Python使用ElementTree美化XML格式的操作
Python中使用ElementTree可以很方便的处理XML,但是产生的XML文件内容会合并在一行,难以看清楚。
如下格式:
<root><aa>aatext<cc>cctext</cc></aa><bb>bbtext<dd>ddtext<ee>eetext</ee></dd></bb></root>
使用minidom模块中的toprettyxml和writexml方法都有参数可以优化XML,但是有两个问题:
a. 如果解析的XML已经是美化过的,那么执行该方法会多出很多空行
b. 产生的结果会将text也独立一行,如下:
<root>
<aa>
aatext
</aa>
<bb>
bbtext
</bb>
</root>
而我想产生如下结果:
<root> <aa>aatext</aa> <bb>bbtext</bb> </root>
于是只能自己写一个美化XML的方法。
我们首先研究一下ElementTree模块中的Element类,使用getroot方法返回的便是Element类。
该类中有四个属性tag、attrib、text与tail, 对应在XML中如下图所示:

整个XML就是一个Element,里面嵌套了很多子Element。
Element可以使用for循环迭代。
通过在text和tail中增加换行和制表符,就可以实现美化XML的目的。
美化代码如下:
def prettyXml(element, indent, newline, level = 0): # elemnt为传进来的Elment类,参数indent用于缩进,newline用于换行
if element: # 判断element是否有子元素
if element.text == None or element.text.isspace(): # 如果element的text没有内容
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
#else: # 此处两行如果把注释去掉,Element的text也会另起一行
#element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * level
temp = list(element) # 将elemnt转成list
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1): # 如果不是list的最后一个元素,说明下一个行是同级别元素的起始,缩进应一致
subelement.tail = newline + indent * (level + 1)
else: # 如果是list的最后一个元素, 说明下一行是母元素的结束,缩进应该少一个
subelement.tail = newline + indent * level
prettyXml(subelement, indent, newline, level = level + 1) # 对子元素进行递归操作
from xml.etree import ElementTree #导入ElementTree模块
tree = ElementTree.parse('test.xml') #解析test.xml这个文件,该文件内容如上文
root = tree.getroot() #得到根元素,Element类
prettyXml(root, '\t', '\n') #执行美化方法
ElementTree.dump(root) #显示出美化后的XML内容
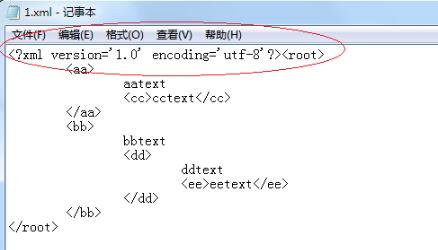
输出结果如下:
<root>
<aa>
aatext
<cc>cctext</cc>
</aa>
<bb>
bbtext
<dd>
ddtext
<ee>eetext</ee>
</dd>
</bb>
</root>
残留问题点:
windows下的换行符是"\r\n",只需将prettyXml方法的第三个参数改为"\r\n",使用记事本打开生成的XML大部分OK。
但是XML说明与根元素开始符之间不知如何插入"\r\n".
补充知识:python-xml 模块-代码生成xml 文档
一、XML 模块
什么是xml:可扩展的标记语言,标记翻译为标签,用标签来组织数据的语言,也是一种语言可以用来自定义文档结构。相比json 使用场景更加广泛,但是语法格式相比json 复杂很多
什么时候使用json:前后台交互数据时使用json
什么时候使用xml:当需要自定义文档结构时使用xml,比如java中经常用xml来作为配置文件,常见操作就是通过程序去读取配置信息,而修改增加删除,一般是交给用户来手动完成
标签的叫发:node(节点)、elment(元素)、tag(标签)
需求从conuntrys中获取所有的国家名称
==========================>countrys
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2009</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2012</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2012</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data># 取别名可以用于简化书写
import xml.etree.ElementTree as ET
tree = ET.parse('countrys')
#获取根标签#第一种获取标签的方式
#全文查找
iter()
# 获取迭代器 如果不指定参数 则迭代器迭代的是所有标签
print(root.iter())
# 获取迭代器 如果指定参数 则迭代器迭代的是所有名称匹配的标签
for e in root.iter("rank"):
print(e)
#第二种获取标签的方式
#在当前标签下(所有子级标签)寻找第一个名称匹配的标签
print(root.find("rank")) #第一个名称不匹配所以返回None#第三种获取标签的方式
#在当前标签下(所有子级标签)寻找所有名称匹配的标签
print(root.findall("rank")) #[]
练习:找到新加坡中year 这个标签
#print(e.tag) #标签名称
#print(e.attrib) #属性 字典类型
#print(e.text) #文本内容import xml.etree.ElementTree as ETtree = ET.parse("countrys")
# 获取根标签
root = tree.getroot()
for e in root.iter("country"):
if e.attrib["name"] == "Singapore":
y = e.find("year")
print(y.text) #2012
在程序中修改文档内容:把所有year标签的文本加1
import xml.etree.ElementTree as ETtree = ET.parse("countrys")
root = tree.getroot()
for e in root.iter("year"):
e.text = str(int(e.text) + 1)
#做完修改后要将修改后的内容写入文件
tree.write('countrys')
把新加坡国家删除:
import xml.etree.ElementTree as ETtree = ET.parse("countrys")
root = tree.getroot()for e in root.findall("country"):
print(e)
if e.attrib["name"] == "Singapore":
#删除时要通过被删除的父级标签来删除
root.remove(e)tree.write('countrys')
用程序将中国信息写入文档中:
import xml.etree.ElementTree as ETtree = ET.parse("countrys")
root = tree.getroot()
#添加时也需要将要添加的数据做成一个Element
c = ET.Element("country",{"name":"china"})# 在国家下有一堆子标签
ranke = ET.Element("ranke",{"updated":"yes"})
c.append(ranke)year = ET.Element("year")
year.text = "2018"
c.append(year)#添加到root标签中
root.append(c)
tree.write("countrys")
总结:一般不会通过程序 去修改 删除 和添加
什么时候应该使用XML格式:
当你需要自定文档结构时(XML最强大的地方就是结构)
前后台交互不应该使用,前后台交互应该使用JSON格式
代码生成XML文档
import xml.etree.ElementTree as ET# 创建根标签
root = ET.Element("root")
root.text = "这是一个XML文档!"c = ET.Element("country",{"name":"china"})
root.append(c)tree = ET.ElementTree(root)
# 参数: 文件名称 编码方式 是否需要文档声明
tree.write("new.xml",encoding="utf-8",xml_declaration=True)=========================>new.xml 内容为
<?xml version='1.0' encoding='utf-8'?>
<root>这是一个XML文档!<country name="china" /></root>
以上这篇Python使用ElementTree美化XML格式的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python通过ElementTree操作XML获取结点读取属性美化XML
1.引入库需要用到3个类,ElementTree,Element以及建立子类的包装类SubElement from xml.etree.ElementTree import ElementTreefrom xml.etree.ElementTree import Elementfrom xml.etree.ElementTree import SubElement as SE 2.读入并解析tree = ElementTree(file=xmlfile)root = tree.getroot()
-
Python使用ElementTree美化XML格式的操作
Python中使用ElementTree可以很方便的处理XML,但是产生的XML文件内容会合并在一行,难以看清楚. 如下格式: <root><aa>aatext<cc>cctext</cc></aa><bb>bbtext<dd>ddtext<ee>eetext</ee></dd></bb></root> 使用minidom模块中的toprettyxml和write
-

三分钟教会你用Python+OpenCV批量裁剪xml格式标注的图片
目录 前言 xml文件格式 代码思想 完整代码 效果展示 总结 前言 在目标检测中,数据集常常使用labelimg标注,会生成xml文件.本文旨在根据xml标注文件来裁剪目标,以达到去除背景信息的目的. xml文件格式 以下是一个标注好的图片生成的xml文件.具体含义见代码注释. <annotation> <!--xml所属文件夹--> <folder>JPEGImages</folder> <!--对应图片所属文件夹--> <filena
-
python自定义解析简单xml格式文件的方法
本文实例讲述了python自定义解析简单xml格式文件的方法.分享给大家供大家参考.具体分析如下: 因为公司内部的接口返回的字串支持2种形式:php数组,xml:结果php数组python不能直接用,而xml字符串的格式不是标准的,所以也不能用标准模块解析.[不标准的地方是某些节点会的名称是以数字开头的],所以写个简单的脚步来解析一下文件,用来做接口测试. #!/usr/bin/env python #encoding: utf-8 import re class xmlparse: def _
-
python利用lxml读写xml格式的文件
之前在转换数据集格式的时候需要将json转换到xml文件,用lxml包进行操作非常方便. 1. 写xml文件 a) 用etree和objectify from lxml import etree, objectify E = objectify.ElementMaker(annotate=False) anno_tree = E.annotation( E.folder('VOC2014_instance'), E.filename("test.jpg"), E.source( E.d
-
Python中xml和json格式相互转换操作示例
本文实例讲述了Python中xml和json格式相互转换操作.分享给大家供大家参考,具体如下: Python中xml和json格式是可以互转的,就像json格式转Python字典对象那样. xml格式和json格式互转用到的xmltodict库 安装xmltodict库 C:\Users\Administrator>pip3 install xmltodict Collecting xmltodict Downloading xmltodict-0.11.0-py2.py3-none-any
-
python通过ElementTree操作XML
1.引入库 需要用到3个类,ElementTree,Element以及建立子类的包装类SubElement from xml.etree.ElementTree import ElementTree from xml.etree.ElementTree import Element from xml.etree.ElementTree import SubElement as SE 2.读入并解析 tree = ElementTree(file=xmlfile) root = tree.getr
-
python操作XML格式文件的一些常见方法
目录 前言 1. 读取文件和内容 2.读取节点数据 3.修改和删除节点 4.构建文档 方式一ET.Element() 补充:XML文件和JSON文件互转 1.XML文件转为JSON文件 2.JSON文件转换为XML文件 总结 前言 可扩展标记语言,是一种简单的数据存储语言,XML被设计用来传输和存储数据 存储,可用来存放配置文件,例:java配置文件 传输,网络传输以这种格式存在,例:早期ajax传输数据等 <data> <country name="Liechtenstein
-
Python处理XML格式数据的方法详解
本文实例讲述了Python处理XML格式数据的方法.分享给大家供大家参考,具体如下: 这里的操作是基于Python3平台. 在使用Python处理XML的问题上,首先遇到的是编码问题. Python并不支持gb2312,所以面对encoding="gb2312"的XML文件会出现错误.Python读取的文件本身的编码也可能导致抛出异常,这种情况下打开文件的时候就需要指定编码.此外就是XML中节点所包含的中文. 我这里呢,处理就比较简单了,只需要修改XML的encoding头部. #!/
-
python标准库ElementTree处理xml
目录 1. 示例用法 Element对象具有如下属性和操作 遇到非法格式的xml ExpatError: no element found ExpatError: mismatched tag ExpatError: not well-formed(invalid token) 1. 示例用法 参照官方文档,创建country_data.xml测试文档,内容如下: <?xml version="1.0"?> <data> <country name=&qu