scrapy在python爬虫中搭建出错的解决方法
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了。一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题。有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点。
问题描述:
安装位置:
环境变量:

解决办法:
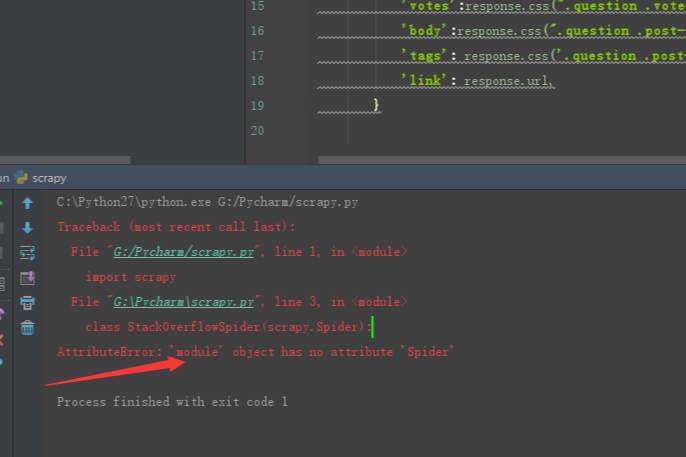
文件命名叫 scrapy.py,明显和scrapy自己的包名冲突了,这里
class StackOverFlowSpider(scrapy.Spider)
会直接找当前文件(scrapy.py)的Spider属性。
说了这么多,其实就是文件命名问题,所以总结一下经验教训哦
平时一定不要使用和包名或者build-in 函数相同的命名。
到此这篇关于scrapy在python爬虫中搭建出错的解决方法的文章就介绍到这了,更多相关scrapy在python爬虫中搭建出错怎么办内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能.分享给大家供大家参考,具体如下: 一.背景: 小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了. 代理: 代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须
-
python爬虫库scrapy简单使用实例详解
最近因为项目需求,需要写个爬虫爬取一些题库.在这之前爬虫我都是用node或者php写的.一直听说python写爬虫有一手,便入手了python的爬虫框架scrapy. 下面简单的介绍一下scrapy的目录结构与使用: 首先我们得安装scrapy框架 pip install scrapy 接着使用scrapy命令创建一个爬虫项目: scrapy startproject questions 相关文件简介: scrapy.cfg: 项目的配置文件 questions/: 该项目的python模块.之
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import MongoClient mongoclient = MongoClien
-
scrapy在python爬虫中搭建出错的解决方法
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了.一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题.有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点. 问题描述: 安装位置: 环境变量: 解决办法: 文件命名叫 scrapy.py,明显和scrapy自己的包名冲突了,这里 class StackOverFlowSpider(scrapy.Spider) 会直接找当前文件(scrapy.py
-
python爬虫中抓取指数的实例讲解
有一些数据我们是没法直观的查看的,需要通过抓取去获得.听到指数这个词,有的小伙伴们觉得很复杂,似乎只在股票的时候才听说的,比如一些数据的涨跌分析都是比较棘手的问题.不过指数对于我们的数据分析还是很有帮助的,今天小编就python爬虫中抓取指数得方法给大家带来讲解. 刚好这几天需要用到这个爬虫,结果发现baidu指数的请求有点变化,所以就改了改: import requests import sys import time word_url = 'http://index.baidu.com/ap
-
scrapy处理python爬虫调度详解
学习了简单的知识点,就会想要向有难度的问题挑战,这里必须要夸一夸小伙伴们.不过我们今天不需要做什么程序的测试,只用简单的两个代码对比,小伙伴们就能在其中体会两者的不同和难易程度.scrapy能否适合处理python爬虫调度的问题,小编直接说出答案小伙伴们也不能马上信服,下面就让我们在示例中找寻答案吧. 总的来说,需要使用代码来爬一些数据的大概分为两类人: 非程序员,需要爬一些数据来做毕业设计.市场调研等等,他们可能连 Python 都不是很熟: 程序员,需要设计大规模.分布式.高稳定性的爬虫系统
-
python爬虫中采集中遇到的问题整理
在爬虫的获取数据上,一直在讲一些爬取的方法,想必小伙伴们也学习了不少.在学习的过程中遇到了问题,大家也会一起交流解决,找出不懂和出错的地方.今天小编想就爬虫采集数据时遇到的问题进行一个整理,以及在遇到不同的问题时,我们应该想的是什么样的解决思路,具体内容如下分享给大家. 1.需要带着cookie信息访问 比如大多数的社交化软件,基本上都是需要用户登录之后,才能看到有价值的东西,其实很简单,我们可以使用Python提供的cookielib模块,实现每次访问都带着源网站给的cookie信息去访问,这
-
Python爬虫中urllib3与urllib的区别是什么
目录 urllib库 urllib.request模块 Request对象 1 . 请求头添加 2. 操作cookie 3. 设置代理 urllib.parse模块 urllib.error模块 urllib.robotparse模块 网络库urllib3 网络请求 GET请求 POST请求 HTTP响应头 上传文件 超时处理 urllib库 urllib 是一个用来处理网络请求的python标准库,它包含4个模块. urllib.request---请求模块,用于发起网络请求 urllib.p
-
python爬虫中多线程的使用详解
queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue.python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性. #多线程实战栗子(糗百) #用一个队列Queue对象, #先产生所有url,put进队列: #开启多线程,把q
-
python爬虫中PhantomJS加载页面的实例方法
PhantomJS作为常用获取页面的工具之一,我们已经讲过页面测试.代码评估和捕获屏幕这几种使用的方式.当然最厉害的还是网页方面的捕捉,这里就不再讲述了.今天我们要讲的是它加载页面的新方法,这个可能很多人不知道.其实经常会用到,感兴趣的小伙伴一起进入今天的学习之中吧~ 可以利用 phantom 来实现页面的加载,下面的例子实现了页面的加载并将页面保存为一张图片. var page = require('webpage').create();page.open('http://cuiqingcai
-
celery在python爬虫中定时操作实例讲解
使用定时功能对于我们想要快速获取某个数据来说,是一个非常好的方法.这样我们就不用苦苦守在电脑屏幕前,只为蹲到某个想要的东西.在之前我们已经讲过time函数进行定时操作,这算是time函数的比较基础的一个用法了.其实定时功能同样可以用celery实现,具体的方法我们往下看: 爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能.在上述基础上,我们将`tasks.py`文件改成如下内容 from celery impor
-
python爬虫中url管理器去重操作实例
当我们需要有一批货物需要存放时,最好的方法就是有一个仓库进行保管.我们可以把URL管理器看成一个收集了数据的大仓库,而下载器就是这个仓库货物的搬运者.关于下载器的问题,我们暂且不谈.本篇主要讨论的是在url管理器中,我们遇到重复的数据应该如何识别出来,避免像仓库一样过多的囤积相同的货物.听起来是不是很有意思,下面我们一起进入今天的学习. URL管理器到底应该具有哪些功能? URL下载器应该包含两个仓库,分别存放没有爬取过的链接和已经爬取过的链接. 应该有一些函数负责往上述两个仓库里添加链接 应该
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是