浅谈分词器Tokenizer
一、概述
分词器的作用是将一串字符串改为“词”的列表,下面以“大学生活”这个输入为例进行讲解:
对“大学生活”这句话做分词,通常来说,一个分词器会分三步来实现:
(1)找到“大学生活”这句话中的全部词做为一个集合,即:[大、大学、大学生、学、学生、生、生活、活]
(2)在第一步中得到的集合中找到所有能组合成“大学生活”这句话的子集,即:
[大、学、生、活]
[大、学、生活]
[大、学生、活]
[大学、生、活]
[大学、生活]
[大学生、活]
(3)在第二步中产生的所有子集中挑选一个最有可能的作为最终的分词结果。
为了得到第1步需要的集合,通常我们需要一个词典。大部分的分词器都是基于词典去做分词的(也就是说也可以不基于词典来做分词,在此暂时不做讨论)。那么现在假设我们有一个小词典:[大学、大学生、学习、学习机、学生、生气、生活、活着]。首先要在“大学生活”这句话里面匹配到这个词典里面的全部词,有些同学脑中可能会出现这种过程:
public class Demo1{
//加载词典中的所有词汇
static Set<String> dic = new HashSet(){{
add("大学");
add("大学生");
add("学习");
add("学习机");
add("学生");
add("生气");
add("生活");
add("活着");
}};
//匹配句子中词典中存在的所有词汇
static List<String> getAllWordsMatched(String sentence){
List<String> wordList = new ArrayList<>();
for(int index = 0;index < sentence.length();index++){
for(int offset = index+1; offset <= sentence.length();offset++){
String sub = sentence.substring(index,offset);
if(dic.contains(sub)){
wordList.add(sub);
}
}
}
return wordList;
}
public static void main(String[] args){
String sentence = "大学生活";
getAllWordsMatched(sentence).forEach(System.out::println);
}
}
执行这段代码会输出:
大学
大学生
学生
生活
似乎到这里,我们已经完美地完成了在词典中找到词的任务。然而真实的分词器的词典往往有几十万甚至几百万的词汇量,使用上面这种算法性能太低了。高效地实现这种匹配的算法有很多,下面简单介绍一种:
二、AC自动机(Aho-Corasick automaton)
AC自动机是一种常用的多模式匹配算法,基于字典树(trie树)的数据结构和KMP算法的失败指针的思想来实现,有不错的性能并且实现起来非常简单。
2.1、字典树(trie树)
引用一下百度百科对于trie树的描述:Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
下面一个存放了[大学、大学生、学习、学习机、学生、生气、生活、活着]这个词典的trie树:
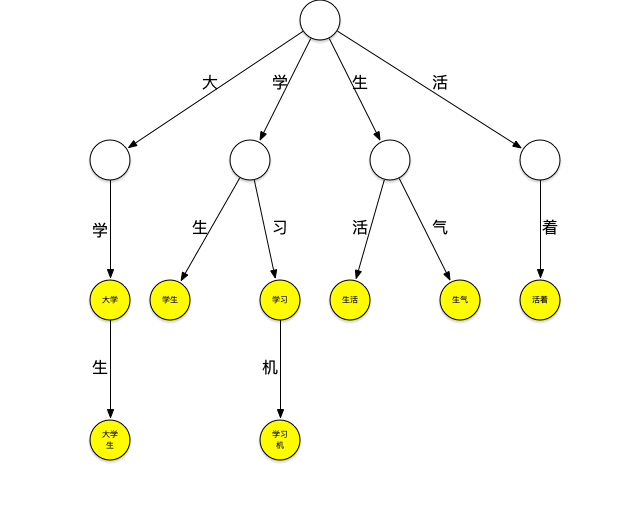
它可以看作是用每个词第n个字做第n到第n+1层节点间路径哈希值的哈希树,每个节点是实际要存放的词。
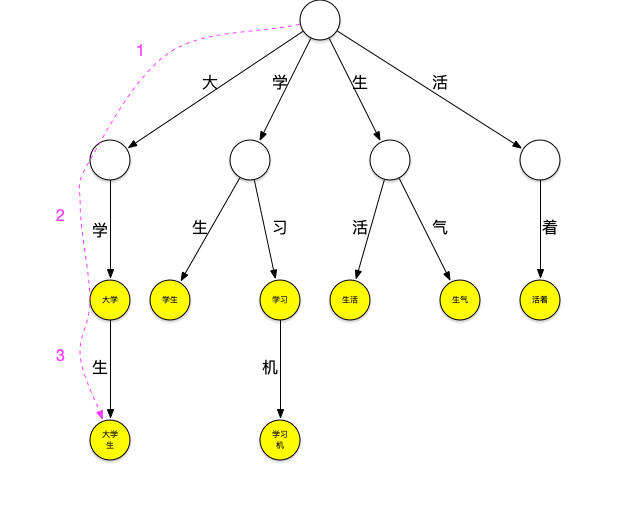
现在用这个树来进行“大学生活”的匹配。依然从“大”字开始匹配,如下图所示:从根节点开始,沿最左边的路径匹配到了大字,沿着“大”节点可以匹配到“大学”,继续匹配则可以匹配到“大学生”,之后字典中再没有以“大”字开头的词,至此已经匹配到了[大学、大学生]第一轮匹配结束。
继续匹配“学”字开头的词,方法同上步,可匹配出[学生]
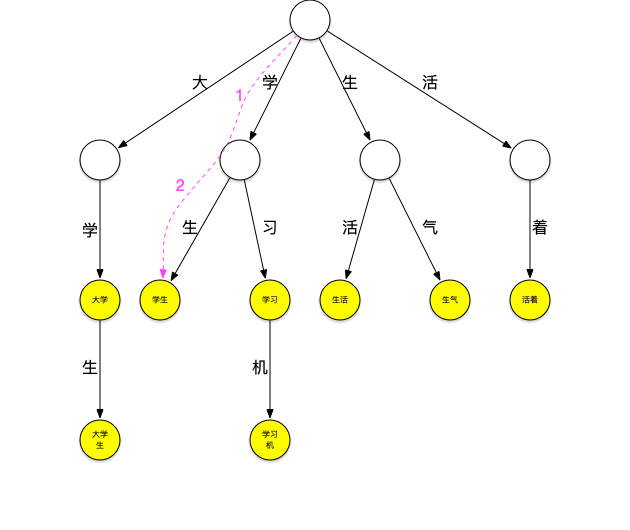
继续匹配“生”和“活”字开头的词,这样“大学生活”在词典中的词全部被查出来。
可以看到,以匹配“大”字开头的词为例,第一种匹配方式需要在词典中查询是否包含“大”、“大学”、“大学”、“大学生活”,共4次查询,而使用trie树查询时当找到“大学生”这个词之后就停止了该轮匹配,减少了匹配的次数,当要匹配的句子越长,这种性能优势就越明显。
2.2、失败指针
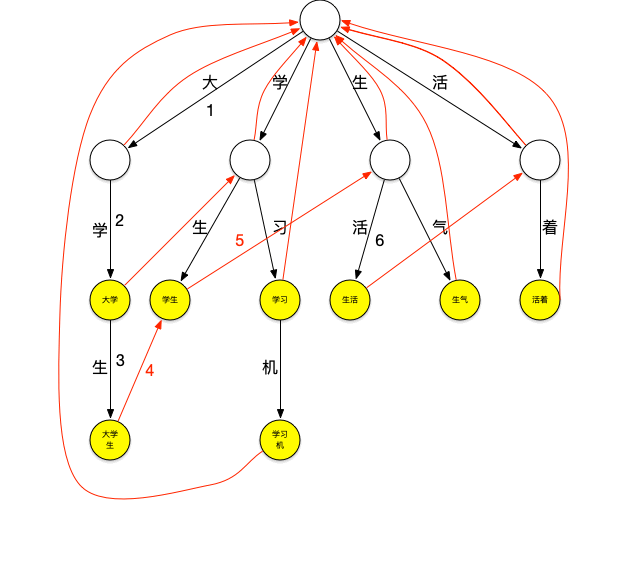
再来看一下上面的匹配过程,在匹配“大学生”这个词之后,由于词典中不存在其它以“大”字开头的词,本轮结束,将继续匹配以“学”字开头的词,这时,需要再回到根节点继续匹配,如果这个时候“大学生”节点有个指针可以直指向“学生”节点,就可以减少一次查询,类似地,当匹配完“学生”之后如果“学生”节点有个指针可以指向“生活”节点,就又可以减少一次查询。这种当下一层节点无法匹配需要进行跳转的指针就是失败指针,创建好失败指针的树看起来如下图:
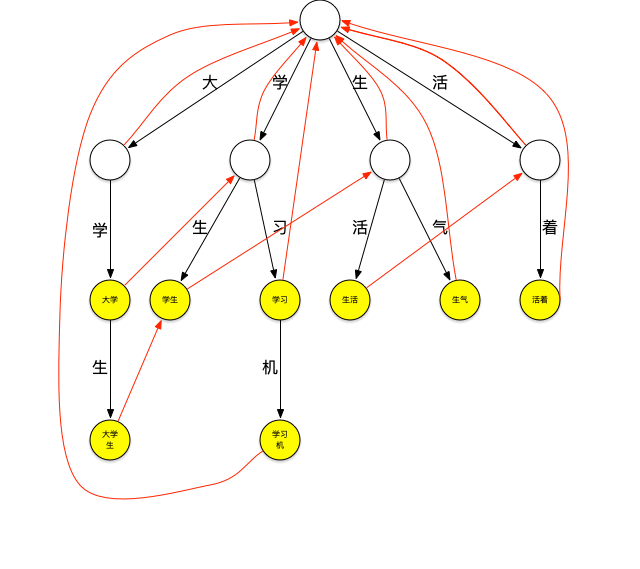
图上红色的线就是失败指针,指向的是当下层节点无法匹配时应该跳转到哪个节点继续进行匹配。
失败指针的创建过程通常为:
1.创建好trie树。
2.BFS每一个节点(不能使用DFS,因为每一层节点的失败指针在创建时要确保上一层节点的失败指针全部创建完成)。
3.根节点的子节点的失败指针指向根节点。
4.其它节点查找其父节点的失败指针指向的节点的子节点是否有和该节点字相同的节点,如果有则失败指针指向该节点,如果没有则重复刚才的过程直至找到字相同的节点或根节点。
查询过程如下:
执行这段代码会输出:
大学
大学生
学生
生活
在匹配到了词典中所有出现在句子中的词之后,继续第二步:在得到的集合中找到所有能组合成“大学生活”这个句子的子集。但是在这个地方遇到了一个小问题,上面查到的4个词中仅有“大学”和“生活”这两个词可以组成“大学生活”这个句子,而“大学生”和“生活”则无法在匹配到的词中找到能够与其连接的词汇。现实情况中,词典很难囊括所有词汇,所以这种情况时有发生。在这里,可以额外将单个字放到匹配到的词的集合中,这得到了一个新集合:
[大学、大学生、学生、生活]U[大、学、生、活] = [大学、大学生、学生、生活、大、学、生、活]
可以用一个有向图来表示这个集合的分词组合,从开始节点到结束节点的全部路径就是所有分词方式。

三、最终的分词结果
那么在这些可能的分词组合中,应该选取哪一种作为最终的分词结果呢?大部分分词器的主要差异也体现在这里,有些分词器可能有很多不同的分词策略供使用者选择。例如最少词策略,就是在有向图中选择能够达到结束节点的全部路径中最短(经过最少节点)的一条。对于上面这张有向图,最短路径有两条,分别是“大学,生活”与“大学生,活”最终的分词结束就在这两条路径中选择一条。这种选择方法最为简单,性能也很高,但是准确性较差。其实仔细考虑一下不难发现,无论使用哪种分词策略,其目的都是想要挑选出一条最可能正确的,也就是概率最大的一种。“大学生活”分词为[大、学、活]的概率为P(大)P(学|大)P(生|大,学)P(活|大,学,生),这就是说,想要计算其的概率,需要知道“大”的出现概率,“大”出现时“学”出现的概率,“大”、“学”同时出现时“生”的概率,“大”,“学”,“生”同时出现时出现“活”的概率。这些出现概率可以在一份由大量文章组成的文本库中统计得出,但是问题是,如果词典要记录任意N个词出现时出现词W的概率,一个存放M个词汇的词典需要存放M^N量级的关系数据,这个词典会太大,所以通常会限制N的大小,一般来说,N为2或者为3,计算条件概率时只考虑到它前面2到3个词,这是基于马尔可夫链做的简化。当N为2时称为二元模型,N为3时称为三元模型。一个有50万词的词典的二元模型需要50万*50万条关系,这也是相当大的一个量级,可以对其进行压缩或转化为其它近似形式,这部分相对比较复杂,在此不作讲解,这里使用更简单一些的形式,假设每个词的出现都是独立事件,令P(大,学,生,活)=P(大)P(学)P(生)P(活)。要计算这个概率,只需要知道每个词的出现概率,一个词的出现概率=词出现的次数/文本库中词总量。那么将之前使用的词典更新为[大学5、大学生4、学习6、学习机3、学生5、生气8、生活7、活着2] 后面的数字是这些词在文本库中出现的次数,文本库中词的问题就是这些词出现次数之和=5+4+6+3+5+8+7+2=40
那么P(大学,生活)=P(大学)P(生活)=5/40*7/40
P(大学生、活)=P(大学生)P(活)=4/40*0/40 在这个地方出现了问题,对于词典里不存在的词,它的概率是0,这将会导致整个乘积是0,这是不合理的,对于这种情况可以做平滑处理,简单地来说,可以设词典中不存在的词的出现次数为1,于是P(大学生、活)=P(大学生)P(活)=4/40*1/40
最终可以挑选出一条最有可能的分词组合。至此第三步结束。
以上就是浅谈分词器Tokenizer的详细内容,更多关于分词器Tokenizer的资料请关注我们其它相关文章!
相关推荐
-
docker 部署 Elasticsearch kibana及ik分词器详解
es安装 docker pull elasticsearch:7.4.0 # -d : 后台运行 # -p : 指定宿主机与docker启动容器的端口映射 # --name : 为 elasticsearch 容器起个别名 # -e : 指定为单节点集群模式 # docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.4.0
-
docker 安装solr8.6.2 配置中文分词器的方法
一.环境版本 Docker version 19.03.12 centos7 solr8.6.2 二.docker安装 1.使用官方安装脚本自动安装 curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 2.使用国内 daocloud 一键安装命令: curl -sSL https://get.daocloud.io/docker | sh 三.docker安装solr8.6.2 1.docker拉取solr doc
-

Java实现简易的分词器功能
业务需求: 生活中常见的搜索功能大概可分为以下几类: 单关键词.如"Notebook" 双关键词加空格.如"Super Notebook" 多关键词加多空格.如"Intel Super Notebook" 当然,还有四甚至五关键词,这些搜索场景在生活中可以用罕见来形容,不在我们的讨论范围.我们今天就以上三种生活中最常见的搜索形式进行探讨分析.业务需求也很简单,假设我们要完成一个搜索功能,业务层.持久层.控制层不在我们讨论的范围,仅讨论分词功能如何
-
基于Java中的StringTokenizer类详解(推荐)
StringTokenizer是字符串分隔解析类型,属于:Java.util包. 1.StringTokenizer的构造函数 StringTokenizer(String str):构造一个用来解析str的StringTokenizer对象.java默认的分隔符是"空格"."制表符('\t')"."换行符('\n')"."回车符('\r')". StringTokenizer(String str,String delim)
-
Solr通过特殊字符分词实现自定义分词器详解
前言 我们在对英文句子分词的时候,一般采用采用的分词器是WhiteSpaceTokenizerFactory,有一次因业务要求,需要根据某一个特殊字符(以逗号分词,以竖线分词)分词.感觉这种需求可能与WhiteSpaceTokenizerFactory相像,于是自己根据Solr源码自定义了分词策略. 业务场景 有一次,我拿到的数据都是以竖线"|"分隔,分词的时候,需要以竖线为分词单元.比如下面的这一堆数据: 有可能你拿到的是这样的数据,典型的例子就是来自csv文件的数据,格式和下面这种
-
如何在docker容器内部安装kibana分词器
步骤: 1.在虚拟机目录下新建docker-compose.yml文件,然后进入yml文件编辑 vi docker-compose.yml 2.在yml文件中添加如下代码: version: "3.1" services: elasticsearch: image: daocloud.io/library/elasticsearch:6.5.4 restart: always container_name: elasticsearch ports: - 9200:9200 #将分词器映
-
JAVA StringBuffer类与StringTokenizer类代码解析
StringBuffer类提供了一个字符串的可变序列,类似于String类,但它对存储的字符序列可以任意修改,使用起来比String类灵活得多.它常用的构造函数为: StringBuffer() 构造一个空StringBuffer对象,初始容量为16个字符. StringBuffer(Stringstr) 构造一个StringBuffer对象,初始内容为字符串str的拷贝. 对于StringBuffer类,除了String类中常用的像长度.字符串截取.字符串检索的方法可以使用之外,还有两个较为
-
安装elasticsearch-analysis-ik中文分词器的步骤讲解
1 安装elasticsearch-analysis-ik中文分词器 Ik介绍:ik是一款中文的分词插件,支持自定义词库. 1.1 下载ik分词器 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases 下载指定版本的分词器(zip版本) 1.2 解压ik分词器 [es@bigdata1 plugins]$ cd /home/es/ [es@bigdata1 ~]$ ls elasticsearch-6.2.2 jdk1.
-
iOS中自带超强中文分词器的实现方法
说明 在处理文本的时候,第一步往往是将字符串进行分词,得到一个个关键词.苹果从很早就开始支持中文分词了,而且我们几乎人人每天都会用到,回想一下,在使用手机时,长按一段文字,往往会选中按住位置的一个词语,这里就是一个分词的绝佳用例,而iOS自带的分词效果非常棒,大家可以自己平常注意观察一下,基本对中文也有很好的效果.而这个功能也开放了API供开发者调用,我试用了一下,很好用! 效果如下: 实现 其实苹果给出了完整的API,想要全面了解的可以直接看文档:CFStringTokenizer Refer
-
浅谈分词器Tokenizer
一.概述 分词器的作用是将一串字符串改为"词"的列表,下面以"大学生活"这个输入为例进行讲解: 对"大学生活"这句话做分词,通常来说,一个分词器会分三步来实现: (1)找到"大学生活"这句话中的全部词做为一个集合,即:[大.大学.大学生.学.学生.生.生活.活] (2)在第一步中得到的集合中找到所有能组合成"大学生活"这句话的子集,即: [大.学.生.活] [大.学.生活] [大.学生.活] [大学.生.活
-
浅谈Javascript数据属性与访问器属性
ES5中对象的属性可以分为'数据属性'和'访问器属性'两种. 数据属性一般用于存储数据数值,访问器属性对应的是set/get操作,不能直接存储数据值. 数据属性特性:value.writable.enumerable.configurable. 解释:configurable:true/false,是否可以通过delete删除属性,能否修改属性的特性,能否把属性修改为访问器属性,默认false: enumerable:true/false,是否可以通过for in循环返回,默认false: wr
-
浅谈JavaScript 数据属性和访问器属性
在JavaScript中对象被定义为"无序属性的集合,其属性可以包含基本值.对象或函数."通俗点讲,我们可以把对象理解为一组一组的名值对,其中值可以是数据或函数. 创建自定义对象通常有两种方法,第一种就是创建一个Object的实例,然后再为其添加属性和方法,例如: var person = new Object(); person.name = "Scott"; person.age = 24; person.sayName = function(){ alert(
-
浅谈python装饰器探究与参数的领取
首先上原文: 现在,假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为"装饰器"(Decorator). 本质上,decorator就是一个返回函数的高阶函数. Decorator本质是高阶函数? 不信邪的我试了下.. def g(): print("这里是G") return "G" @g def f(): print("这里是F&qu
-
浅谈flask截获所有访问及before/after_request修饰器
本文主要研究的是flask如何截获所有访问,以及before_request.after_request修饰器的相关内容,具体如下. 在学习着用flask开发安卓后天接口时,遇到一个需求,就是想截获所有请求,即在所有请求进入app.route装饰的函数前先被处理一次. 经过在网上查找资料后,知道了@before_request.@after_request这两个方法,示例: @app.before_request def before_request(): ip = request.remote
-
浅谈解除装饰器作用(python3新增)
一个装饰器已经作用在一个函数上,你想撤销它,直接访问原始的未包装的那个函数. 假设装饰器是通过 @wraps 来实现的,那么你可以通过访问 wrapped 属性来访问原始函数: >>> @somedecorator >>> def add(x, y): ... return x + y ... >>> orig_add = add.__wrapped__ >>> orig_add(3, 4) 7 >>> 如果有多个包
-
浅谈Pytorch torch.optim优化器个性化的使用
一.简化前馈网络LeNet import torch as t class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__init__() self.features = t.nn.Sequential( t.nn.Conv2d(3, 6, 5), t.nn.ReLU(), t.nn.MaxPool2d(2, 2), t.nn.Conv2d(6, 16, 5), t.nn.ReLU(), t.nn.MaxPool2d(2
-
浅谈JAVA 类加载器
类加载机制 类加载器负责加载所有的类,系统为所有被载入内存中的类生成一个 java.lang.Class 实例.一旦一个类被载入 JVM 中,同个类就不会被再次载入了.现在的问题是,怎么样才算"同一个类"? 正如一个对象有一个唯一的标识一样,一个载入 JVM 中的类也有一个唯一的标识.在 Java 中,一个类用其全限定类名(包括包名和类名)作为标识:但在 JVM 中,一个类用其全限定类名和其类加载器作为唯一标识.例如,如果在 pg 的包中有一个名为 Person 的类,被类加载器 Cl
-
浅谈SpringMVC的拦截器(Interceptor)和Servlet 的过滤器(Filter)的区别与联系 及SpringMVC 的配置文件
1.过滤器: 依赖于servlet容器.在实现上基于函数回调,可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次.使用过滤器的目的是用来做一些过滤操作,获取我们想要获取的数据. 比如:在过滤器中修改字符编码:在过滤器中修改 HttpServletRequest的一些参数,包括:过滤低俗文字.危险字符等 关于过滤器的一些用法可以参考我写过的这些文章: 继承HttpServletRequestWrapper以实现在Filter中修改HttpServletRequest的参
-
浅谈slf4j中的桥接器是如何运作的
阅读分析 slf4j 的日志源码,发现其中涵盖了许多知识点和优秀的设计,关键它们都是活生生的实践案例.写成系列文章与大家分享,欢迎持续关注. 前言 在日志框架 slf4j 中有一组项目,除了核心的 slf4j-api 之外,还有 slf4j-log4j12.slf4j-jdk14 等项目.这一类项目统称桥接器项目,针对不同的日志框架有不同的桥接器项目. 在使用 logback 日志框架时,并没有针对的桥接器,这是因为 logback 与 slf4j 是一个作者所写,在 logback 中直接实现