MySQL学习教程之聚簇索引
聚簇,其实是相对于InnoDB这个数据库引擎来说的,因此在将聚簇索引的时候,我们通过InnoDB和MyISAM这两个MySQL的数据库引擎展开。
InnoDB和MyISAM的数据分布对比
CREATE TABLE test (col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2));
首先通过以上SQL语句创建出一个表格,其中col1是主键,两列数据均创建了索引。然后我们数据的主键取值为1-10000,按照随机的顺序插入数据库中。
MyISAM的数据分布
MyISAM的数据存储逻辑比较简单,就是按照数据插入的顺序创建出一个数据表格。直观上来看如下图:

可以看出,数据就是按照插入的顺序“一行一行”生成的。前面还会有一个行号的字段,用处就是在查找到索引的时候能够快速地定位到该行索引的位置。
我们再来看一下具体的细节:

上图展示的情况就是在MyISAM引擎下,按照主键建立的索引的具体实现。可以看出在主键按照顺序排列在叶子结点上的同时,节点中还存储着这个主键在数据库表格中存在的具体的行号,正如我们上面所说的,这个行号可以帮助我们快速地定位到表中数据的位置,也可以把这个行号理解为一个指针,指向了这个主键所在的具体数据行。
那么如果我们按照col2建立索引呢?会有什么不同吗?答案是不会的:
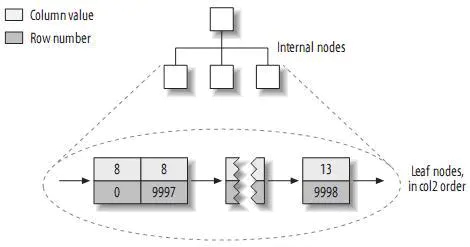
所以得到的结论就是在MyISAM中建立索引是否是主键索引其实是没有区别的,唯一不同的就是这是一个“主键的索引”。
InnoDB的数据分布
因为InnoDB支持聚簇索引,所以会与MyISAM上的索引实现方式有所区别。
我们先看看基于主键的聚簇索引在InnoDB上的实现方式:

首先,和MyISAM上的主键索引一样,这里的索引的叶子结点上同样也是包括了主键的值,并且主键的值是按照顺序排列的。不同的是,每一个叶子结点还包括了事务id,回滚指针和其他非主键列的值(这里指的col2)。所以我们可以理解为InnoDB上的聚簇索引,是将原来表格中的所有的行数据按照主键进行排列然后放在了索引的叶子节点上。这就是一个与MyISAM在主键索引上的一个不同。 MyISAM的主键索引在查找到对应的主键值之后需要通过指针(行号)再去表中找到相对应的数据行,而InnoDB的主键索引,将数据信息全部放在了索引里面,可以直接在索引中查找拿到。
再来看看InnoDB中的二级索引的情况:

可以看到,和InnoDB中的主键索引不同,二级索引并没有在叶子结点存储所有的行数据信息,而是除了索引列的值外,只存储了这个数据行所对应的主键的信息。我们知道在MyISAM中,二级索引和主键索引一样,除了索引列的值外,只存储了一个指针(行号)的信息。
对比一下两个引擎上的二级索引。即存储指针和存储主键值的优劣。
首先存储主键值会比只存储一个指针带来的空间开销更大。但是当我们数据表在进行分裂或者其他改变结构的操作的时候,存储主键值的索引并不会收到影响,而存储指针的索引,可能就要重新进行更新维护。
用一个图对两个引擎中的两种索引进行对比:

总结
到此这篇关于MySQL学习教程之聚簇索引的文章就介绍到这了,更多相关MySQL聚簇索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解MySQL 聚簇索引与非聚簇索引
1.聚集索引 表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致.对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页. 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种. 从物理文件也可以看出 InnoDB(聚集索引)的数据文件只有数据结构文件.frm和数据文件.idb 其中.idb中存放的是数据和索引信息 是存放在一起的. 2.非聚集索引 表数据存储顺序与索引顺序无关.对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,
-

mysql聚簇索引的页分裂原理实例分析
本文实例讲述了mysql聚簇索引的页分裂.分享给大家供大家参考,具体如下: 在MySQL中,MyISAM采用的是非聚簇索引的,InnoDB存储引擎是采用聚簇索引的. 聚簇结构的特点: 根据主键查询条目时,不用回行(数据就在主键节点下) 如果碰到不规则数据插入时,造成频繁的页分裂 为什么会产生页分裂? 这是因为聚簇索引采用的是平衡二叉树算法,而且每个节点都保存了该主键所对应行的数据,假设插入数据的主键是自增长的,那么根据二叉树算法会很快的把该数据添加到某个节点下,而其他的节点不用动:但是如果插入的
-
MySQL学习教程之聚簇索引
聚簇,其实是相对于InnoDB这个数据库引擎来说的,因此在将聚簇索引的时候,我们通过InnoDB和MyISAM这两个MySQL的数据库引擎展开. InnoDB和MyISAM的数据分布对比 CREATE TABLE test (col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2)); 首先通过以上SQL语句创建出一个表格,其中col1是主键,两列数据均创建了索引.然后我们数据的主键取值为1-10000,按照随机的顺序插
-
Centos7下MySQL安装教程
MySQL安装教程,供大家参考,具体内容如下 1.下载 去官网下载Yum源:地址 2.安装 rpm -ivh mysql57-community-release-el7-11.noarch.rpm yum install MySQL-community-server 3.连接设置 •初始安装没有密码 mysql -u root •设置密码 set password for 'root'@'localhost' =password('password'); #如果报以下错误 #退出mysql连接运
-
MyBatis学习教程(二)—如何使用MyBatis对users表执行CRUD操作
上一篇文章MyBatis入门学习教程(一)-MyBatis快速入门中我们讲了如何使用Mybatis查询users表中的数据,算是对MyBatis有一个初步的入门了,今天讲解一下如何使用MyBatis对users表执行CRUD操作.在没奔主题之前,先给大家补充点有关mybatis和crud的基本知识. 什么是 MyBatis? MyBatis 是支持普通 SQL 查询,存储过程和高级映射的优秀持久层框架. MyBatis 消除了几乎所有的 JDBC 代码和参数的手工设置以及对结果集的检索.MyBa
-
MySQL学习第五天 MySQL数据库基本操作
本文针对MySQL数据库基本操作进行学习研究,需要了解的朋友不要错过这篇文章. 以下均是在Windows 64位操作系统下的命令行使用. 学习之前我们先来解释一下MySQL语法格式中的一些符号代表的含义: (1)中括号([])表示存在或者不存在都可以,是可选参数.比如:SHOW {DATABASES | SCHEMAS} [LIKE 'pattern' | WHERE expr];此语法格式中的[]括起来的内容是可以不加的. (2)大括号({})表示命令中必须出现,是必选参数. 比如:CREA
-
MySQL学习第二天 安装和配置mysql winx64
一.安装方式 MySQL安装文件分为两种,一种是MSI格式的,一种是ZIP格式的.下面来看看这两种方式: MSI格式的可以直接点击安装,按照它给出的安装提示进行安装,Windows操作系统下一般MySQL将会安装在C:\Program Files\MySQL该目录中. ZIP格式是自己解压,解压缩之后其实MySQL就可以使用了,但是要进行配置.这个可以在网上随便找,给出很多自定义安装和配置的详细步骤.推荐的链接:超详细的mysql图文安装教程 二.安装MySQL(Windows 64位操作系统)
-
21分钟 MySQL 入门教程
21分钟 MySQL 入门教程 目录 一.MySQL的相关概念介绍 二.Windows下MySQL的配置 配置步骤 MySQL服务的启动.停止与卸载 三.MySQL脚本的基本组成 四.MySQL中的数据类型 五.使用MySQL数据库 登录到MySQL 创建一个数据库 选择所要操作的数据库 创建数据库表 六.操作MySQL数据库 向表中插入数据 查询表中的数据 更新表中的数据 删除表中的数据 七.创建后的修改 添加列 修改列 删除列 重命名表 删除整张表 删除整个数据库 八.附录 修改 root
-
MyBatis入门学习教程(一)-MyBatis快速入门
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis .2013年11月迁移到Github. iBATIS一词来源于"internet"和"abatis"的组合,是一个基于Java的持久层框架.iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO) 首先给大家介绍MyBatis的含义
-
MyBatis学习教程(三)-MyBatis配置优化
一.连接数据库的配置单独放在一个properties文件中 之前,我们是直接将数据库的连接配置信息写在了MyBatis的conf.xml文件中,如下: <?xml version="." encoding="UTF-"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config .//EN" "http://mybatis.org/dtd/mybatis--
-
Java学习教程之定时任务全家桶
定时任务应用非常广泛,Java提供的现有解决方案有很多. 本次主要讲schedule.quartz.xxl-job.shedlock等相关的代码实践. 一.SpringBoot使用Schedule 核心代码: @Component public class ScheduleTask { private Logger logger = LoggerFactory.getLogger(ScheduleTask.class); @Scheduled(cron = "0/1 * * * * ? &quo
-
MyBatis入门学习教程-MyBatis快速入门
目录 Mybatis 一.快速开始 1.创建 Maven 项目 2.导入 Maven 依赖 3.配置 Maven 插件 4.新建数据库,导入表格 5.编写 Mybatis 配置文件 6.编写实体类 7.编写 mapper 接口 8.编写 mapper 实现 9.Mybatis 配置文件中,添加 mapper 映射 10.编写 Mybatis 工具类 11.测试 二.日志添加 1.添加 Maven 依赖 2.添加 log4j 配置 3.Mybatis 中配置 LOG 4.执行测试 三.Mybati