浅谈MySQL中是如何实现事务提交和回滚的
目录
- 什么是事务
- redo log
- undo log
- 总结一下
什么是事务
事务是由数据库中一系列的访问和更新组成的逻辑执行单元
事务的逻辑单元中可以是一条SQL语句,也可以是一段SQL逻辑,这段逻辑要么全部执行成功,要么全部执行失败
举个最常见的例子,你早上出去买早餐,支付宝扫码付款给早餐老板,这就是一个简单的转账过程,会包含两步
- 从你的支付宝账户扣款10元
- 早餐老板的账户增加10元
这两步其中任何一部出现问题,都会导致整个账务出现问题
- 假如你的支付宝账户扣款10元失败,早餐老板的账户增加成功,那你就Happy了,相当于马云请你吃早餐了,O(∩_∩)O哈哈~
- 假如你的支付宝账户扣款10元成功,早餐老板的账户增加失败,那你就悲剧了,早餐老板不会放过你,会让你重新付款,相当于你请马云吃早餐了-_-?
事务就是用来保证一系列操作的原子性,上述两步操作,要么全部执行成功,要么全部执行失败
数据库为了保证事务的原子性和持久性,引入了redo log和undo log
redo log
redo log是重做日志,通常是物理日志,记录的是物理数据页的修改,它用来恢复提交后的物理数据页

如上图所示,redo log分为两部分:
- 内存中的redo log Buffer是日志缓冲区,这部分数据是容易丢失的
- 磁盘上的redo log file是日志文件,这部分数据已经持久化到磁盘,不容易丢失
SQL操作数据库之前,会先记录重做日志,为了保证效率会先写到日志缓冲区中(redo log Buffer),再通过缓冲区写到磁盘文件中进行持久化,既然有缓冲区说明数据不是实时写到redo log file中的,那么假如redo log写到缓冲区后,此时服务器断电了,那redo log岂不是会丢失?
在MySQL中可以自已控制log buffer刷新到log file中的频率,通过innodb_flush_log_at_trx_commit参数可以设置事务提交时log buffer如何保存到log file中,innodb_flush_log_at_trx_commit参数有3个值(0、1、2),表示三种不同的方式
- 为1表示事务每次提交都会将log buffer写入到os buffer,并调用操作系统的fsync()方法将日志写入log file,这种方式的好处是就算MySQL崩溃也不会丢数据,redo log file保存了所有已提交事务的日志,MySQL重新启动后会通过redo log file进行恢复。但这种方式每次提交事务都会写入磁盘,IO性能较差
- 为0表示事务提交时不会将log buffer写入到os buffer中,而是每秒写入os buffer然后调用fsync()方法将日志写入log file,这种方式在MySQL系统崩溃时会丢失大约1秒钟的数据
- 为2表示事务每次提交仅将log buffer写入到os buffer中,然后每秒调用fsync()方法将日志写入log file,这种方式在MySQL崩溃时也会丢失大约1秒钟的数据
undo log
undo log是回滚日志,用来回滚行记录到某个版本,undo log一般是逻辑日志,根据行的数据变化进行记录
undo log跟redo log一样也是在SQL操作数据之前记录的,也就是SQL操作先记录日志,再进行操作数据
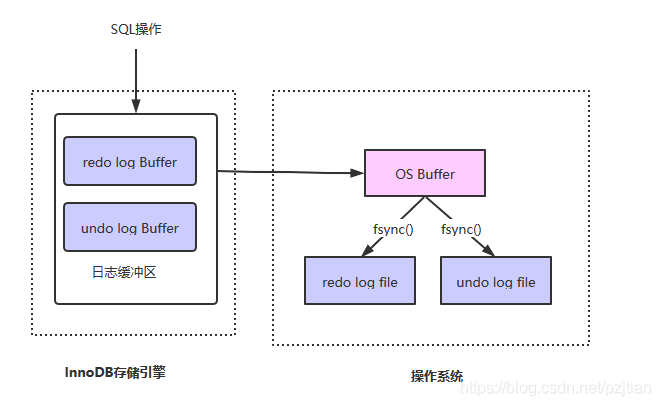
如上图所示,SQL操作之前会先记录redo log、undo log到日志缓冲区,日志缓冲区的数据会记录到os buffer中,再通过调用fsync()方法将日志记录到log file中
undo log记录的是逻辑日志,可以简单的理解为:当insert一条记录时,undo log会记录一条对应的delete语句;当update一条语句时,undo log记录的是一条与之操作相反的语句
当事务需要回滚时,可以从undo log中找到相应的内容进行回滚操作,回滚后数据恢复到操作之前的状态
undo日志还有一个用途就是用来控制数据的多版本(MVCC),在《InnoDB存储引擎中的锁》一文中讲到MVCC是通过读取undo日志中数据的快照来进行多版本控制的
undo log是采用段(segment)的方式来记录的,每个undo操作在记录的时候占用一个undo log segment。
另外,undo log也会产生redo log,因为undo log也要实现持久性保护
总结一下
MySQL中是如何实现事务提交和回滚的?
- 为了保证数据的持久性,数据库在执行SQL操作数据之前会先记录redo log和undo log
- redo log是重做日志,通常是物理日志,记录的是物理数据页的修改,它用来恢复提交后的物理数据页
- undo log是回滚日志,用来回滚行记录到某个版本,undo log一般是逻辑日志,根据行的数据变化进行记录
- redo/undo log都是写先写到日志缓冲区,再通过缓冲区写到磁盘日志文件中进行持久化保存
- undo日志还有一个用途就是用来控制数据的多版本(MVCC)
简单理解就是:
- redo log是用来恢复数据的,用于保障已提交事务的持久性
- undo log是用来回滚事务的,用于保障未提交事务的原子性
到此这篇关于浅谈MySQL中是如何实现事务提交和回滚的的文章就介绍到这了,更多相关MySQL 事务提交和回滚内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql实现事务的提交和回滚实例
mysql创建存储过程的官方语法为: 复制代码 代码如下: START TRANSACTION | BEGIN [WORK]COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]SET AUTOCOMMIT = {0 | 1} 我这里要说明的mysql事务处理多个SQL语句的回滚情况.比如说在一个存储过程中启动一个事务,这个事务同时往三个表中插入数据,每插完一张表需要
-

Mysql事务隔离级别之读提交详解
查看mysql 事务隔离级别 mysql> show variables like '%isolation%'; +---------------+----------------+ | Variable_name | Value | +---------------+----------------+ | tx_isolation | READ-COMMITTED | +---------------+----------------+ 1 row in set (0.00 sec) 可以看到
-
python连接mysql并提交mysql事务示例
复制代码 代码如下: # -*- coding: utf-8 -*-import sysimport MySQLdbreload(sys)sys.setdefaultencoding('utf-8')class DB(object): def __init__(self,host='127.0.0.1',port=3306,user='root',passwd='123',database=''): self.__host=host self.__port=port self.__user
-
MySQL找出未提交事务信息的方法分享
前阵子,我写了一篇博客"ORACLE中能否找到未提交事务的SQL语句", 那么在MySQL数据库中,我们能否找出未提交事务执行的SQL语句或未提交事务的相关信息呢? 实验验证了一下,如果一个会话(连接)里面有一个未提交事务,然后不做任何操作,那么这个线程处于Sleep状态 mysql> select connection_id() from dual; +-----------------+ | connection_id() | +-----------------+ | 6
-
浅谈MySQL中是如何实现事务提交和回滚的
目录 什么是事务 redo log undo log 总结一下 什么是事务 事务是由数据库中一系列的访问和更新组成的逻辑执行单元 事务的逻辑单元中可以是一条SQL语句,也可以是一段SQL逻辑,这段逻辑要么全部执行成功,要么全部执行失败 举个最常见的例子,你早上出去买早餐,支付宝扫码付款给早餐老板,这就是一个简单的转账过程,会包含两步 从你的支付宝账户扣款10元 早餐老板的账户增加10元 这两步其中任何一部出现问题,都会导致整个账务出现问题 假如你的支付宝账户扣款10元失败,早餐老板的账户增加成功
-
浅谈MySQL中的六种日志
目录 (一)概述 (二)redo log (三)undo log (四)bin log (五)error log (六)slow query log (七)general log (一)概述 MySQL中存在着以下几种日志:重写日志(redo log).回滚日志(undo log).二进制日志(bin log).错误日志(error log).慢查询日志(slow query log).一般查询日志(general log). MySQL中的数据变化会体现在上面这些日志中,比如事务操作会体现在r
-
浅谈mysql中多表不关联查询的实现方法
大家在使用MySQL查询时正常是直接一个表的查询,要不然也就是多表的关联查询,使用到了左联结(left join).右联结(right join).内联结(inner join).外联结(outer join).这种都是两个表之间有一定关联,也就是我们常常说的有一个外键对应关系,可以使用到 a.id = b.aId这种语句去写的关系了.这种是大家常常使用的,可是有时候我们会需要去同时查询两个或者是多个表的时候,这些表又是没有互相关联的,比如要查user表和user_history表中的某一些数据
-
浅谈MySQL中group_concat()函数的排序方法
group_concat()函数的参数是可以直接使用order by排序的.666.. 下面通过例子来说明,首先看下面的t1表. 比如,我们要查看每个人的多个分数,将该人对应的多个分数显示在一起,分数要从高到底排序. 可以这样写: SELECT username,GROUP_CONCAT(score ORDER BY score DESC) AS myScore FROM t1 GROUP BY username; 效果如下: 以上这篇浅谈MySQL中group_concat()函数的排序方法就
-
浅谈MySQL中授权(grant)和撤销授权(revoke)用法详解
MySQL 赋予用户权限命令的简单格式可概括为: grant 权限 on 数据库对象 to 用户 一.grant 普通数据用户,查询.插入.更新.删除 数据库中所有表数据的权利 grant select on testdb.* to common_user@'%' grant insert on testdb.* to common_user@'%' grant update on testdb.* to common_user@'%' grant delete on testdb.* to c
-
浅谈mysql中concat函数,mysql在字段前/后增加字符串
MySQL中concat函数 使用方法: CONCAT(str1,str2,-) 返回结果为连接参数产生的字符串.如有任何一个参数为NULL ,则返回值为 NULL. 注意: 如果所有参数均为非二进制字符串,则结果为非二进制字符串. 如果自变量中含有任一二进制字符串,则结果为一个二进制字符串. 一个数字参数被转化为与之相等的二进制字符串格式:若要避免这种情况,可使用显式类型 cast, 例如: SELECT CONCAT(CAST(int_col AS CHAR), char_col) MySQ
-
浅谈Mysql中类似于nvl()函数的ifnull()函数
IFNULL(expr1,expr2) 如果expr1不是NULL,IFNULL()返回expr1,否则它返回expr2.IFNULL()返回一个数字或字符串值,取决于它被使用的上下文环境. mysql> select IFNULL(1,0); -> 1 mysql> select IFNULL(0,10); -> 0 mysql> select IFNULL(1/0,10); -> 10 mysql> select IFNULL(1/0,'yes'); ->
-
浅谈MySQL中的自增主键用完了怎么办
在面试中,大家应该经历过如下场景 面试官:"用过mysql吧,你们是用自增主键还是UUID?" 你:"用的是自增主键" 面试官:"为什么是自增主键?" 你:"因为采用自增主键,数据在物理结构上是顺序存储,性能最好,blabla-" 面试官:"那自增主键达到最大值了,用完了怎么办?" 你:"what,没复习啊!!" (然后,你就可以回去等通知了!) 这个问题是一个粉丝给我提的,我觉得
-
浅谈MySQL中float、double、decimal三个浮点类型的区别与总结
下表中规划了每个浮点类型的存储大小和范围: 类型 大小 范围(有符号) 范围(无符号) 用途 ==float== 4 bytes (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) 0,(1.175 494 351 E-38,3.402 823 466 E+38) 单精度 浮点数值 ==double== 8 bytes (-1.797 693 134 862 315 7 E
-
浅谈MYSQL中树形结构表3种设计优劣分析与分享
目录 简介 问题 设计1:邻接表 表设计 SQL示例 设计2:路径枚举 表设计 SQL示例 设计3:闭包表 表设计 SQL示例 结合使用 表设计 总结 简介 在开发中经常遇到树形结构的场景,本文将以部门表为例对比几种设计的优缺点: 问题 需求背景:根据部门检索人员, 问题:选择一个顶级部门情况下,跨级展示当前部门以及子部门下的所有人员,表怎么设计更合理 ? 递归吗 ?递归可以解决,但是势必消耗性能 设计1:邻接表 注:(常见父Id设计) 表设计 CREATE TABLE `dept_info01