Python 随机生成测试数据的模块:faker基本使用方法详解
本文实例讲述了Python 随机生成测试数据的模块:faker基本使用方法。分享给大家供大家参考,具体如下:
本文内容:
- faker的介绍
- faker的使用
- 小例子:生成随机的数据表信息
首发日期:2018-06-15
faker介绍:
- faker是python的一个第三方模块,是一个github上的开源项目。
- 主要用来创建一些测试用的随机数据。
官方文档:https://faker.readthedocs.io/en/master/index.html
faker的使用:
1.安装模块
pip3 install Faker
【使用faker也能识别成功,不过新版已经更新为Faker】
2.导入模块
from faker import Faker
【主要使用的是Factory类,而导入Faker,会同时导入Factory】

3.使用步骤:
- 3.1初始化:
fake=Faker()
- Faker()调用的是Factory的create方法,常用参数选项:

- 用于生成本地化数据:locale【默认情况下是en_US,所以生成的数据是美式英文的】
- zh-CN代表使用中国版
- 想了解更多国家版本,可以参考 https://faker.readthedocs.io/en/master/index.html#localization
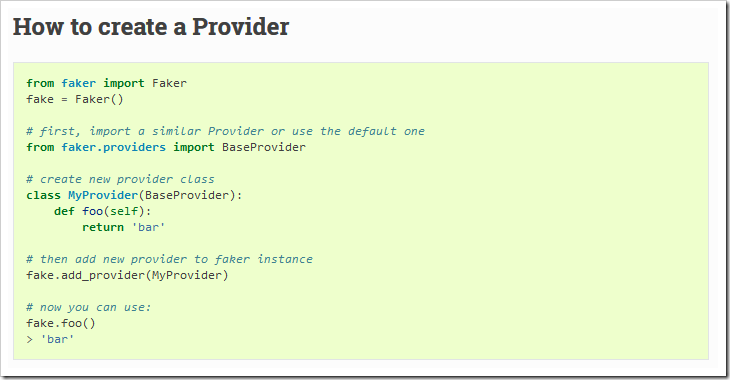
- providers是一个包含了多种生成随机数据的生成器的“提供者”,比如他包含了生产随机姓名的生成器,包含了随机地址的生成器。如果我们想要自己定义随机生成的数据的规则,那么我们需要自定义providers。如何生成一个providers,可以参考https://faker.readthedocs.io/en/master/index.html#how-to-create-a-provider
- 用于生成本地化数据:locale【默认情况下是en_US,所以生成的数据是美式英文的】
- Faker()调用的是Factory的create方法,常用参数选项:
- 3.2.调用方法:
- 利用Faker对象调用方法,调用方法的返回值就是随机的数据。
- 不同的数据需要调用不同的方法,常见方法参见下面。
from faker import Faker
# fake=Faker() #默认生成美国英文数据
fake=Faker(locale='zh_CN')
# 地址类
print("地址类".center(20,"-"))
print(fake.address())#海南省成市丰都深圳路p座 425541
print(fake.street_address())#深圳街X座
print(fake.street_name())#长沙路
print(fake.city_name(),fake.city())#兰州 贵阳市 (相差“市”)
print(fake.province())#陕西省
#公司类:
print("公司类".center(20,"-"))
print(fake.company())#惠派国际公司信息有限公司
print(fake.company_suffix())#网络有限公司
print(fake.company_prefix())#鑫博腾飞
#个人信息类
print("个人信息类".center(20,"-"))
print(fake.name())#东浩
print(fake.simple_profile())
#{'username': 'leihan', 'name': '武帅', 'sex': 'F', 'address': '吉林省淮安市双滦家街C座 210434', 'mail': 'lishao@hotmail.com', 'birthdate': '1988-11-12'}
print(fake.user_name(),fake.password(special_chars=False))#ajiang zI2QbHy02p
#文章类
print("文章类".center(20,"-"))
print(fake.word())#当前
print(fake.words(3))#['欢迎', '支持', '图片']
print(fake.sentence(3))#精华有关一些.
print(fake.paragraph())#大家电话空间一起操作图片要求.上海发展到了之间用户也是的人.必须记者关系介绍注册.用户时候投资发布.
常用方法:
https://faker.readthedocs.io/en/master/locales/zh_CN.html 由于主要使用中文数据,所以提供常见的方法示例是中文的。想要了解其他的,可以在官网点击其他语言,参考示例结果,不过方法大体上都是相同的。
地址信息类:
- fake.address():完整地址,比如海南省成市丰都深圳路p座 425541
- fake.street_address():街道+地址,比如兴城路A座
- fake.street_name():街道名,比如宜都街
- fake.city_name():城市名,比如兰州
- fake.city():城市,比如兰州市
- fake.province():省份名,比如陕西省
- fake.postcode():邮编
- fake.country():国家
公司信息类:
- fake.company():公司名,比如惠派国际公司信息有限公司
- fake.company_suffix():公司名后缀(公司性质),比如网络有限公司
- fake.company_prefix():公司名前缀,比如鑫博腾飞
日期类:
- fake.date(pattern="%Y-%m-%d", end_datetime=None)
- fake.year():随机年份
- fake.day_of_week():随机星期数
- fake.time(pattern="%H:%M:%S", end_datetime=None):随机时间
网络类:
-
fake.company_email():企业邮箱
-
fake.email():邮箱
个人信息类:
- fake.name():姓名
-
fake.user_name(*args, **kwargs):用户名,只是随机的英文姓名组合,一般是6位
-
fake.phone_number():电话号码
-
fake.simple_profile(sex=None):简略个人信息,包括用户名,姓名,性别,地址,邮箱,出生日期。比如{'username': 'chao', 'name': '胡秀兰', 'sex': 'M', 'address': '宁夏回族自治区玉市沙湾宁德路t座 873713', 'mail': 'uxiao@yahoo.com', 'birthdate': '1998-06-12'}
-
fake.profile(fields=None, sex=None):详略个人信息,比简略个人信息多出公司名、血型、工作、位置、域名等等信息。
- fake.password():密码
- 参数选项:length:密码长度;special_chars:是否能使用特殊字符;digits:是否包含数字;upper_case:是否包含大写字母;lower_case:是否包含小写字母。
- 默认情况:length=10, special_chars=True, digits=True, upper_case=True, lower_case=True
- fake.job():工作
文章类:
- fake.word(ext_word_list=None):随机词语
- ext_word_list可以是一个列表,那么词语会从列表中取
- fake.words(nb=3, ext_word_list=None):随机多个词语
- nb是数量,对于words来说是返回多少个词语
- fake.sentence(nb_words=6, variable_nb_words=True, ext_word_list=None):随机短语(会包括短语结束标志点号)
- fake.paragraph(nb_sentences=3, variable_nb_sentences=True, ext_word_list=None):随机段落
- fake.paragraphs(nb=3, ext_word_list=None):多个随机段落
数据类型类:
- fake.pystr(min_chars=None, max_chars=20):自定义长度的随机字符串
- fake.pyint():随机整数
PS:
想了解Faker的更多用法,可以参考官方文档:https://faker.readthedocs.io/en/master/index.html
小例子:生成随机的数据表信息
注意:这里为了例子简便,对于数据库操作就直接使用“命令式”的了,而不使用ORM模型式的了。
实现过程:
- 利用pymysql连接数据库
- 创建表
- 利用fake格式化要插入的数据
- 利用pymysql执行插入语句
代码:
import pymysql
from faker import Faker
conn=pymysql.connect(host="localhost",port=3306,user="root",password="123456",db="it",charset="utf8")
cursor=conn.cursor()
#这里给出表结构,如果使用已存在的表,可以不创建表。
sql="""
create table user(
id int PRIMARY KEY auto_increment,
username VARCHAR(20),
password VARCHAR(20),
address VARCHAR(35)
)
"""
cursor.execute(sql)
fake=Faker("zh-CN")
for i in range(20):
sql="""insert into user(username,password,address)
values('%s','%s','%s')"""\
%(fake.user_name(),fake.password(special_chars=False),fake.address())
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
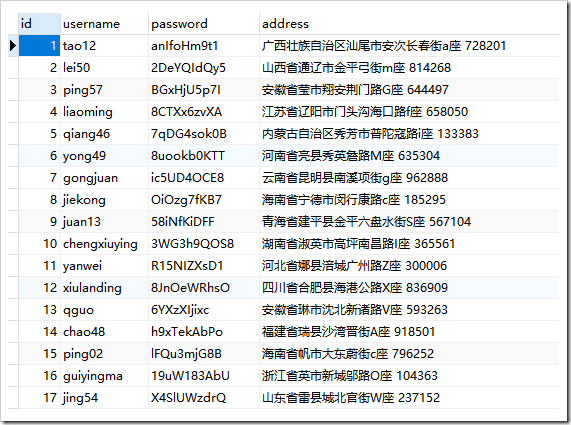
结果:
PS:这里再提供几款相关工具供大家参考使用:
在线随机生成个人信息数据工具:
http://tools.jb51.net/aideddesign/rnd_userinfo
在线随机字符/随机密码生成工具:
http://tools.jb51.net/aideddesign/rnd_password
在线随机数字/字符串生成工具:
http://tools.jb51.net/aideddesign/suijishu
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python字符串操作技巧汇总》、《Python编码操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
python的faker库用法
faker是一个生成伪造数据的Python第三方库,可以伪造城市,姓名,等等,而且支持中文,需要的时候可以一用. 首先需要:pip install faker In [530]: import faker In [531]: init = faker.Faker(locale='zh-cn') In [532]: init.name() Out[532]: '诸明' In [533]: L = [] In [534]: for i in range(100): ...: name = init.
-
python Pandas如何对数据集随机抽样
摘要:有时候我们只需要数据集中的一部分,并不需要全部的数据.这个时候我们就要对数据集进行随机的抽样.pandas中自带有抽样的方法. 应用场景: 我有10W行数据,每一行都11列的属性. 现在,我们只需要随机抽取其中的2W行. 实现方法很简单: 利用Pandas库中的sample. DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None) n是要抽取的行数.(例如n
-
关于Python-faker的函数效果一览
tags faker 随机 虚拟 faker文档链接 代码程序: # -*- coding=utf-8 -*- import sys from faker import Factory reload(sys) sys.setdefaultencoding('utf8') fake = Factory().create('zh_CN') li = dir(fake) def get_dir_run(): with open('somefile.txt', 'wt') as f: for i in
-
Python使用scrapy采集数据时为每个请求随机分配user-agent的方法
本文实例讲述了Python使用scrapy采集数据时为每个请求随机分配user-agent的方法.分享给大家供大家参考.具体分析如下: 通过这个方法可以每次请求更换不同的user-agent,防止网站根据user-agent屏蔽scrapy的蜘蛛 首先将下面的代码添加到settings.py文件,替换默认的user-agent处理模块 复制代码 代码如下: DOWNLOADER_MIDDLEWARES = { 'scraper.random_user_agent.RandomUserAg
-

Python3随机漫步生成数据并绘制
本文为大家分享了Python3随机漫步生成数据并绘制的具体代码,供大家参考,具体内容如下 random_walk.py from random import choice #生成随机漫步的数据类 class RandomWalk(): def __init__(self,num_points=5000): #初始化随机漫步的属性 self.numpoints=num_points #随机漫步的默认点数 self.x_values=[0] #所有的随机漫步都始于(0.0) self.y_value
-
Python随机生成数据后插入到PostgreSQL
用Python随机生成学生姓名,三科成绩和班级数据,再插入到PostgreSQL中. 模块用psycopg2 random import random import psycopg2 fname=['金','赵','李','陈','许','龙','王','高','张','侯','艾','钱','孙','周','郑'] mname=['玉','明','玲','淑','偑','艳','大','小','风','雨','雪','天','水','奇','鲸','米','晓','泽','恩','葛','玄'
-
Python实现生成随机数据插入mysql数据库的方法
本文实例讲述了Python实现生成随机数据插入mysql数据库的方法.分享给大家供大家参考,具体如下: 运行结果: 实现代码: import random as r import pymysql first=('张','王','李','赵','金','艾','单','龚','钱','周','吴','郑','孔','曺','严','华','吕','徐','何') middle=('芳','军','建','明','辉','芬','红','丽','功') last=('明','芳','','民','敏
-
python按比例随机切分数据的实现
在机器学习或者深度学习中,我们常常碰到一个问题是数据集的切分.比如在一个比赛中,举办方给我们的只是一个带标注的训练集和不带标注的测试集.其中训练集是用于训练,而测试集用于已训练模型上跑出一个结果,然后提交,然后举办方验证结果给出一个分数.但是我们在训练过程中,可能会出现过拟合等问题,会面临着算法和模型的选择,此时,验证集就显得很重要.通常,如果数据量充足,我们会从训练集中划分出一定比例的数据来作为验证集. 每次划分数据集都手动写一个脚本,重复性太高,因此将此简单的脚本放到自己的博客.代码如下:
-
python随机生成库faker库api实例详解
废话不多说,直接上代码! # -*- coding: utf-8 -*- # @Author : FELIX # @Date : 2018/6/30 9:49 from faker import Factory # zh_CN 表示中国大陆版 fake = Factory().create('zh_CN') # 产生随机手机号 print(fake.phone_number()) # 产生随机姓名 print(fake.name()) # 产生随机地址 print(fake.address())
-
Python 随机生成测试数据的模块:faker基本使用方法详解
本文实例讲述了Python 随机生成测试数据的模块:faker基本使用方法.分享给大家供大家参考,具体如下: 本文内容: faker的介绍 faker的使用 小例子:生成随机的数据表信息 首发日期:2018-06-15 faker介绍: faker是python的一个第三方模块,是一个github上的开源项目. 主要用来创建一些测试用的随机数据. 官方文档:https://faker.readthedocs.io/en/master/index.html faker的使用: 1.安装模块 pip
-
对python中的six.moves模块的下载函数urlretrieve详解
实验环境:windows 7,anaconda 3(python 3.5),tensorflow(gpu/cpu) 函数介绍:所用函数为six.moves下的urllib中的函数,调用如下urllib.request.urlretrieve(url,[filepath,[recall_func,[data]]]).简单介绍一下,url是必填的指的是下载地址,filepath指的是保存的本地地址,recall_func指的是回调函数,下载过程中会调用可以用来显示下载进度. 实验代码:以下载cifa
-
Python实现从文件中加载数据的方法详解
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源.下面,将展示几种方法. 我们将使用内置的 csv 模块加载CSV文件 CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析.先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下. 包含在Python标准库中自带CSV 模块,我们只需要impor
-
Python快速从视频中提取视频帧的方法详解
目录 1.抽取视频帧 2.多线程方法 3.整体代码 补充 Python快速提取视频帧(多线程) 今天介绍一种从视频中抽取视频帧的方法,由于单线程抽取视频帧速度较慢,因此这里我们增加了多线程的方法. 1.抽取视频帧 抽取视频帧主要使用了 Opencv 模块. 其中: camera = cv2.Videocapture( ) ,函数主要是通过调用笔记本内置摄像头读取视频帧: res, image = camera.read( ) 函数主要是按帧读取视频,返回值 “res” 是布尔型,成功读取返回 T
-
Python Flask框架开发之运用SocketIO实现WebSSH方法详解
Flask 框架中如果想要实现WebSocket功能有许多种方式,运用SocketIO库来实现无疑是最简单的一种方式,Flask中封装了一个flask_socketio库该库可以直接通过pip仓库安装,如下内容将重点简述SocketIO库在Flask框架中是如何被应用的,最终实现WebSSH命令行终端功能,其可用于在Web浏览器内实现SSH命令行执行. 首先我们先来看一下SocketIO库是如何进行通信的,对于前端部分需要引入socket.io这个框架,然后就是利用该框架内提供的各类函数实现创建
-
Python 3.6 性能测试框架Locust安装及使用方法(详解)
背景 Python3.6 性能测试框架Locust的搭建与使用 基础 python版本:python3.6 开发工具:pycharm Locust的安装与配置 点击"File"→"setting" 点击"setting",进入设置窗口,选择"Project Interpreter" 点击"+" 输入需要"Locust",点击"Install Package" 安装完成
-
对Python 多线程统计所有csv文件的行数方法详解
如下所示: #统计某文件夹下的所有csv文件的行数(多线程) import threading import csv import os class MyThreadLine(threading.Thread): #用于统计csv文件的行数的线程类 def __init__(self,path): threading.Thread.__init__(self) #父类初始化 self.path=path #路径 self.line=-1 #统计行数 def run(self): reader =
-
对python中xlsx,csv以及json文件的相互转化方法详解
最近需要各种转格式,这里对相关代码作一个记录,方便日后查询. xlsx文件转csv文件 import xlrd import csv def xlsx_to_csv(): workbook = xlrd.open_workbook('1.xlsx') table = workbook.sheet_by_index(0) with codecs.open('1.csv', 'w', encoding='utf-8') as f: write = csv.writer(f) for row_num
-
对Python中一维向量和一维向量转置相乘的方法详解
在Python中有时会碰到需要一个一维列向量(n*1)与另一个一维列向量(n*1)的转置(1*n)相乘,得到一个n*n的矩阵的情况.但是在python中, 我们发现,无论是".T"还是"np.transpose"都无法实现一维向量的转置,相比之下,Matlab一句" a' "就能实现了. 那怎么实现呢?我找了个方法.请看: 即,我们把向量reshape一下,如此便实现了一维向量与一维向量转置相乘为矩阵的目的. 若大家有其他方法望告知. 以上这篇对
-
对python numpy.array插入一行或一列的方法详解
如下所示: import numpy as np a = np.array([[1,2,3],[4,5,6],[7,8,9]]) b = np.array([[0,0,0]]) c = np.insert(a, 0, values=b, axis=0) d = np.insert(a, 0, values=b, axis=1) print(c) print(d) >>c [[0 0 0] [1 2 3] [4 5 6] [7 8 9]] >>d [[0 1 2 3] [0 4 5