Python标准库学习之psutil内存详解
目录
- 查询CPU信息
- 查询内存信息
- 查询磁盘信息
- 查询网络信息
- 查询进程信息
人生苦短,快学Python!
今天介绍的是psutil模块,它是一个跨平台库 https://github.com/giampaolo/psutil
命令行下通过pip安装:
pip install psutil
如果跟我一样安装的是Anaconda,则剩下这步了,因为自带了。
顾名思义
psutil = process and system utilities
它专门用来获取操作系统以及硬件相关的信息,比如:CPU、内存、磁盘、网络、进程管理等。
今天这篇文章,就来给大家介绍一下其常用功能和使用方法。
查询CPU信息
先导入psutil模块,获取CPU的信息数据。
import psutil
# CPU逻辑数量
psutil.cpu_count()
# CPU物理核心
psutil.cpu_count(logical=False)
# 统计CPU的用户/系统/空闲时间
psutil.cpu_times()
# interval:每隔0.5s刷新一次
# percpu:查看所有的cpu使用率
for x in range(5):
print(psutil.cpu_percent(interval=0.5, percpu=True))
输出结果:

注:大家如果对jupyter notebook 同时输出多个变量感兴趣,可以查看这篇文章
《15个应该掌握的Jupyter Notebook使用技巧(小结)》
查询内存信息
输出内存使用情况(总内存、可用内存、内存使用率、已使用内存)。
psutil.virtual_memory()
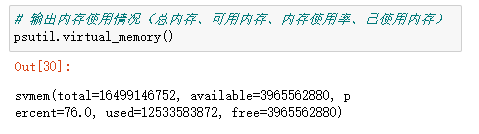
比如上面输出的total=16499146752即为总内存16G,已使用内存/总内存= 76.0%(内存使用率)。
查询磁盘信息
可以通过psutil获取磁盘分区、磁盘使用率和磁盘IO信息。
# 磁盘分区信息
psutil.disk_partitions()
# 磁盘使用情况
psutil.disk_usage('/')
# 磁盘IO
psutil.disk_io_counters()
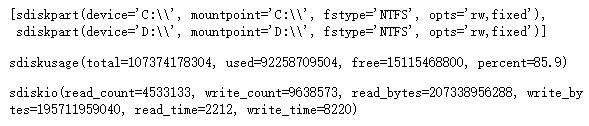
其中,返回的IO信息指标有磁盘IO信息
read_count(读IO数)
write_count(写IO数)
read_bytes(IO写字节数)
read_time(磁盘读时间)
write_time(磁盘写时间)
查询网络信息
使用psutil库查询网络读写字节/包的个数。
psutil.net_io_counters()

其中,返回的数据指标有
btes_sent: 发送的字节数
bytes_recv: 接收的字节数
packets_sent: 发送的包数据量
packets_recv: 接收的包数据量
errin: 接收包时, 出错的次数
errout: 发送包时, 出错的次数
dropin: 接收包时, 丢弃的次数
dropout: 发送包时, 丢弃的次数
除此以外,还有很多获取网络接口和网络连接信息的函数。
比如
psutil.net_if_addrs()获取网络接口信息
psutil.net_if_stats()获取网络接口状态等。
查询进程信息
最后,使用psutil模块也能获取所有进程的详细信息数据!
psutil.pids() # 所有进程ID

返回的结果包括了所有进程的ID(pid)。
根据 pid 可以获取一个进程对应的 Process 对象,而这个对象里面包含了该进程的全部数据。
下面我们指定进程ID=113408,其实就是当前Python交互环境,来获取该进程的信息。
# 获取指定进程ID=113408,其实就是当前Python交互环境 p = psutil.Process(113408) # 进程名称 p.name() # 进程的exe路径 p.exe() # 进程的工作目录 p.cwd() # 进程启动的命令行 p.cmdline() # 当前进程id p.pid

总而言之,psutil使得我们可以轻松用Python程序获取各类系统信息。
本文只介绍了该模块的安装和基本使用方法,后续大家想了解更多详情,可以参考psutil的官 https://github.com/giampaolo/psutil
以上就是Python标准库学习之psutil内存详解的详细内容,更多关于Python标准库的资料请关注我们其它相关文章!
相关推荐
-
Python标准库与第三方库详解
本文详细罗列并说明了Python的标准库与第三方库如下,供对此有需要的朋友进行参考: Tkinter---- Python默认的图形界面接口. Tkinter是一个和Tk接口的模块,Tkinter库提供了对Tk API的接口,它属于Tcl/Tk的GUI工具组.Tcl/Tk是由John Ousterhout发展的书写和图形设备.Tcl(工具命令语言)是个宏语言,用于简化shell下复杂程序的开发,Tk工具包是和Tcl一起开发的, 目的是为了简化用户接口的设计过程.Tk工具包由许多不同的小部件,如一
-
Python运维开发之psutil库的使用详解
介绍 psutil能够轻松实现获取系统运行的进程和系统利用率. 导入模块 import psutils 获取系统性能信息 CPU信息 使用cpu_times()方法获取CPU的完整信息: >>> psutil.cpu_times() 获取单项数据,例如用户user的CPU时间比: >>> psutil.cpu_times().user 获取CPU的个数: >>> psutil.cpu_count() # 默认logical=True,获取逻辑个数 &g
-
Python中psutil的介绍与用法
psutil简介 psutil是一个跨平台库(http://pythonhosted.org/psutil/)能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等)信息.它主要用来做系统监控,性能分析,进程管理.它实现了同等命令行工具提供的功能,如ps.top.lsof.netstat.ifconfig.who.df.kill.free.nice.ionice.iostat.iotop.uptime.pidof.tty.taskset.pmap等.目前支持32位和64位的L
-
python中使用psutil查看内存占用的情况
有的时候需要对python程序内存占用进行监控,这个时候可以用到psutil库,Anaconda中是自带的,如果import出错,可以用pip install psutil(安装在python中)或conda install psutil(安装在Anaconda中) #常用的: import psutil import os info = psutil.virtual_memory() print u'内存使用:',psutil.Process(os.getpid()).memory_info(
-

Python标准库学习之psutil内存详解
目录 查询CPU信息 查询内存信息 查询磁盘信息 查询网络信息 查询进程信息 人生苦短,快学Python! 今天介绍的是psutil模块,它是一个跨平台库 https://github.com/giampaolo/psutil 命令行下通过pip安装: pip install psutil 如果跟我一样安装的是Anaconda,则剩下这步了,因为自带了. 顾名思义 psutil = process and system utilities 它专门用来获取操作系统以及硬件相关的信息,比如:CPU.
-
python标准库学习之sys模块详解
目录 前言 处理命令行参数 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.platform 返回操作系统平台名称 sys.stdin.readline()与input sys.stdout与print 总结 补充:sys 模块的实例 前言 sys模块是与python解释器交互的一个接口.sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分. 处理命令行参数 在解释器启动后, argv 列表包含
-
Python标准库之Sys模块使用详解
sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分. 处理命令行参数 在解释器启动后, argv 列表包含了传递给脚本的所有参数, 列表的第一个元素为脚本自身的名称. 使用sys模块获得脚本的参数 复制代码 代码如下: print "script name is", sys.argv[0] # 使用sys.argv[0]采集脚本名称 if len(sys.argv) > 1: print "there are",
-
C++ STL标准库std::vector的使用详解
目录 1.简介 2.使用示例 3.构造.析构.赋值 3.1std::vector::vector构造函数 3.2std::vector::~vector析构函数 3.3std::vector::operator=“=”符号 4.Iterators迭代器 4.1std::vector::begin 4.2std::vector::end 4.3std::vector::rbegin 4.4std::vector::rend 4.5std::vector::cbegin(C++11) 4.6std:
-
Python爬虫库urllib的使用教程详解
目录 Python urllib库 urllib.request模块 urlopen函数 Request 类 urllib.error模块 URLError 示例 HTTPError示例 URLError和HTTPError混合使用 urllib.parse模块 urlparse() urlunparse() urlsplit() urljoin() URL 转码 编码quote(string) 编码urlencode() 解码 unquote(string) urllib.robotparse
-
C标准库<assert.h>的实现详解
本文实例讲解了C标准库<assert.h>的实现过程及相关用法.分享给大家供大家参考.具体分析如下: 一.背景知识 头文件<assert.h>唯一的目的就是提供assert宏定义,可以在程序中关键的地方使用这个宏来进行断言.如果一处断言被证明非真,希望程序在标准错误流输出一条适当的提示信息,并使执行异常终止. 可以这样写代码: #include<assert.h> ... assert(0 <= i && i < sizeof(a) / si
-
Python随机函数库random的使用方法详解
前言 众所周知,python拥有丰富的内置库,还支持众多的第三方库,被称为胶水语言,随机函数库random,就是python自带的标准库,他的用法极为广泛,除了生成比较简单的随机数外,还有很多功能.使用random库: import random random库主要函数: 函数名 说明 用法 random() 生成一个0~1之间的随机浮点数,范围 0 <= n < 1.0 random.random() uniform(a,b) 返回a, b之间的随机浮点数,范围[a, b]或[a, b),
-
python爬虫库scrapy简单使用实例详解
最近因为项目需求,需要写个爬虫爬取一些题库.在这之前爬虫我都是用node或者php写的.一直听说python写爬虫有一手,便入手了python的爬虫框架scrapy. 下面简单的介绍一下scrapy的目录结构与使用: 首先我们得安装scrapy框架 pip install scrapy 接着使用scrapy命令创建一个爬虫项目: scrapy startproject questions 相关文件简介: scrapy.cfg: 项目的配置文件 questions/: 该项目的python模块.之
-
Python Numpy库datetime类型的处理详解
前言 关于时间的处理,Python中自带的处理时间的模块就有time .datetime.calendar,另外还有扩展的第三方库,如dateutil等等.通过这些途径可以随心所欲地用Python去处理时间.当我们用NumPy库做数据分析时,如何转换时间呢? 在NumPy 1.7版本开始,它的核心数组(ndarray)对象支持datetime相关功能,由于'datetime'这个数据类型名称已经在Python自带的datetime模块中使用了, NumPy中时间数据的类型称为'datetime6
-
Python BS4库的安装与使用详解
Beautiful Soup 库一般被称为bs4库,支持Python3,是我们写爬虫非常好的第三方库.因用起来十分的简便流畅.所以也被人叫做"美味汤".目前bs4库的最新版本是4.60.下文会介绍该库的最基本的使用,具体详细的细节还是要看:[官方文档](Beautiful Soup Documentation) bs4库的安装 Python的强大之处就在于他作为一个开源的语言,有着许多的开发者为之开发第三方库,这样我们开发者在想要实现某一个功能的时候,只要专心实现特定的功能,其他细节与