python爬取youtube视频的示例代码
这几天正在追剧,原名《大秦帝国之天下》的《大秦赋》,看着看着又想把前几部刷一遍了,但第一部《裂变》自己没有高清资源,搜了一波发现youtube上有个48集版的高清资源,有删减就有删减吧,就想着写个脚本批量下载一下,记录一下过程,主要是youtube1080p及以上的分辨率做了音视频分离,下载后需要用ffmpeg做一次音视频融合。参考了pytube模块。
1.下载音视频数据
pytube可以通过pip安装
$pip install pytube
from pytube import YouTube
url = 'https://www.youtube.com/watch?v=K5KG4FVaD5M&list=PLtt_YYUGi1gVlXrNAOQX5BsIXAeTdTrwj&index={}'.format(i)
result = YouTube(url)
print(url + ' ' + result.title)
result.streams.get_by_itag(137).download('D:/xdedzl/movie/video')
print('done {} video'.format(i))
result.streams.get_by_itag(251).download('D:/xdedzl/movie/audio')
print('done {} audio'.format(i))
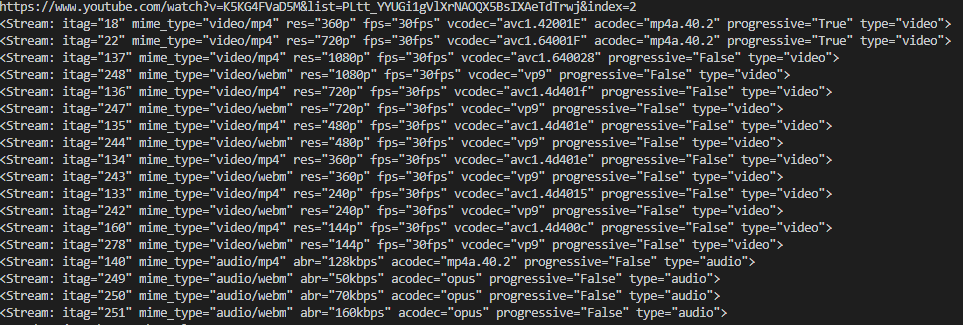
result.steams是一系列不同质量的音视频数据,打印出来如下图,可以根据get_by_itag来拿到对应的音视频,137对应1080p的视频,251对应160k的音频
2.融合音视频数据
使用ffmpeg融合音视频,命令如下,具体使用方式可自行查阅
ffmpeg -i video_path -i audio_path -c:v copy -c:a aac -strict -2 output_path
写了个批处理融合了48集的音视频
echo off set v=D:\xdedzl\movie\video\ set a=D:\xdedzl\movie\audio\ set o=D:\xdedzl\movie\ set /a i=1, b=49 :SymLoop if %i% LSS %b% ( echo %v%%i%.mp4 echo %a%%i%.webm echo %o%%i%.mp4 ffmpeg -i %v%%i%.mp4 -i %a%%i%.webm -c:v copy -c:a aac -strict -2 %o%%i%.mp4 set /a "i+=1" GOTO :SymLoop ) pause
到此这篇关于python爬取youtube视频的文章就介绍到这了,更多相关python爬取youtube视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取某拍短视频
一.抓取目标 目标网址:美拍视频 二.工具使用 开发环境:win10.python3.7 开发工具:pycharm.Chrome 工具包:requests.xpath.base64 三.重点学习内容 爬虫采集数据的解析过程 js代码调试技巧 js逆向解析代码 Python代码的转换 四.项目思路解析 进入到网站的首页 挑选你感兴趣的分类 根据首页地址获取到进入详情页面的超链接的跳转地址 找到对应加密的视频播放地址数据 这个数据是静态的网页数据,通过js代码进行解码的 找到对应的解析代码 先找到视
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
python爬取抖音视频的实例分析
现在抖音的火爆程度,大家都是有目共睹的吧,之前小编在网络上发现好玩的事情,就是去爬取一些网站,因此,也考虑能否进行抖音上的破案去,在实际操作以后,真的实现出来了,利用自动化工具,就可以轻松实现了,后有小伙伴提出把appium去掉瘦身之后也是可以实现的,那么看下详细操作内容吧. 1.mitmproxy/mitmdump抓包 import requests path = 'D:/video/' num = 1788 def response(flow): global num target_urls
-
使用python爬取抖音app视频的实例代码
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
基于python爬取梨视频实现过程解析
目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8.其实你要哪一页都行,你喜欢就行.嘿嘿- 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,想要锻炼的可以找找看哈: https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0 这个就是我们要找的目标网址啦,后面的0就代表页数,让
-
Python爬取腾讯视频评论的思路详解
一.前提条件 安装了Fiddler了(用于抓包分析) 谷歌或火狐浏览器 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器 有Python的编译环境,一般选择Python3.0及以上 声明:本次爬取腾讯视频里 <最美公里>纪录片的评论.本次爬取使用的浏览器是谷歌浏览器 二.分析思路 1.分析评论页面 根据上图,我们可以知道:评论使用了Ajax异步刷新技术.这样就不能使用以前分析当前页面找出规律的手段了.因为展示的页面只有部分评论,还有大量的评论没有被刷新出
-
Python爬取视频(其实是一篇福利)过程解析
窗外下着小雨,作为单身程序员的我逛着逛着发现一篇好东西,来自知乎 你都用 Python 来做什么?的第一个高亮答案. 到上面去看了看,地址都是明文的,得,赶紧开始吧. 下载流式文件,requests库中请求的stream设为True就可以啦,文档在此. 先找一个视频地址试验一下: # -*- coding: utf-8 -*- import requests def download_file(url, path): with requests.get(url, stream=True) as
-
Python爬取梨视频的示例
爬取流程(美食区最热标签下的三个视频) 在首页获取视频的编号和名字 拼接成正确的url 保存视频 思路 1.从网页中获取视频的url 发现视频的url在id为"JprismPlayer"的div标签下的video标签src属性中,xpath解析网页 video_url = tree.xpath("//div[@id='JprismPlayer']/video/@src") 但得到的返回值为空,也就是说这个video标签在原网页中并不存在,很可能是动态加载出来的 2.
-
Python爬取某平台短视频的方法
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 基本开发环境 Python 3.6 Pycharm 相关模块的使用 import os import requests 安装Python并添加到环境变量,pip安装需要的相关模块即可. 一.确定需求 爬取搞笑趣味栏目的视频内容. 二.网站数据分析 首先需要明确一点,好看视频网站加载方式是懒加载的方式,需要你下滑网页才会加载出新的内容 加载出来的内容里面有音频播放地址以及标题. 内容比较简单
-
python爬取youtube视频的示例代码
这几天正在追剧,原名<大秦帝国之天下>的<大秦赋>,看着看着又想把前几部刷一遍了,但第一部<裂变>自己没有高清资源,搜了一波发现youtube上有个48集版的高清资源,有删减就有删减吧,就想着写个脚本批量下载一下,记录一下过程,主要是youtube1080p及以上的分辨率做了音视频分离,下载后需要用ffmpeg做一次音视频融合.参考了pytube模块. 1.下载音视频数据 pytube可以通过pip安装 $pip install pytube from pytube
-
python爬取音频下载的示例代码
抓取"xmly"鬼故事音频 import json # 在这个url,音频链接为JSON动态生成,所以用到了json模块 import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36" } # 请求网页
-
使用Python爬取Json数据的示例代码
一年一度的双十一即将来临,临时接到了一个任务:统计某品牌数据银行中自己品牌分别在2017和2018的10月20日至10月31日之间不同时间段的AIPL("认知"(Aware)."兴趣"(Interest)."购买"(Purchase)."忠诚"(Loyalty))流转率. 使用Fiddler获取到目标地址为: https://databank.yushanfang.com/api/ecapi?path=/databank/cr
-
Python爬取豆瓣视频信息代码实例
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quotefrom pyquery import PyQuery as pqimport requestsimport pandas as pddef get_text_page (movie_name)
-
Python爬取网页信息的示例
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初始网址,逐层查找链接,直到找到需要获取的内容. 在打开的界面中,点击鼠标右键,在弹出的对话框中,选择"检查",则在界面会显示该网页的源代码,在具体内容处点击查找,可以定位到需要查找的内容的源码. 注意:代码显示的方式与浏览器有关,有些浏览器不支持显示源代码功能(360浏览器,谷歌浏览器,火
-
python爬取梨视频生活板块最热视频
完整代码如下: import requests from lxml import etree import random import os from multiprocessing.dummy import Pool if not os.path.exists('./视频'): os.mkdir('./视频') urls=[] url='https://www.pearvideo.com/category_5' headers={'user-agent':'Mozilla/5.0 (Windo
-
python 爬取壁纸网站的示例
本次爬虫用到的网址是: http://www.netbian.com/index.htm: 彼岸桌面.里面有很多的好看壁纸,而且都是可以下载高清无损的,还比较不错,所以我就拿这个网站练练手. 作为一个初学者,刚开始的时候,无论的代码的质量如何,总之代码只要能够被正确完整的运行那就很能够让自己开心的,如同我们的游戏一样,能在短时间内得到正向的反馈,我们就会更有兴趣去玩. 学习也是如此,只要我们能够在短期内得到学习带来的反馈,那么我们的对于学习的欲望也是强烈的. 作为一个菜鸡,能够完整的完整此次爬虫
-
python 爬取豆瓣网页的示例
python作为一种已经广泛传播且相对易学的解释型语言,现如今在各方面都有着广泛的应用.而爬虫则是其最为我们耳熟能详的应用,今天笔者就着重针对这一方面进行介绍. python 语法简要介绍 python 的基础语法大体与c语言相差不大,由于省去了c语言中的指针等较复杂的结构,所以python更被戏称为最适合初学者的语言.而在基础语法之外,python由其庞大的第三方库组成,而其中包含多种模块,而通过模块中包含的各种函数与方法能够帮助我们实现各种各样的功能. 而在python爬虫中,我们需要用到的
-
python绘制字符画视频的示例代码
目录 读取视频 转为字符 动画 已经11月了,不知道还有没有人看华强买瓜...要把华强卖瓜做成字符视频,总共分为三步 读取视频 把每一帧转为字符画 把字符画表现出来 读取视频 通过imageio读取视频,除了pip install imageio之外,还需要pip install imageio-ffmpeg. 由于视频中的图像都是彩色的,故而需要将rgb三色转为单一的强度,并将转化后的图像装入一个列表中. import imageio import numpy as np import mat