openstack云计算keystone架构源码分析
目录
- keystone架构
- Keystone API
- Router
- Services
- (1) Identity Service
- (2) Resource Service
- (3) Assignment Service
- (4) Token Service
- (5) Catalog Service
- (6) Policy ServicePolicy Service
- Backend Driver
- keystone管理这些概念的方法
- keystone-10.0.0代码结构展示
- keystone服务启动
- keystone详细说明
- 日志
keystone架构
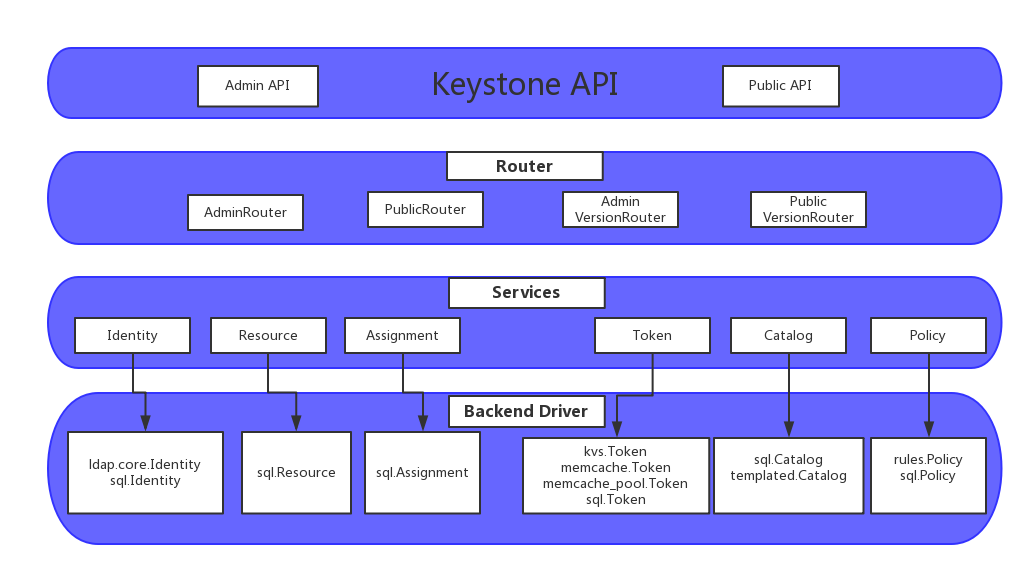
Keystone API
Keystone API与Openstack其他服务的API类似,也是基于ReSTFul HTTP实现的。
Keystone API划分为Admin API和Public API:
- Public API不仅实现获取版本以及相应扩展信息的操作,同时包括获取Token以及Token租户信息的操作;
- Admin API主要提供服务开发者使用,不仅可以完成Public API的操作,同时对User、Tenant、Role和Service Endpoint进行管理操作。
Router
Keystone Router主要实现上层API和底层服务的映射和转换功能,包括四种Router类型。
(1) AdminRouter负责将Admin API请求映射为相应的行为操作并转发至底层相应的服务执行;
(2) PublicRouter与AdminRouter类似;
(3) PublicVersionRouter对系统版本的请求API进行映射操作;
(4) AdminVersionRouter与PublicVersionRouter类似。
Services
Keystone Service接收上层不同Router发来的操作请求,并根据不同后端驱动完成相应操作,主要包括四种类型;
(1) Identity Service
Identity Service提供关于用户和用户组的授权认证及相关数据。
Keystone-10.0.0支持ldap.core.Identity,Sql.Identity两种后端驱动,系统默认的是Sql.Identity;
Users:
用户这一概念在openstack中实际上是用来标识一个使用者(an individual API consumer)
一个用户必须被一个具体的domain拥有
所有的用户名不是全局唯一的,在同一个domain中用户名才唯一
Groups:
用户组是一个包含了一系列用户的容器,一个group必须被一个具体的domain拥有
所有的组名不是全局唯一的,在同一domain种组名才唯一
(2) Resource Service
Resouse服务提供关于projects和domains的数据
projects
Projects(在v2.0中称之为Tenants)在openstack中project代表资源的结合
一个project必须被一个具体的domain所拥有
所有的project都不是全局唯一的,仅仅在一个domain中project唯一
新建一个project没有指定domain,它将被添加到默认的domain中即default
Domains
Domains是一个更高级别的包含n个projects-users-groups的容器。
默认的Domains名为Default
在v3版本中的唯一性概念
Domain名,在所有的domains中全局唯一
Role名.在所有的domains中全局唯一
User名,仅仅在它自己所在的domain中唯一
Project名,仅仅在它自己所在的domain中唯一
Group名,仅仅在它自己所在的domain中唯一
基于这些容器结构,domains代表了openstack资源的管理方式,只要某一assignment(project-user-role)被授予权限,一个domain中的用户就可以访问另外一个domain中的资源。
(3) Assignment Service
Assignment Service提供role及role assignments的数据
Roles
role角色标识了一个用户可以获得的权限级别
可以在domain或project级别授予role。
可以分配给单个用户或组级别role。
role名称是全局唯一的。
Role Assignments
A 3-tuple that has a Role, a Resource and an Identity.
Resource指的是project
Identity指的是user
Role指的是role即project-user-role
(4) Token Service
Token Service提供认证和管理令牌token的功能,用户的credentials认证通过后就得到token
Keystone-10.0.0对于Token Service支持Kvs.Token,Memcache.Token,
Memcache_pool.Token,Sql.Token四种后端驱动,系统默认的是kvs.Token
(5) Catalog Service
Catalog Service提供service和Endpoint相关的管理操作(service即openstack所有服务,endpont即访问每个服务的url)
keystone-10.0.0对Catalog Service支持两种后端驱动:Sql.Catalog、Templated.Catalog两种后端驱动,系统默认的是templated.Catalog;
(6) Policy ServicePolicy Service
提供一个基于规则的授权驱动和规则管理
keystone-10.0.0对Policy Service支持两种后端驱动:rules.Policy,sql.Policy,默认使用sql.Policy
Backend Driver
Backend Driver具有多种类型,不同的Service选择不同的Backend Driver。
官方https://docs.openstack.org/keystone/latest/#groups
keystone管理这些概念的方法
| 组件名称 | 管理对象 | 生成方法 | 保存方式 | 配置项 |
| identity | user,以及 user group | - | sql, ldap.core |
[identity] driver = keystone.identity.backends.[sql|ldap.core].Identity |
| token | 用户的临时 token | pki,pkiz,uuid | sql, kvs,memcached |
[token] driver = keystone.token.persistence.backends.[sql|kvs|memcache|memcache_pool].Token provider=keystone.token.providers.[pkiz|pki|uuid].Provider |
| credential | EC2 credential | sql |
[credential] driver = keystone.credential.backends.sql.Credential provider=keystone.token.providers.[core|fernet].Provider |
|
| catalog | region,service,endpoint | sql|templated |
[catalog] driver = keystone.catalog.backends.[sql|templated].Catalog |
|
| assignment | tenant,domain,role 以及它们与 user 之间的关系 | external, password, token | sql |
[assignment] methods = external, password, token password = keystone.auth.plugins.password.Password |
| trust | trust | sql |
[trust] driver = keystone.trust.backends.[sql].Trust |
|
| policy | Keystone service 的用户鉴权策略 | ruels|sql |
[default] policy_file = policy.json [policy] driver = keystone.policy.backends.[ruels|sql].Policy |
keystone-10.0.0代码结构展示
keystone-manage 是个 CLI 工具,它通过和 Keystone service 交互来做一些无法使用 Keystone REST API 来进行的操作,包括:
db_sync: Sync the database.
db_version: Print the current migration version of the database.
mapping_purge: Purge the identity mapping table.
pki_setup: Initialize the certificates used to sign tokens.
saml_idp_metadata: Generate identity provider metadata.
ssl_setup: Generate certificates for SSL.
token_flush: Purge expired tokens.
每个Keystone 组件,比如 catalog, token 等都有一个单独的目录。
每个组件目录中:
routes.py 定义了该组件的 routes (routes 见 探索 OpenStack 之(11):cinder-api Service 启动过程分析 以及 WSGI / Paste deploy / Router 等介绍)。
其中identity 和 assignment 分别定义了 admin 和 public 使用的 routes,分别供 admin service 和 public service 使用。
controller.py 文件定义了该组件所管理的对象,比如 assignment 的controller.py 文件定义了 Tenant、Role、Project 等类。
core.py 定了了两个类 Manager 和 Driver。Manager 类对外提供该组件操作具体对象的方法入口;
Driver 类定义了该组件需要其Driver实现类所提供的接口。
backend 目录下的每个文件是每个具体driver 的实现
下载keystone-10.0.0演示https://www.openstack.org/
keystone服务启动
Keystone is an HTTP front-end to several services. Like other OpenStack applications, this is done using python WSGI interfaces and applications are configured together usingPaste. The application’s HTTP endpoints are made up of pipelines of WSGI middleware。。。
详见:https://docs.openstack.org/keystone/latest/
/usr/bin/keystone-all 会启动 keystone 的两个service:admin and main,它们分别对应 /etc/keystone/keystone-paste.ini文件中的两个composite:

可见 admin service 提供给administrator 使用;main 提供给 public 使用。
它们分别都有 V2.0 和 V3 版本,只是目前的 keystone Cli 只支持 V2.0.比较下 admin 和 public:
| 名称 | middlewares | factory | 功能区别 |
| admin | 比 public 多s3_extension | keystone.service:public_app_factory |
从 factory 函数来看, admin service 比 public service 多了identity 管理功能, 以及 assignment 的admin/public 区别: 1. admin 多了对 GET/users/{user_id} 的支持,多了get_all_projects,get_project,get_user_roles 等功能 2. keystone 对 admin service 提供 admin extensions, 比如OS-KSADM等;对 public service 提供 public extensions。 简单总结一下, public service 主要提供了身份验证和目录服务功能;admin service 增加了 tenant、user、role、user group 的管理功能。 |
| public |
sizelimit url_normalize build_auth_context token_auth admin_token_auth xml_body_v2 json_body ec2_extension user_crud_extension |
keystone.service:admin_app_factory |
/usr/bin/keystone-all 会启动 admin 和 public 两个 service,分别绑定不同 host 和 端口。
默认的话,绑定host 都是 0.0.0.0;
admin 的绑定端口是 35357 (admin_port), public 的绑定端口是 5000 (public_port)。
因此,给 admin 使用的OS_AUTH_URL 为 http://controller:35357/v2.0,
给 public 使用的OS_AUTH_URL=http://controller:5000/v2.0
keystone详细说明
WSGI server的父进程(50511号进程)开启两个socket去分别监听本环境的5000和35357号端口,
其中5000号端口是为main的WSGI server提供的,35357号端口为admin的WSGI server提供的。
即WSGI server的父进程接收到5000号端口的HTTP请求时,则将把该请求转发给为main开启的WSGI server去处理,
而WSGI server的父进程接收到35357号端口的HTTP请求时,则将把该请求转发给为admin开启的WSGI server去处理。
vim /etc/keystone/keystone-paste.ini

日志
2016-09-14 11:53:01.037 12698 INFO keystone.common.wsgi [req-07b28d5b-084c-467e-b45a-a4c8a52b7e96 9ff041112e454cca9b54bf117a80ca29 15426931fe4746d08736c5e5c1da6b1c - 6e495643fb014e5e8a3992c69d80d234 6e495643fb014e5e8a3992c69d80d234] GET http://controller02:35357/v3/auth/tokens
(1) type = composite
这个类型的section会把URL请求分发到对应的Application,use表明具体的分发方式,比如”egg:Paste#urlmap”表示使用Paste包中的urlmap模块,这个section里的其他形式如”key = value”的行是使用urlmap进行分发时的参数。
(2) type = app
一个app就是一个具体的WSGI Application。
(3) type = filter-app
接收一个请求后,会首先调用filter-app中的use所指定的app进行过滤,如果这个请求没有被过滤,就会转发到next所指定的app进行下一步的处理。
(4) type = filter
与filter-app类型的区别只是没有next。
(5) type = pipeline
pipeline由一系列filter组成。
这个filter链条的末尾是一个app。pipeline类型主要是对filter-app进行了简化,否则,如果多个filter,就需要多个filter-app,然后使用next进行连接。OpenStack的paste的deploy的配置文件
主要采用的pipeline的方式。
因为url为http://192.168.118.1:5000/v2.0/tokens,因为基本url的后面接的信息为/v2.0,所以将到public_api的section作相应操作。
以上就是openstack云计算keystone架构源码分析的详细内容,更多关于openstack云计算keystone架构的资料请关注我们其它相关文章!
相关推荐
-

OpenStack Keystone的基本概念详细介绍
OpenStack Keystone的基本概念理解 Keystone简介 Keystone(OpenStack Identity Service)是OpenStack框架中,负责身份验证.服务规则和服务令牌的功能, 它实现了OpenStack的Identity API.Keystone类似一个服务总线, 或者说是整个Openstack框架的注册表, 其他服务通过keystone来注册其服务的Endpoint(服务访问的URL),任何服务之间相互的调用, 需要经过Keystone的身份验证, 来获
-
openstack云计算keystone组件工作流程及服务关系
目录 一 什么是keystone 二 为何要有keystone 三 keystone的功能 四 keystone概念详解 第一部分 endpoint举例 V3新增的概念: 第二部分 第三部分 五 keystone内包含的组件 六 keystone与openstack其他服务的关系 七 keystone与其他组件协同工作流程 八 keystone工作流程详解 一 什么是keystone keystone是OpenStack的身份服务,暂且可以理解为一个'与权限有关'的组件. 二 为何要有keyst
-
OpenStack Identity(Keystone)身份服务、体系结构与中间件讲解
OpenStack Identity(Keystone)服务为运行OpenStack Compute上的OpenStack云提供了认证和管理用户.帐号和角色信息服务,并为OpenStack Object Storage提供授权服务. Keystone体系结构 Keystone 有两个主要部件:验证和服务目录 验证:提供了一个基于令牌的验证服务,主要有以下几个概念: 租户(Tenant) 使用OpenStack相关服务的一个组织.一个租户映射到一个Nova的"project-id",在对
-
openstack云计算组件keystone部署及操作使用技巧
目录 一 前言 二 版本信息 三 部署keystone step 1:准备阶段 step 2:部署mariadb step 3:部署keystone step 4:配置web server整合keystone 四 keystone操作 part 1:创建keystone的catalog part 2:创建域,租户,用户,角色,把四个元素关联到一起 part 3:使用Bootstrap完成part1和part2二者的工作 part 4:创建用于后期测试用的项目,用户,租户,建立关联 part 5:
-
openstack云计算keystone架构源码分析
目录 keystone架构 Keystone API Router Services (1) Identity Service (2) Resource Service (3) Assignment Service (4) Token Service (5) Catalog Service (6) Policy ServicePolicy Service Backend Driver keystone管理这些概念的方法 keystone-10.0.0代码结构展示 keystone服务启动 key
-
Flink部署集群整体架构源码分析
目录 概览 部署模式 Application mode 客户端提交请求 服务端启动&提交Application session mode Cluster架构 Cluster的启动流程 DispatcherResourceManagerComponent Runner代码 HA代码框架 总结 概览 本篇我们来了解Flink的部署模式和Flink集群的整体架构 部署模式 Flink支持如下三种运行模式 运行模式 描述 Application Mode Flink Cluster只执行提交的整个job
-
Hadoop源码分析五hdfs架构原理剖析
目录 1. hdfs架构 如果在hadoop配置时写的配置文件不同,启动的服务也有所区别 namenode的下方是三台datanode. namenode左右两边的是两个zkfc. namenode的上方是三台journalnode集群. 2. namenode介绍 namenode作为hdfs的核心,它主要的作用是管理文件的元数据 文件与块的对应关系中的块 namenode负责管理hdfs的元数据 namenode的数据持久化,采用了一种日志加快照的方式 最后还会有一个程序读取这个快照文件和日
-
Hadoop源码分析一架构关系简介
1. 简介 Hadoop是一个由Apache基金会所开发的分布式系统基础架构 Hadoop起源于谷歌发布的三篇论文:GFS.MapReduce.BigTable.其中GFS是谷歌的分布式文件存储系统,MapReduce是基于这个分布式文件存储系统的一个计算框架,BigTable是一个分布式的数据库.hadoop实现了论文GFS和MapReduce中的内容,Hbase的实现了参考了论文BigTable. 2. hadoop架构 hadoop主要有三个组件 HDFS.YARN和MapReduce.其
-
MyBatis 源码分析 之SqlSession接口和Executor类
mybatis框架在操作数据的时候,离不开SqlSession接口实例类的作用.可以说SqlSession接口实例是开发过程中打交道最多的一个类.即是DefaultSqlSession类.如果笔者记得没有错的话,早期是没有什么getMapper方法的.增删改查各志有对应的方法进行操作.虽然现在改进了很多,但是也保留了很多.我们依旧可以看到类似于selectList这样子的方法.源码的例子里面就可以找到.如下 SqlSession session = sqlMapper.openSession(T
-
Java struts2请求源码分析案例详解
Struts2是Struts社区和WebWork社区的共同成果,我们甚至可以说,Struts2是WebWork的升级版,他采用的正是WebWork的核心,所以,Struts2并不是一个不成熟的产品,相反,构建在WebWork基础之上的Struts2是一个运行稳定.性能优异.设计成熟的WEB框架. 我这里的struts2源码是从官网下载的一个最新的struts-2.3.15.1-src.zip,将其解压即可.里面的目录页文件非常的多,我们只需要定位到struts-2.3.15.1\src\core
-
Hadoop源码分析四远程debug调试
1. hadoop远程debug 从文档(3)中可以知道hadoop启动服务的时候最终都是通过java命令来启动的,其本质是一个java程序.在研究源码的时候debug是一种很重要的工具,但是hadoop是编译好了的代码,直接在liunx中运行的,无法象普通的程序一样可以直接在eclipse之类的工具中直接debug运行. 对于上述情况java提供了一种远程debug的方式. 这种方式需要在java程序启动的时候添加以下参数: -agentlib:jdwp=transport=dt_socket
-
使用dynamic-datasource-spring-boot-starter实现多数据源及源码分析
简介 前两篇博客介绍了用基本的方式做多数据源,可以应对一般的情况,但是遇到一些复杂的情况就需要扩展下功能了,比如:动态增减数据源.数据源分组,纯粹多库 读写分离 一主多从.从其他数据库或者配置中心读取数据源等等.其实就算没有这些需求,使用这个实现多数据源也比之前使用AbstractRoutingDataSource要便捷的多 dynamic-datasource-spring-boot-starter 是一个基于springboot的快速集成多数据源的启动器. github: https://g
-
使用dynamic datasource springboot starter实现多数据源及源码分析
目录 简介 实操 基本使用 集成druid连接池 service嵌套 为什么切换数据源不生效或事务不生效? 源码分析 整体结构 自动配置怎么实现的 如何集成众多连接池的 DS注解如何被拦截处理的 多数据源动态切换及如何管理多数据源 数据组的负载均衡怎么做的 如何自定义数据配置来源 如何动态增减数据源 总结 简介 前两篇博客介绍了用基本的方式做多数据源,可以应对一般的情况,但是遇到一些复杂的情况就需要扩展下功能了,比如:动态增减数据源.数据源分组,纯粹多库 读写分离 一主多从.从其他数据库或者配置