java开发分布式服务框架Dubbo调用过程
目录
- 大致流程
- 调用请求的具体信息
- 协议
- Dubbo协议
- 序列化器
- 调用流程图
- 调用流程源码分析——客户端
- 模板方法模式
- 路由和负载均衡
- 调用的三种方式
- 调用流程源码分析——服务端
- 总结
大致流程
客户端根据远程服务的地址,客户端发送请求至服务端,服务端解析信息并找到对应的实现类,进行方法调用,之后将调用结果原路返回,客户端解析响应之后再返回。

调用请求的具体信息
客户端发送给服务端的请求中应该包含哪些具体信息呢?
首先肯定要说明调用的是服务端的哪个接口、方法名、方法参数类型、以及版本号等,将上述信息封装进请求,服务端就可以根据请求进行方法调用,之后再组装响应返回即可。

以上就是一个实际调用请求所包含的信息。
协议
远程调用必不可少协议的约定,否则客户端与服务端无法解析彼此传来的信息,因此需要提前约定好协议,方便远程调用的信息解析。
Dubbo使用的协议属于Header+Body,协议头固定长度,并且头部中会填写Body的长度,因此Body是不固定长度的,方便拓展,伸缩性较好。
Dubbo协议

协议分为协议头和协议体,16字节的协议头主要携带了魔法数、一些请求的设置,消息体数据长度。
16字节之后包含的就是协议体,包含版本信息,接口名称,接口版本,以及方法名参数类型等。

序列化器
网络是以字节流传输的,传输之前,我们需要将数据序列化为字节流然后再传输至服务端,服务端再反序列化这些字节流得到原来的数据。
从上图中可得知,Dubbo支持多种序列化,大致分为两种,一种是字符型,一种是二进制流。
字符型的代表就是JSON,优点是易懂,方便调试,缺点也很明显,传输效率低,对于计算机来说有很多冗余的东西,例如JSON中的括号等等都会使得网络传输时长边长,占用带宽变大。
二进制流类型的数据紧凑,占用字节数小,传输更快,但是调试困难。
Dubbo默认使用的是Hessian2Serialization,即Hessian2序列化协议。
调用流程图

这个流程图比较简略,大致就是客户端发起调用,实际调用的是代理类,代理类调用Client(默认使用NettyClient),之后构造好协议头以及将Java对象序列化生成协议体,之后进行网络传输。
服务端的NettyServer接收到请求之后,会分发给业务线程池,由线程池来调用具体的方法。
但这远远不够,实际场景比这复杂得多,并且Dubbo是生产级别的,通常会比上述流程更加安全稳定。

在实际生产环境中,服务端往往会集群分布,多个服务端的服务会有多个Invoker,最终需要通过路由Router过滤,以及负载均衡LoadBalance选出一个Invoker进行调用。
请求会到达Netty的IO线程池进行序列化,再将请求发送给服务端,反序列化后丢入线程池处理,找到对应的Invoker进行调用。
调用流程源码分析——客户端
客户端调用方法并发送请求。
首先会调用生成的代理类,而代理类会生成一个RpcInvocation对象调用MockClusterInvoker.invoke()。
生成的RpcInvocation如下:
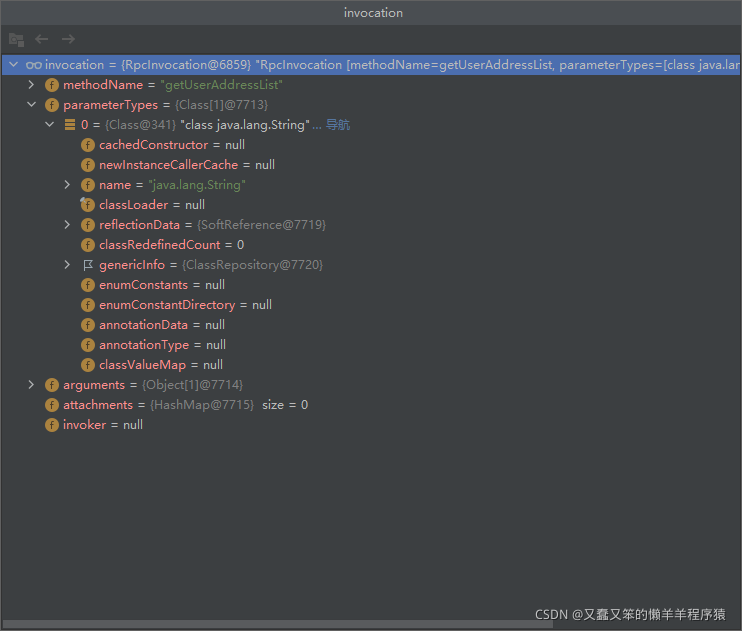
进入MockClusterInvoker.invoke()看看:
public Result invoke(Invocation invocation) throws RpcException {
Result result = null;
//获取mock参数配置
String value = this.directory.getUrl().getMethodParameter(invocation.getMethodName(), "mock", Boolean.FALSE.toString()).trim();
//如果配置了并且配置值为true
if (value.length() != 0 && !value.equalsIgnoreCase("false")) {
//强制走mock流程
if (value.startsWith("force")) {
result = this.doMockInvoke(invocation, (RpcException)null);
} else {
//不走mock流程
try {
result = this.invoker.invoke(invocation);
} catch (RpcException var5) {
....
}
....
result = this.doMockInvoke(invocation, var5);
}
}
} else {
result = this.invoker.invoke(invocation);
}
return result;
}
总的来说就是检查配置是否配置了mock,如果没有就直接进入this.invoker.invoke(invocation),实际上会调用到AbstractClusterInvoker.invoke():
public Result invoke(Invocation invocation) throws RpcException {
//检查是否被销毁
this.checkWhetherDestroyed();
LoadBalance loadbalance = null;
//从上下文中获取attachments,如果获取得到的话绑定到invocation中
Map<String, String> contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation)invocation).addAttachments(contextAttachments);
}
//调用的是directory.list,其中会做路由过滤
List<Invoker<T>> invokers = this.list(invocation);
//如果过滤完之后还有Invoker,就通过SPI获取对应的LoadBalance实现类
if (invokers != null && !invokers.isEmpty()) {
loadbalance = (LoadBalance)ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(((Invoker)invokers.get(0)).getUrl().getMethodParameter(RpcUtils.getMethodName(invocation), "loadbalance", "random"));
}
RpcUtils.attachInvocationIdIfAsync(this.getUrl(), invocation);
return this.doInvoke(invocation, invokers, loadbalance); //调用子类方法
}
protected List<Invoker<T>> list(Invocation invocation) throws RpcException {
//获取invokers目录,实际调用的是AbstractDirectory.list()
List<Invoker<T>> invokers = this.directory.list(invocation);
return invokers;
}
模板方法模式
这是很常见的设计模式之一,就是再抽象类中定好代码的整体架构,然后将具体的实现留到子类中,由子类自定义实现,由此可以再不改变整体执行步骤的情况下,实现多样化的实现,减少代码重复,利于扩展,符合开闭原则。
在上述代码中this.doInvoke()是抽象方法,具体实现在FailoverClusterInvoker.doInvoke()中,上述所有步骤是每个子类都需要执行的,所以抽取出来放在抽象类中。
路由和负载均衡
上述this.directory.list(invocation),其实就是通过方法名找到对应的Invoker,然后由路由进行过滤。
public List<Invoker<T>> list(Invocation invocation) throws RpcException {
if (this.destroyed) {
throw new RpcException("Directory already destroyed .url: " + this.getUrl());
} else {
//抽象方法doList,同样由子类实现
List<Invoker<T>> invokers = this.doList(invocation);
List<Router> localRouters = this.routers;
if (localRouters != null && !localRouters.isEmpty()) {
Iterator i$ = localRouters.iterator();
while(i$.hasNext()) {
Router router = (Router)i$.next();
try { //遍历router,并判断是否进行路由过滤
if (router.getUrl() == null || router.getUrl().getParameter("runtime", false)) {
invokers = router.route(invokers, this.getConsumerUrl(), invocation);
}
} catch (Throwable var7) {
logger.error("Failed to execute router: " + this.getUrl() + ", cause: " + var7.getMessage(), var7);
}
}
}
return invokers;
}
}
返回Invokers之后,还会在进行负载均衡的筛选,得到最终调用的Invoke,Dubbo默认使用的是FailoverClusterInvoker,即失败调用后自动切换的容错方式。
进入FailoverClusterInvoker.doInvoke():
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
//重试次数
int len = this.getUrl().getMethodParameter(invocation.getMethodName(), "retries", 2) + 1;
if (len <= 0) {
len = 1;
}
....
//重试
for(int i = 0; i < len; ++i) {
//负载均衡筛选出一个Invoker
Invoker<T> invoker = this.select(loadbalance, invocation, copyinvokers, invoked);
invoked.add(invoker);
//在上下文中保存调用过的invoker
RpcContext.getContext().setInvokers(invoked);
try {
Result result = invoker.invoke(invocation);
....
return result;
} catch (RpcException e) {
....
} finally {
providers.add(invoker.getUrl().getAddress());
}
}
throw new RpcException();
}
发起这次调用的invoker.invoke又是调用抽象类的中的invoke,然后再调用子类的doInvoke,我们直接进入子类DubboInvoker.doInvoke看看:
protected Result doInvoke(Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation)invocation;
String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment("path", this.getUrl().getPath()); //设置path到attachment中
inv.setAttachment("version", this.version); //设置版本号
ExchangeClient currentClient;
if (this.clients.length == 1) { //选择client
currentClient = this.clients[0];
} else {
currentClient = this.clients[this.index.getAndIncrement() % this.clients.length];
}
try {
boolean isAsync = RpcUtils.isAsync(this.getUrl(), invocation); //是否异步调用
boolean isOneway = RpcUtils.isOneway(this.getUrl(), invocation); //是否oneway调用
int timeout = this.getUrl().getMethodParameter(methodName, "timeout", 1000); //获取超时限制
if (isOneway) { //oneway
boolean isSent = this.getUrl().getMethodParameter(methodName, "sent", false);
currentClient.send(inv, isSent); //发送
RpcContext.getContext().setFuture((Future)null); //返回空的future
return new RpcResult(); //返回空结果
} else if (isAsync) { //异步调用
ResponseFuture future = currentClient.request(inv, timeout);
RpcContext.getContext().setFuture(new FutureAdapter(future)); //上下文中设置future
return new RpcResult(); //返回空结果
} else { //同步调用
RpcContext.getContext().setFuture((Future)null);
return (Result)currentClient.request(inv, timeout).get(); //直接调用future.get() 进行等待,完成get操作之后再返回结果
}
} catch (TimeoutException var9) {
throw new RpcException();
}
}
调用的三种方式
从上述代码中,可以看到调用一共分为三种,分别是oneway,异步,同步。
- oneway:不需要关心请求是否发送成功的情况下,直接使用oneway,无需关心是否能完成发送并返回结果。
- 异步调用:client发送请求之后会得到一个ResponseFuture,然后将这个future塞入上下文中,让用户从上下文拿到这个future,用户可以继续执行操作在调用future.get()返回结果。
- 同步调用:从Dubbo源码中,我们可以看到,先使用了future.get(),让用户进行等待之后,再用client发送请求,给用户的感觉就是调用接口后要进行等待才能返回结果,这个过程是阻塞的。
currentClient.request()就是由如下所示,组装request,然后构造一个future调用NettyClient发送请求。
public ResponseFuture request(Object request, int timeout) throws RemotingException {
if (this.closed) {
throw new RemotingException(this.getLocalAddress(), (InetSocketAddress)null, "Failed to send request " + request + ", cause: The channel " + this + " is closed!");
} else {
Request req = new Request(); //构建request
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
DefaultFuture future = new DefaultFuture(this.channel, req, timeout);
try {
this.channel.send(req); //调用NettyServer.sent()进行发送请求
return future;
} catch (RemotingException var6) {
future.cancel();
throw var6;
}
}
}
Dubbo默认的调用方式是异步调用,那么这个future保存至上下文之后,等响应回来之后怎么找到对应的future呢?
进入DefaultFuture看看:
public class Request {
private final long mId;
public Request() {
this.mId = newId();
}
//静态变量递增,依次构造唯一ID
private static long newId() {
return INVOKE_ID.getAndIncrement();
}
}
public class DefaultFuture implements ResponseFuture {
private static final Map<Long, DefaultFuture> FUTURES = new ConcurrentHashMap();
public DefaultFuture(Channel channel, Request request, int timeout) {
this.done = this.lock.newCondition();
this.start = System.currentTimeMillis();
this.channel = channel;
this.request = request;
this.id = request.getId(); //唯一ID
this.timeout = timeout > 0 ? timeout : channel.getUrl().getPositiveParameter("timeout", 1000);
FUTURES.put(this.id, this); //将唯一ID和future的关系保存到这个ConcurrentHashMap中
CHANNELS.put(this.id, channel);
}
}
Request构造对象的时候会生成一个唯一ID,future内部也会将自己与请求ID存储到一个ConcurrentHashMap中,这个ID发送至服务端之后,服务端也会把这个ID返回,通过ID再去ConcurrentHashMap中找到对应的future,由此完成一次完整的调用。
最终相应返回之后会调用DefaultFuture.received():
public static void received(Channel channel, Response response) {
try {
//获取响应的ID去FUTURES中获取对应的future,获取之后将future移除
DefaultFuture future = (DefaultFuture)FUTURES.remove(response.getId());
if (future != null) {
//确认接收响应
future.doReceived(response);
} else {
logger.warn("....");
}
} finally {
CHANNELS.remove(response.getId());
}
}
private void doReceived(Response res) {
this.lock.lock();
try {
this.response = res; //响应赋值
if (this.done != null) {
this.done.signal(); //通知响应返回
}
} finally {
this.lock.unlock();
}
if (this.callback != null) {
this.invokeCallback(this.callback);
}
}

调用流程源码分析——服务端
服务端接受请求之后会解析请求得到消息,消息总共有五种派发策略:

Dubbo默认使用的是all,所有消息都派发到业务线程池中,在AllChannelHandler中实现:
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService cexecutor = this.getExecutorService();
try {
cexecutor.execute(new ChannelEventRunnable(channel, this.handler, ChannelState.RECEIVED, message));
} catch (Throwable var8) {
if (message instanceof Request && var8 instanceof RejectedExecutionException) {
Request request = (Request)message;
if (request.isTwoWay()) { //如果需要返回响应,将错误封装起来之后返回
String msg = "Server side(" + this.url.getIp() + "," + this.url.getPort() + ") threadpool is exhausted ,detail msg:" + var8.getMessage();
Response response = new Response(request.getId(), request.getVersion());
response.setStatus((byte)100);
response.setErrorMessage(msg);
channel.send(response);
return;
}
}
throw new ExecutionException(message, channel, this.getClass() + " error when process received event .", var8);
}
}
上述代码就是将消息封装成一个ChannelEventRunnable然后放入业务线程池中执行,ChannelEventRunnable会根据ChannelState参数调用对应的处理方法,此处是ChannelState.RECEIVED,因此调用的是handler.received,最终调用的是HeaderExchangeHandler.handleRequest()方法:
Response handleRequest(ExchangeChannel channel, Request req) throws RemotingException {
Response res = new Response(req.getId(), req.getVersion()); //通过requestId构造响应
Object data;
if (req.isBroken()) {
data = req.getData();
String msg;
if (data == null) {
msg = null;
} else if (data instanceof Throwable) {
msg = StringUtils.toString((Throwable)data);
} else {
msg = data.toString();
}
res.setErrorMessage("Fail to decode request due to: " + msg);
res.setStatus((byte)40);
return res;
} else {
data = req.getData();
try {
Object result = this.handler.reply(channel, data); //最终调用DubboProtocol.reply()
res.setStatus((byte)20);
res.setResult(result);
} catch (Throwable var6) {
res.setStatus((byte)70);
res.setErrorMessage(StringUtils.toString(var6));
}
return res;
}
}
进入DubboProtocol.reply()看看:
public Object reply(ExchangeChannel channel, Object message) throws RemotingException {
if (!(message instanceof Invocation)) {
throw new RemotingException();
} else {
Invocation inv = (Invocation)message;
Invoker<?> invoker = DubboProtocol.this.getInvoker(channel, inv); //根据inv得到对应的Invoker
if (Boolean.TRUE.toString().equals(inv.getAttachments().get("_isCallBackServiceInvoke"))) {
//一些回调逻辑
} else {
hasMethod = inv.getMethodName().equals(methodsStr);
}
}
RpcContext.getContext().setRemoteAddress(channel.getRemoteAddress());
return invoker.invoke(inv); //调用选择的Invoker.invoke()
}
}
最后的调用我们已经了解过,就是调用一个Javassist生成的代理类,其中包含了真正的实现类;再进入this.getInvoker()看看是怎么根据请求信息获取到Invoker的:
Invoker<?> getInvoker(Channel channel, Invocation inv) throws RemotingException {
//....
int port = channel.getLocalAddress().getPort();
String path = (String)inv.getAttachments().get("path");
//根据port、path以及其他信息获取serviceKey
String serviceKey = serviceKey(port, path, (String)inv.getAttachments().get("version"), (String)inv.getAttachments().get("group"));
//根据serviceKey在之前提到的exportMap中获取exporter
DubboExporter<?> exporter = (DubboExporter)this.exporterMap.get(serviceKey);
if (exporter == null) {
throw new RemotingException(....);
} else {
return exporter.getInvoker(); //返回Invoker
}
}
关键点在于serviceKey,在之前服务暴露提到的将Invoker封装成exporter之后再构建一个exporterMap,将serviceKey和对应的exporter存入,在服务调用时这个map就起到作用了。
找到所需要的Invoker最终调用实现类具体方法再返回响应整个服务调用流程就结束了,再对上述的流程图进行一下补充:

总结
首先客户端调用接口中的某个方法,但实际调用的是代理类,代理类通过Cluster从获取Invokers,之后通过Router进行路由过滤,再通过所配置的负载均衡机制进行筛选得到本次远程调用所需要的Invoker,此时根据具体的协议构造请求头,再将参数根据具体的序列化协议进行序列化之后构造好塞入协议体,最后通过NettyClient发起远程调用。
服务端NettyServer收到请求后,根据协议将得到的信息进行反序列化得到对象,根据消息派发策略(默认是All)将消息丢入线程池。
业务现场会根据消息类型得到serviceKey,用这个key从之前服务暴露生成的exportMap中得到对应的Invoker,然后调用真正的实现类中的具体方法。
最终将结果返回,因为请求和响应的都有一个对应且唯一的ID,客户端会根据响应的ID找到存储起来的Future,塞入响应中等待唤醒Future的线程,这就完成了一次完整的调用过程。
如有错误或不足欢迎评论指正。
以上就是java开发分布式服务框架Dubbo调用过程的详细内容,更多关于Dubbo服务调用过程的资料请关注我们其它相关文章!
相关推荐
-

java开发分布式服务框架Dubbo暴露服务过程详解
目录 Dubbo服务暴露机制 前言 服务暴露流程 源码解析 本地暴露 远程暴露 Dubbo服务暴露机制 前言 在进行服务暴露机制的分析之前,必须谈谈什么是URL,在Dubbo服务暴露过程中URL是无处不在的,贯穿了整个过程. 一般情况下,URL指的是统一资源定位符,标准格式如下: protocol://host:port/path?key1=value1&key2=value2 Dubbo就是用这种URL的方式来作为约定的参数类型,服务之间也是用URL来进行交互. Dubbo用URL作为配置总线
-
java开发分布式服务框架Dubbo原理机制详解
目录 前言 Dubbo框架有以下部件 Consumer Provider Registry Monitor Container 架构 高可用性 框架设计 服务暴露过程 服务消费过程 前言 在介绍Dubbo之前先了解一下基本概念: Dubbo是一个RPC框架,RPC,即Remote Procedure Call(远程过程调用),相对的就是本地过程调用,在分布式架构之前的单体应用架构和垂直应用架构运用的都是本地过程调用.它允许程序调用另外一个地址空间(通常是网络共享的另外一台机器)的过程或函数,并且
-
java开发分布式服务框架Dubbo服务引用过程详解
目录 大致流程 服务引用策略 服务引用的三种方式 服务引入流程解析 总结 大致流程 Provider将服务暴露出来并且注册到注册中心,而Consumer通过注册中心获取Provider的信息,之后将自己封装成一个调用类去与Provider进行交互. 首先需要将所有调用转化为Dubbo中我们熟悉的Invoker,再通过代理类去远程获取服务. 大致流程如下: 服务引用策略 服务的引用和服务的暴露原理相似,都是Spring自定义标签机制解析生成对应的Bean,在之前服务暴露使用到的Provider S
-
解析Apache Dubbo的SPI实现机制
一.SPI 在Java中,SPI体现了面向接口编程的思想,满足开闭设计原则. 1.1.JDK自带SPI实现 从JDK1.6开始引入SPI机制后,可以看到很多使用SPI的案例,比如最常见的数据库驱动实现,在JDK中只定义了java.sql.Driver的接口,具体实现由各数据库厂商来提供.下面一个简单的例子来快速了解下Java SPI的使用方式: 1)定义一个接口 package com.vivo.study public interface Car { void getPrice(); } 2)
-
Java和Dubbo的SPI机制原理解析
SPI: 简单理解就是,你一个接口有多种实现,然后在代码运行时候,具体选用那个实现,这时候我们就可以通过一些特定的方式来告诉程序寻用那个实现类,这就是SPI. JAVA的SPI 全称为 Service Provider Interface,是一种服务发现机制.它是约定在 Classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,然后文件里面记录的是此 jar 包提供的具体实现类的全限定名. 这样当我们引用了某个 jar 包的时候就可以去找这个 jar 包
-
java开发Dubbo负载均衡与集群容错示例详解
目录 负载均衡与集群容错 Invoker 服务目录 RegistryDirectory 获取Invoker列表 监听注册中心 刷新Invoker列表 StaticDirectory 服务路由 Cluster FailoverClusterInvoker FailfastClusterInvoker FailsafeClusterInvoker FailbackClusterInvoker ForkingClusterInvoker BroadcastClusterInvoker Abstract
-
java开发分布式服务框架Dubbo调用过程
目录 大致流程 调用请求的具体信息 协议 Dubbo协议 序列化器 调用流程图 调用流程源码分析--客户端 模板方法模式 路由和负载均衡 调用的三种方式 调用流程源码分析--服务端 总结 大致流程 客户端根据远程服务的地址,客户端发送请求至服务端,服务端解析信息并找到对应的实现类,进行方法调用,之后将调用结果原路返回,客户端解析响应之后再返回. 调用请求的具体信息 客户端发送给服务端的请求中应该包含哪些具体信息呢? 首先肯定要说明调用的是服务端的哪个接口.方法名.方法参数类型.以及版本号等,将上
-
Java分布式服务框架Dubbo介绍
目录 1.什么是Dubbo? 2.Dubbo核心组件是? 3.Dubbo的工作原理是? 4.介绍一下Dubbo框架分层? 5.Dubbo支持哪些协议? 1.dubbo默认协议: 2.rmi协议: 3.hessian协议: 4.http协议: 5.webservice协议: 6.thrift协议: 7.redis协议: 8.memcached协议: 6.Dubbo核心配置有哪些? 7.Dubbo有哪几种集群容错方案.哪几种负载均衡策略? 8.Dubbo用到哪些设计模式,简要介绍? 9.Dubbo有
-
Java 实现分布式服务的调用链跟踪
目录 为什么要实现调用链跟踪? 如何实现? 第一步,看图.看场景,用户浏览器的一次请求行为所走的路径是什么样的 第二步,实现.不想看代码可直接拉最后看结果和原理 测试一下结果: 为什么要实现调用链跟踪? 随着业务的发展,所有的系统最终都会走向服务化体系,微服务的目的一是提高系统的稳定性,二是提高持续交付的效率,为什么能提高这两项不是今天讨论的内容. 当然这也不是绝对的,如果业务还在MVP验证,团队规模小个人觉得完全没必要微服务化.单体应用是比较好的选择.作者是有经历过从单体应用到1000+应用的
-
Java开发环境配置及Vscode搭建过程
目录 Java开发环境配置 Vscode中配置Java开发环境 Java开发环境配置 环境配置之前,首先使用cmd命令查看机器是否配置过Java环境,测试命令为(java或javac或java -version[java与-之间存在空格]) 若出现以上信息,说明已经配置好,无需重复操作!!!反之,进行下述操作. 在电脑中安装JDK,下载地址,进入后下滑显示界面 选择适合自己的版本进行下载,此处演示 Windows X64 Installer 下载.在Oracle官网下载涉及到账号注册,也可访问此
-
Dubbo+zookeeper搭配分布式服务的过程详解
目录 分布式架构: Dubbo 是什么 Dubbo: 思想: 依赖: 分布式架构: 1.当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,前端应用能更快速的响应多变的市场需求. 2.此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键. Dubbo 是什么 一款分布式服务框架 高性能和透明化的RPC远程服务调用方案 SOA服务治理方案 Dubbo: 作为分布式架构比较后的框架,同时也是比较容易入手的框架,适合作为分布式的入手框架,下
-
java实现分布式项目搭建的方法
1 分布式 1.1 什么是分布式 分布式系统一定是由多个节点组成的系统.其中,节点指的是计算机服务器,而且这些节点一般不是孤立的,而是互通的. 这些连通的节点上部署了我们的节点,并且相互的操作会有协同.分布式系统对于用户而言,他们面对的就是一个服务器,提供用户需要的服务而已,而实际上这些服务是通过背后的众多服务器组成的一个分布式系统,因此分布式系统看起来像是一个超级计算机一样. 1.2 分布式与集群的区别 集群是同一个系统部在不同的服务器上,例如一个登陆系统部在不同的服务器上. 分布式是不同的系
-
SpringBoot整合Dubbo zookeeper过程解析
这篇文章主要介绍了SpringBoot整合Dubbo zookeeper过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 docker pull zookeeper docker run --name zk01 -p 2181:2181 --restart always -d 2e30cac00aca 表明zookeeper已成功启动 Zookeeper和Dubbo• ZooKeeperZooKeeper 是一个分布式的,开放源码的分布式