来连接两个表,只的是连接的条件,在内部连接时,可以省略on,此时它表示的是两个表的笛卡尔积:使用on连接后,mysql会生成一张临时表,而where就是在临时表的
-
原型和原型链 prototype和proto的区别详情
目录 1.原型 2.原型链 2.1 constructor构造函数 2.2 call/apply 2.3 new() 1.原型 原型是function对象下的属性,它定义了构造函数的共同祖先,也就是一个父子级的关系,子对象会继承父对象的方法和属性 prototype是函数下的属性,对象想要查看原型使用隐式属性__Proto__ constructor指向构造函数 自己身上有属性,原型上也有属性,取近的,用自己的 通过给原型添加属性,可以让所有的实例化对象共享属性和方法 Car.prototype
-
Java抽象类和接口的区别详情
1.抽象类 vs 接口 方法类型: 接口只能有抽象方法.抽象类可以有抽象和非抽象方法.从 Java 8 开始,它也可以有默认和静态方法. 最终变量: 在 Java 接口中声明的变量默认是最终的.抽象类可能包含非最终变量. 变量类型: 抽象类可以有final.non-final.静态和非静态变量.接口只有静态和最终变量. 实现: 抽象类可以提供接口的实现.接口不能提供抽象类的实现. 继承 vs 抽象: Java 接口可以使用关键字"implements"来实现,抽象类可以使用关键字&