Python HTMLTestRunner如何下载生成报告
HTMLTestRunner下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html,选择HTMLTestRunner.py下载
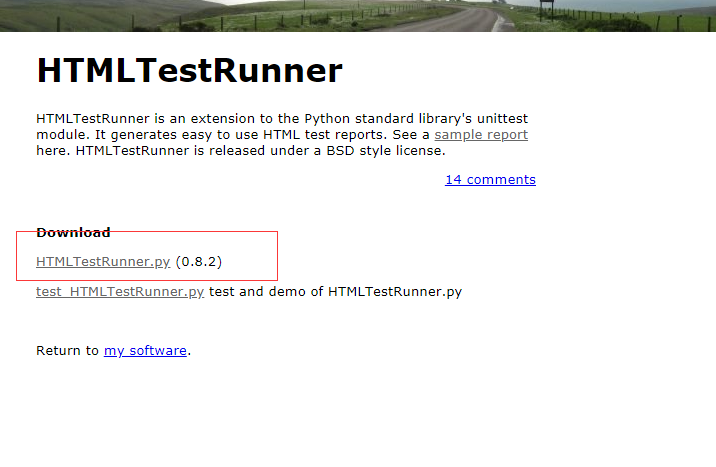
2.打开显示这个样子滴,这里需要注意右击另存为pycharm的Lib\site-packages目录下(不然是没有用滴)


3.我使用的是python 3.7(看别人说需要改文件)
第94行,将import StringIO修改成import io
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
第766行,将uo = o.decode('latin-1')修改成uo = e
第775行,将ue = e.decode('latin-1')修改成ue = e
第631行,将print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime)修改成print(sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
4.使用pip命令(前提是已经安装过pip)安装下pip install html-testRunner(因为我已经安装过啦所以提示下面内容)

5.安装成功后在交互界面验证下没提示就OK啦

找到保存目录最后结果:

不要像我粗心哦,配置文件一定要配对,配错也不要慌,大不了删除从新下载配置
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python使用HTMLTestRunner导出饼图分析报告的方法
目录如下: 这里有使用 HTMLTestRunner和 echarts.common.min.js文件[见百度网盘,这里给自己留个记录便于查询] unit_test.py代码如下: import unittest import requests import time import os.path from common import HTMLTestRunner class TestLogin(unittest.TestCase): def setUp(self): # 获取session对象
-
解决python3运行selenium下HTMLTestRunner报错的问题
修改HTMLTestRunner.py以支持python3+ 搜索到的结果整理 修改一: 在python shell里输入 >>>import HTMLTestRunner >>> dir(HTMLTestRunner) 发现不认识StringIO (No module named StringIO) 确实3里面没有这个了,第94行引入的名称要改,改成import io,539行要改成self.outputBuffer = io.BytesIO() 修改二: 运行程序的
-
详解python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'如何解决
python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'的解决方法: 1.原因是官网的是python2语法写的,看官手动把官网的HTMLTestRunner.py改成python3的语法: 参考:http://bbs.chinaunix.net/thread-4154743-1-1.html 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 修改后下载地址:
-
Python HTMLTestRunner测试报告view按钮失效解决方案
背景 HTMLTestRunner 生成测试报告后,发现点击 view 这个按钮一直没有反应 通过 F12 开发人员工具检查,发现是 jQuery 文件没有加载出来 解决方法 我采用的解决方法是直接修改源代码 1.打开Python的安装环境 2.进入 lib 文件夹 3.进入 site-packages 文件夹 4.进入 HtmlTestRunner 文件夹 5.进入 template 文件夹 6.进入记事本等编辑工具打开 report_template.html 文件 7.在文件的 142 行
-
Python HTMLTestRunner库安装过程解析
安装 HTMLTestRunner 库的方法非常简单,直接 pip 就可以了 pip install html-testRunner 在 https://pypi.org/ 中可以直接搜索到,并且官方还提供了详细的文档,操作起来非常的简单 官方示例代码: import HtmlTestRunner import unittest class TestStringMethods(unittest.TestCase): def test_upper(self): self.assertEqual('
-

python使用 HTMLTestRunner.py生成测试报告
本文介绍了python使用 HTMLTestRunner.py生成测试报告 ,分享给大家,具体如下: HTMLTestRunner.py python 2版本 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 使用时,先建立一个"PyDev Package",将下载下来的HTMLTestRunner.py文件拷贝在该目录下. 例子:testcase5_dynamic.py import unittest from dev.
-
Python HTMLTestRunner可视化报告实现过程解析
操作步骤 1.下载HTMLTestRunner.py 2.把文件复制到python安装/lib位置下 3. 3.导入:import HTMLTestRunner import unittest 4.mian执行: 1.实例化:ts = unittest.TestSuite() 2.按类加载全部testxxx测试用例:ts.addTest(unittest.TestLoader().loadTestsFromTestCase(类名)) 按函数加载testxxx测试用例:ts.addTest(类名(
-
解决python3 HTMLTestRunner测试报告中文乱码的问题
使用HTMLTestRunner输出的测试报告中,标题和错误说明的中文乱码. 环境: python v3.6 HTMLTestRunner v0.8.2 定位问题 刚开始以为是python3对HTMLTestRunner文件兼容的问题.网上搜了一些解决办法基本都是说python2的,对比看了一下,我这边兼容性是可以的. 接下来,查看HTMLTestRunner文件输出,倒着去找,最后问题定位到: self.stream.write(output) 这一行,print(output)是正常输出中文
-
Python HTMLTestRunner如何下载生成报告
HTMLTestRunner下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html,选择HTMLTestRunner.py下载 2.打开显示这个样子滴,这里需要注意右击另存为pycharm的Lib\site-packages目录下(不然是没有用滴) 3.我使用的是python 3.7(看别人说需要改文件) 第94行,将import StringIO修改成import io 第539行,将self.outputBuffer = String
-
python selenium执行所有测试用例并生成报告的方法
直接上代码. # -*- coding: utf-8 -*- import time import os import os.path import re import unittest import HTMLTestRunner import shutil shutil.copyfile("setting.ini","../setting.ini") casepaths = [] def createsuite(casepath): testunit = unit
-
Python基于QRCode实现生成二维码的方法【下载,安装,调用等】
本文实例讲述了Python基于QRCode实现生成二维码的方法.分享给大家供大家参考,具体如下: QR码是一种矩阵码,或二维空间的条码,1994年由日本Denso-Wave公司发明.QR是英文Quick Response的缩写,即快速反应的意思,源自发明者希望QR码可让其内容快速被解码.QR码常见於日本,并为目前日本最流行的二维空间条码.QR码比普通条码可储存更多资料,亦无需像普通条码般在扫描时需直线对准扫描器. qrcode是Python的第三方模块,依赖于Python 图像库:PIL(Pyt
-
Python实现html转换为pdf报告(生成pdf报告)功能示例
本文实例讲述了Python实现html转换为pdf报告(生成pdf报告)功能.分享给大家供大家参考,具体如下: 1.先说下html转换为pdf:其实支持直接生成,有三个函数pdfkit.f 安装python包:pip Install pdfkit 系统安装wkhtmltopdf:参考 https://github.com/JazzCore/python-pdfkit/wiki/Installing-wkhtmltopdf mac下的wkhtmltopdf: brew install Caskro
-
Python实现的文本对比报告生成工具示例
本文实例讲述了Python实现的文本对比报告生成工具.分享给大家供大家参考,具体如下: 借助于difflib的功能,可以针对我们的使用情况进一步进行功能的聚合.我想要的功能是输入两个文件名以及一个输出报告的文件名之后,运行直接给出最终的报告. 代码实现如下: import sys import difflib try: file1 = sys.argv[1] file2 = sys.argv[2] report = sys.argv[3] except Exception,e: print('E
-
Python操作Word批量生成文章的方法
下面通过COM让Python与Word建立连接实现Python操作Word批量生成文章,具体介绍请看下文: 需要做一些会议记录.总共有多少呢?五个地点x7个月份x每月4篇=140篇.虽然不很重要,但是140篇记录完全雷同也不好.大体看了一下,此类的记录大致分为四段.于是决定每段提供四种选项,每段从四选项里随机选一项,拼凑成四段文字,存成一个文件.而且要打印出来,所以准备生成一个140页的Word文档,每页一篇. 需要用到win32com模块(下载链接: http://sourceforge.ne
-
Python脚本实现下载合并SAE日志
由于一些原因,需要SAE上站点的日志文件,从SAE上只能按天下载,下载下来手动处理比较蛋疼,尤其是数量很大的时候.还好SAE提供了API可以批量获得日志文件下载地址,刚刚写了python脚本自动下载和合并这些文件 调用API获得下载地址 文档位置在这里 设置自己的应用和下载参数 请求中需要设置的变量如下 复制代码 代码如下: api_url = 'http://dloadcenter.sae.sina.com.cn/interapi.php?' appname = 'xxxxx' from_da
-
python实现批量下载新浪博客的方法
本文实例讲述了python实现批量下载新浪博客的方法.分享给大家供大家参考.具体实现方法如下: # coding=utf-8 import urllib2 import sys, os import re import string from BeautifulSoup import BeautifulSoup def encode(s): return s.decode('utf-8').encode(sys.stdout.encoding, 'ignore') def getHTML(url
-
Python及Django框架生成二维码的方法分析
本文实例讲述了Python及Django框架生成二维码的方法.分享给大家供大家参考,具体如下: 一.包的安装和简单使用 1.1 用Python来生成二维码很简单,可以看 qrcode 这个包: pip install qrcode qrcode 依赖 Image 这个包: pip install Image 如果这个包安装有困难,可选纯Python的包来实现此功能,见下文. 1.2 安装后就可以使用了,这个程序带了一个 qr 命令: qr 'http://www.ziqiangxuetang.c