关于Java HashMap自动排序的简单剖析
1.HashMap概述
HashMap是无序的,这里无序的意思是你取出数据的顺序与你存入数据的顺序不同
2.发现问题
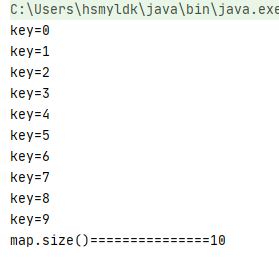
当尝试向HashMap中存入int类型的key,可以看到在输出的时候会自动排序
HashMap<Integer, String> map = new HashMap<>(); map.put(3, "asdf"); map.put(2, "asdf"); map.put(1, "asdf"); map.put(6, "asdf"); map.put(5, "asdf"); map.put(4, "asdf"); map.put(8, "asdf"); map.put(9, "asdf"); map.put(7, "asdf"); map.put(0, "asdf");
输出
3.实现原理
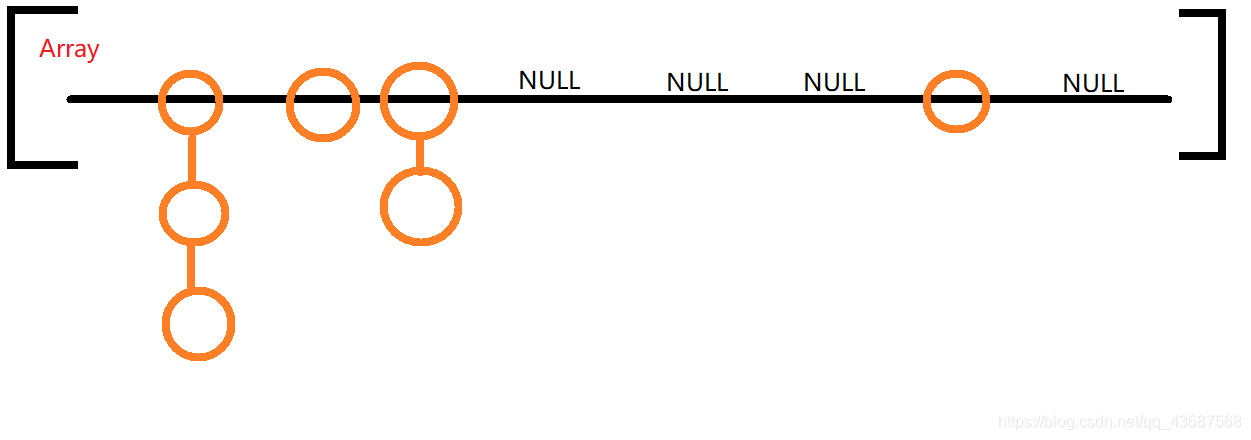
我们都知道,HashMap是数组加链表实现的,在链表长度大于8的时候将链表转化为红黑树
数组加链表画一下模型图是这样的,黑色的是数组,橙色的是链表,遍历HashMap的key的时候,先遍历第一列,然后第二列。。。
4.翻看源码
HashMap的默认数组长度为16,默认负载因子是0.75,意思就是当数组内不为null的元素大于(数组长度*负载因子)的时候就会拓容数组
如果数组长度和负载因子都是默认值,那当在数组中存入第13个元素后就会拓容16*0.75=12
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
再读一下put方法和hash方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//获取key的hash,当key为int类型的时候hash=key的值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//tab就是HashMap的数组,这句话就是初始化数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果根据hash值来判断将此元素放在什么位置,如果数组当前位置
//为空直接存放,成为一个长度为一的链表
if ((p = tab[i = (n - 1) & hash]) == null)//==================
tab[i] = newNode(hash, key, value, null);
//如果不是,则将当前元素放在当前位置下元素的后边形成链表
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
//拓容数组
resize();
afterNodeInsertion(evict);
return null;
}
5.分析
17行:if ((p = tab[i = (n - 1) & hash]) == null)
(n - 1) & hash
n-1就是数组的length-1,现在数组长度是16,
15&hash,
例如,现在存入key为1,
15转成二进制为1111
1 转成二进制为0001,
所以i=15&1=1;
现在1就存放在数组下标为1的位置
如果放2,那就放在数组下标为2的位置,
如果再存放17的话,
1501111
1710001
15&17=1;因为数组下标1的位置有上一次存放的key为1的元素,所以就将key=17的元素挂在key=1的下边,
这是遍历HashMap的key就会变成1,17,2
顺序就会乱掉,现在数组的长度是16,已使用的是2,还没有达到拓容那一步,
6.验证
下边的代码是存放11个数据,拓容要存入第13个数据时进行拓容
HashMap<Integer, String> map = new HashMap<>();
map.put(3, "asdf");
map.put(2, "asdf");
map.put(1, "asdf");
map.put(6, "asdf");
map.put(5, "asdf");
map.put(4, "asdf");
map.put(8, "asdf");
map.put(9, "asdf");
map.put(7, "asdf");
map.put(0, "asdf");
map.put(17,"saf");
// map.put(10,"saf");
// map.put(11,"saf");
for (int i : map.keySet()) {
System.out.println("key=" + i);
}
System.out.println("map.size()===============" + map.size());
下边这段代码的输出结果就是
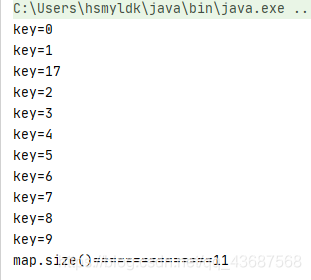
和分析的一样,
如果再添加两个数据,使其拓容
HashMap<Integer, String> map = new HashMap<>();
map.put(3, "asdf");
map.put(2, "asdf");
map.put(1, "asdf");
map.put(6, "asdf");
map.put(5, "asdf");
map.put(4, "asdf");
map.put(8, "asdf");
map.put(9, "asdf");
map.put(7, "asdf");
map.put(0, "asdf");
map.put(17,"saf");
// map.put(10,"saf");
// map.put(11,"saf");
for (int i : map.keySet()) {
System.out.println("key=" + i);
}
System.out.println("map.size()===============" + map.size());
输出是
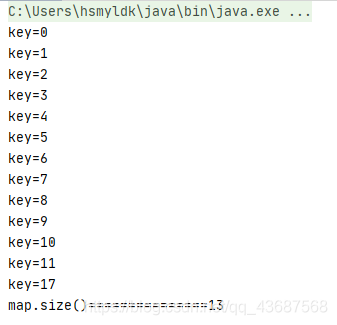
又排好了顺序
7.结论
当所有key的hash的最大值<数组的长度-1时HashMap可以将存入的元素按照key的hash从小到大排序
不过这个发现没有什么用就是了,不过看了一天源码收获不少,还看到好几种没见过的写法
到此这篇关于关于Java HashMap自动排序简单剖析的文章就介绍到这了,更多相关Java HashMap自动排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java使用LinkedHashMap进行分数排序
分数排序的特殊问题 在java中实现排序远比C/C++简单,我们只要让集合中元素对应的类实现Comparable接口,然后调用Collections.sort();方法即可. 这种方法对于排序存在许多相同元素的情况有些浪费,明显即使值相等,两个元素之间也要比较一下,这在现实中是没有意义的. 典型例子就是学生成绩统计的问题,例如高考中,满分是150,成千上万的学生成绩都在0-150之间,平均一个分数的人数成百上千,这时如果排序还用传统方法明显就浪费了. 进一步思考 成绩既然有固定的分数等级,我们可
-
Java HashMap两种简便排序方法解析
这篇文章主要介绍了Java HashMap两种简便排序方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 HashMap的储存是没有顺序的,而是按照key的HashCode实现. key=手机品牌,value=价格,这里以这个例子实现按名称排序和按价格排序. Map phone=new HashMap(); phone.put("Apple",8899); phone.put("SAMSUNG",7000);
-
Android中实现HashMap排序的方法
HashMap排序是数据结构与算法中常见的一种排序算法.本文即以Android平台为例来实现该算法. 具体代码如下: public static void main(String[] args) { Map<String, Integer> map = new HashMap<String, Integer>(); map.put("lisi", 5); map.put("lisi1", 1); map.put("lisi2&quo
-
关于Java HashMap自动排序的简单剖析
1.HashMap概述 HashMap是无序的,这里无序的意思是你取出数据的顺序与你存入数据的顺序不同 2.发现问题 当尝试向HashMap中存入int类型的key,可以看到在输出的时候会自动排序 HashMap<Integer, String> map = new HashMap<>(); map.put(3, "asdf"); map.put(2, "asdf"); map.put(1, "asdf"); map.pu
-
java String[]字符串数组自动排序的简单实现
如下所示: import java.util.Arrays; public class xulie { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub String []str = {"abc","bca","cab","cba","aaa","111&
-
java几种排序算法的实现及简单分析
本文实例讲述了java几种排序算法的实现及简单分析.分享给大家供大家参考.具体如下: package test; public class first { /*普通的插入排序*/ public void insertSort(int[] list) { int i, j; list[0] = -999; //相当于设置一个监视哨兵,不用判断是否越界, //但要求数组从第二个数开始即i=1开始存储 for (i = 1; i < list.length; i++) { j = i; while (
-
java字符串数组进行大小排序的简单实现
若是将两个字符串直接比较大小,会包:The operator > is undefined for the argument type(s) java.lang.String, java.lang.String的错误. 字符串比较大小可以用字符串长度或者是比较字符串内字符的ASCII码值,前者太简单,就不进行讲述记录. 字符串用ASCII码比较大小,规则是: 1.比较首字母的ASCII码大小 2.若是前面的字母相同,则比较之后的字母的ASCII码值 3.若是一个字符串从首字母开始包含另一个字符串
-
java数据结构与算法之简单选择排序详解
本文实例讲述了java数据结构与算法之简单选择排序.分享给大家供大家参考,具体如下: 在前面的文章中已经讲述了交换类的排序算法,这节中开始说说选择类的排序算法了,首先来看一下选择排序的算法思想: 选择排序的基本算法思想: 每一趟在 n-i+1 (i=1,2,3,--,n-1)个记录中选取关键字最小的记录作为有序序列中第i个记录. 简单选择排序: 设所排序序列的记录个数为n.i取1,2,-,n-1,从所有n-i+1个记录(Ri,Ri+1,-,Rn)中找出排序码最小的记录,与第i个记录交换.执行n-
-
Java 对HashMap进行排序的三种常见方法
首先来看看Map集合获取元素的三种常见方法keySet().values().entrySet() 1. values(): 返回map集合的所有value的Collection集合(于集合中无序存放) import java.util.*; public class Main{ public static void main(String[] args){ Map<String, String> map = new HashMap<String, String>(); //构建键
-

Java HashMap的工作原理
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.HashMap的大量源代码(包括Java 7 和Java 8),来深入理解这个基础的数据结构.在这篇文章中,我会解释java.util.HashMap的实现,描述Java 8实现中添加的新特性,并讨论性能.内存以及使用HashMap时的一些已知问题. 内部存储 Java HashMap类实现了Map<K
-
Java 使用maven实现Jsoup简单爬虫案例详解
一.Jsoup的简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 二.我们可以利用Jsoup做什么 2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据, 2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本 2.3从而使我们输出我们想要的整洁文本 三.利用Jsoup爬
-
java中元素排序Comparable和Comparator的区别
目录 Comparable Comparator 总结 初次碰到这个问题是之前有一次电话面试,问了一个小时的问题,其中有一个问题就问到Comparable和Comparator的区别,当时没答出 来.之后是公司入职时候做的一套Java编程题,里面用JUnit跑用例的时候也用到了Comparator接口,再加上JDK的大量的类包括常见的 String.Byte.Char.Date等都实现了Comparable接口,因此要学习一下这两个类的区别以及用法. Comparable Comparable可