python爬虫爬取股票的北上资金持仓数据
目录
- 前言
- 数据分析
- 数据抓取
- 建立模型
- 总结
前言
前面已经讲述了如何获取股票的k线数据,今天我们来分析一下股票的资金流入情况,股票的上涨和下跌都是由资金推动的,这其中的北上资金就是一个风向标,今天就抓取一下北上资金对股票的逐天持仓变动和资金变动。
数据分析
照例先贴一下数据的访问地址:
# 以海尔智家为例贴一下数据的页面连接地址,再次吐槽一下拼音前缀 https://data.eastmoney.com/hsgtcg/StockHdStatistics/600690.html
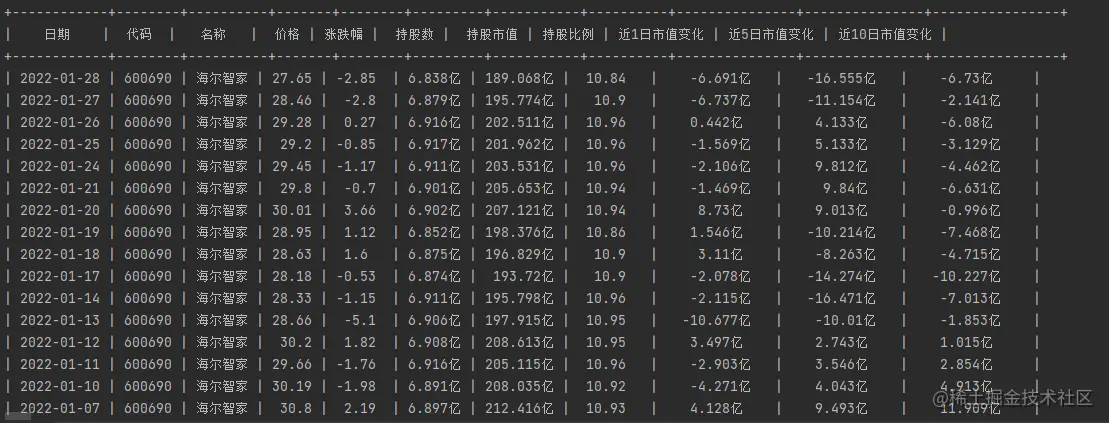
下图就是北上资金逐天的访问数据页面,我们要抓取的是持股数量、持股市值、持股百分比和市值变化信息。
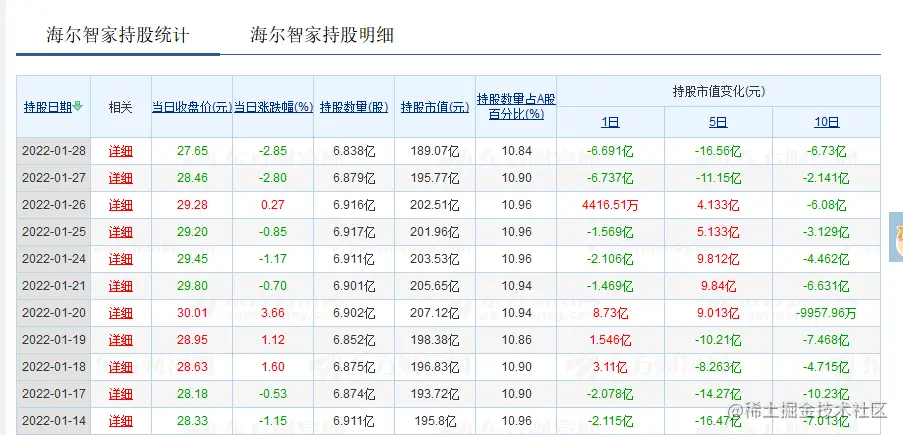
通过浏览器后台的接口可以看到这样一个接口数据:
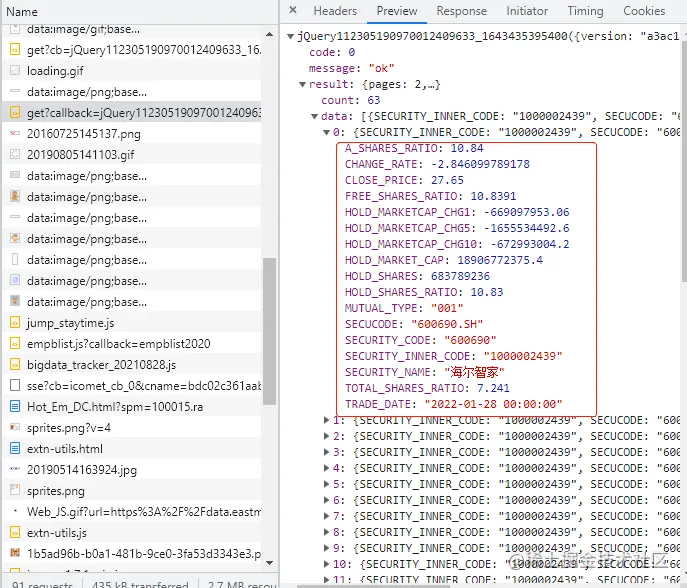
这个接口的参数为:
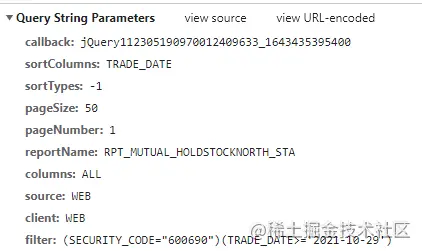
# 请求地址数据,这里的参数和请求的不太一样,因为其它的参数我试过了,可以忽略掉,以下是必要参数 https://datacenter-web.eastmoney.com/api/data/v1/get? # 排序字段和排序的类型, -1 为倒序排列 sortColumns=TRADE_DATE &sortTypes=-1 # 后两个参数比较简单,就是分页参数而已 &pageSize=50 &pageNumber=1 # 报告类型,固定为北上资金数据 &reportName=RPT_MUTUAL_HOLDSTOCKNORTH_STA # 返回的数据列,默认返回所有 &columns=ALL # 获取数据参数为股票代码和交易日期 &filter=(SECURITY_CODE="600690")(TRADE_DATE>='2021-10-29')
数据抓取
我们已经解析了获取资金的参数,以下就是使用 python 来获取数据,并进行展示。我们依旧使用 requets 来获取数据。
我们需要先组装请求的参数,这里的 fliter 只传入了代码,日期选择了固定,这个个人感觉是查询的 ES ,不然不会这么传入参数,建议做个参数转换吧,这样直传不太好。

数据查询返回的结果是json 格式,进行了解析后我们采用 prettyTable 打印结果。
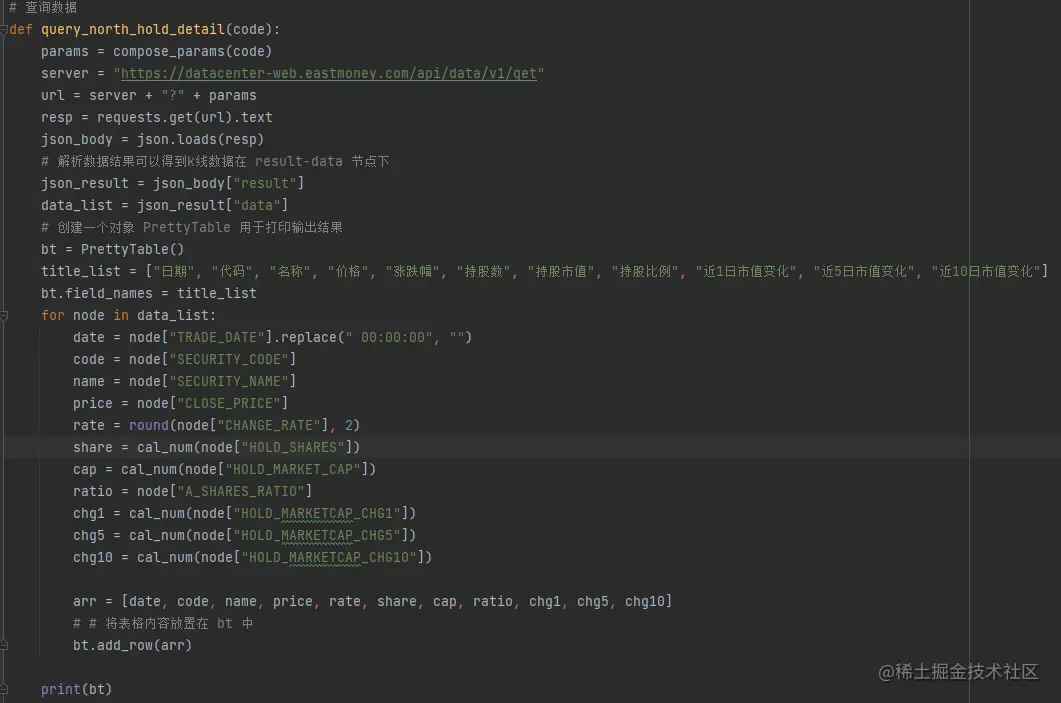
由于获取的数据没有经过格式化,显示的位数比较长,所以对持股数和市值之类的数据进行了格式化展示,
代码如下:
# 如果是亿级的就格式化为亿,万的话格式化为万
def cal_num(num):
if abs(num / 100000000) > 0:
return str(round(num / 100000000, 3)) + "亿"
else:
return str(round(num / 10000, 3)) + "万"
最终我们得到的结果如下:
建立模型
我们已经获取到了股票的北上资金的情况,我们建立一个简单的模型筛选一下:
- 1 选取最近一个月内北上资金连续加仓的股票,加仓幅度超过流通股份的1%。
在这个模型中,我们可以根据最近一个月每天的持仓百分比建立线性规划模型,y = kx + b 来计算斜率和截距,但是这个觉得有点儿复杂了,我们可以简化一下,就偷个懒计算当天的持仓量与一个月前的持仓比例差值即可,
具体代码如下:
# rate_list 为持股比例的集合,将 ratio 添加进集合中,这里为什么是22呢,
# 一般情况下一个月有22个交易日,所以减去22就是一个月前的持仓比例
def cal_model(rate_list):
if len(rate_list) >= 22:
cur_node = rate_list[0]
pre_node = rate_list[22]
return cur_node - pre_node
return -100
总结
今天我们使用接口获取了个股北上资金的持仓数据,并建立了简单的分析模型来选择股票,这个技术实现比较简单,作为学习和练习使用已经就足够了。
到此这篇关于python爬虫爬取股票的北上资金持仓数据的文章就介绍到这了,更多相关python爬取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取股票交易数据并可视化展示
目录 开发环境 第三方模块 爬虫案例的步骤 爬虫程序全部代码 分析网页 导入模块 请求数据 解析数据 翻页 保存数据 实现效果 数据可视化全部代码 导入数据 读取数据 可视化图表 效果展示 开发环境 解释器版本: python 3.8 代码编辑器: pycharm 2021.2 第三方模块 requests: pip install requests csv 爬虫案例的步骤 1.确定url地址(链接地址) 2.发送网络请求 3.数据解析(筛选数据) 4.数据的保存(数据库(mysql\mong
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
python多线程+代理池爬取天天基金网、股票数据过程解析
简介 提到爬虫,大部分人都会想到使用Scrapy工具,但是仅仅停留在会使用的阶段.为了增加对爬虫机制的理解,我们可以手动实现多线程的爬虫过程,同时,引入IP代理池进行基本的反爬操作. 本次使用天天基金网进行爬虫,该网站具有反爬机制,同时数量足够大,多线程效果较为明显. 技术路线 IP代理池 多线程 爬虫与反爬 编写思路 首先,开始分析天天基金网的一些数据.经过抓包分析,可知: ./fundcode_search.js包含所有基金的数据,同时,该地址具有反爬机制,多次访问将会失败的情况. 同时,经
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
基于Python爬取股票数据过程详解
基本环境配置 python 3.6 pycharm requests csv time 相关模块pip安装即可 目标网页 分析网页 一切的一切都在图里 找到数据了,直接请求网页,解析数据,保存数据 请求网页 import requests url = 'https://xueqiu.com/service/v5/stock/screener/quote/list' response = requests.get(url=url, params=params, headers=headers, c
-
python爬虫爬取股票的北上资金持仓数据
目录 前言 数据分析 数据抓取 建立模型 总结 前言 前面已经讲述了如何获取股票的k线数据,今天我们来分析一下股票的资金流入情况,股票的上涨和下跌都是由资金推动的,这其中的北上资金就是一个风向标,今天就抓取一下北上资金对股票的逐天持仓变动和资金变动. 数据分析 照例先贴一下数据的访问地址: # 以海尔智家为例贴一下数据的页面连接地址,再次吐槽一下拼音前缀 https://data.eastmoney.com/hsgtcg/StockHdStatistics/600690.html 下图就是北上资
-
python爬虫爬取股票的k线图
目录 前言 数据来源分析 数据抓取 总结 前言 之前已经讲述了一些关于 python 获取基金的一些信息,最近又有了一些新发现,和大家分享一下,这个是非常重要的内容,非常重要的内容.这个数据也是非常的敏感,在一些搞量化交易的平台上,这些数据都是要收费的,而且数据的质量也不能保障.这个内容就是如何获取股票交易的 k 线数据. 数据来源分析 我是非常欣赏东方某富的,因为同为券商,和别的公司确实不大一样,有这互联网的基因,可以这样说,是因为它的出现改变了一些行业的规则.话不多说,这里以海尔智家为例,抓
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python爬虫爬取新浪微博内容示例【基于代理IP】
本文实例讲述了Python爬虫爬取新浪微博内容.分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474) 一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站.当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选.一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn. 前期准备 1.代理IP 网上有