Pandas多列值合并成一列的实现
在平时的需求开发中涉及到将多列值合并为一列值的操作,通过查阅相关资料特此记录以下方法,方便日后学习复盘
import pandas as pd
import numpy as np
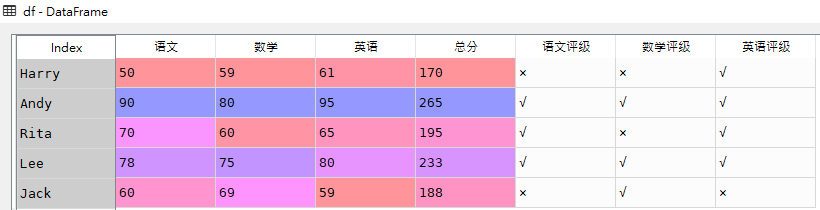
df = pd.DataFrame(data={'语文':[50,90,70,78,60],
'数学':[59,80,60,75,69],
'英语':[61,95,65,80,59]},
index=['Harry','Andy','Rita','Lee','Jack'])
# 添加'总分'字段
df['总分'] = df['语文'] + df['数学'] + df['英语']
# 调用np.where
# 添加'语文评级','数学评级','英语评级'字段
df['语文评级'] = np.where(df['语文'] > 60,'√','×')
df['数学评级'] = np.where(df['数学'] > 60,'√','×')
df['英语评级'] = np.where(df['英语'] > 60,'√','×')
df
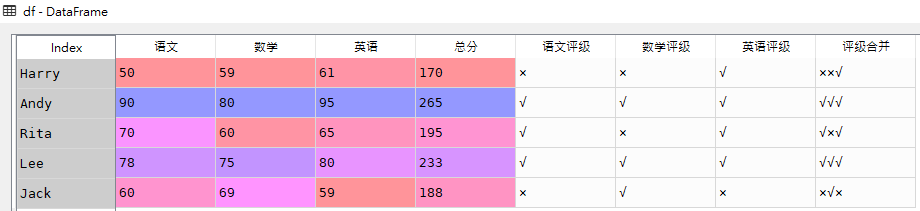
多列合并为一列可以使用map函数转为字符型,再用加号进行连接
# 将多列合并为一列,生成'评级合并'字段 df['评级合并'] = df['语文评级'].map(str) + df['数学评级'].map(str) + df['英语评级'].map(str)
到此这篇关于Pandas多列值合并成一列的实现的文章就介绍到这了,更多相关Pandas多列值合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python pandas合并Sheet,处理列乱序和出现Unnamed列的解决
使用python中的pandas,xlrd,openpyxl库完成合并excel中指定sheet的操作 # -*- coding: UTF-8 -*- import xlrd import pandas as pd from pandas import DataFrame from openpyxl import load_workbook #表格位置 excel_name = '1.xlsx' # 获取workbook中所有的表格 wb = xlrd.open_workbook(excel_n
-

pandas 实现某一列分组,其他列合并成list
pandas列转换为字典,但将相同第一列(键)的所有值合并为一个键 形式一: import pandas as pd # data data = pd.DataFrame({'column1':['key1','key1','key2','key2'], 'column2':['value1','value2','value3','value3']}) print(data) # Grouped dict data_dict = data.groupby('column1').column2.a
-
pandas DataFrame实现几列数据合并成为新的一列方法
问题描述 我有一个用于模型训练的DataFrame如下图所示: 其中的country.province.city.county四列其实是位置信息的不同层级,应该合成一列用于模型训练 方法: parent_teacher_data['address'] = parent_teacher_data['country']+parent_teacher_data['province']+parent_teacher_data['city']+parent_teacher_data['county'] 就
-
pandas将DataFrame的几列数据合并成为一列
目录 1.1 方法归纳 1.2 .str.cat函数详解 1.2.1 语法格式: 1.2.2 参数说明: 1.2.3 核心功能: 1.2.4 常见范例: 1.1 方法归纳 使用 + 直接将多列合并为一列(合并列较少): 使用pandas.Series.str.cat方法,将多列合并为一列(合并列较多): 范例如下: dataframe["newColumn"] = dataframe["age"].map(str) + dataframe["phone&q
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
用pandas按列合并两个文件的实例
直接上图,图文并茂,相信你很快就知道要干什么. A文件: B文件: 可以发现,A文件中"汉字井号"这一列和B文件中"WELL"这一列的属性相同,以这一列为主键,把B文件中"TIME"这一列数据添加到A文件中,如果B文件缺少某些行,则空着,最后A文件的行数不变,效果如下: 代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 16:02:05 2017 @aut
-
Pandas多列值合并成一列的实现
在平时的需求开发中涉及到将多列值合并为一列值的操作,通过查阅相关资料特此记录以下方法,方便日后学习复盘 import pandas as pd import numpy as np df = pd.DataFrame(data={'语文':[50,90,70,78,60], '数学':[59,80,60,75,69], '英语':[61,95,65,80,59]}, index=['Harry','Andy','Rita','Lee','Jack']) # 添加'总分'字段 df['总分'] =
-
mysql 将列值转变为列的方法
复制代码 代码如下: -- 创建库CREATE TABLE `rate` ( `uname` VARCHAR (300), `object` VARCHAR (300), `score` VARCHAR (300)); -- 插入数据INSERT INTO test.rate (uname, object, score) VALUES('aaa', 'chinese', '67'), ('aaa', 'math', '89'), ('aaa', 'physical', '89'), ('bbb'
-
pandas DataFrame 根据多列的值做判断,生成新的列值实例
环境:Python3.6.4 + pandas 0.22 主要是DataFrame.apply函数的应用,如果设置axis参数为1则每次函数每次会取出DataFrame的一行来做处理,如果axis为1则每次取一列. 如代码所示,判断如果城市名中含有ing字段且年份为2016,则新列test值赋为1,否则为0. import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'S
-
使用pandas实现筛选出指定列值所对应的行
在pandas中怎么样实现类似mysql查找语句的功能: select * from table where column_name = some_value; pandas中获取数据的有以下几种方法: 布尔索引 位置索引 标签索引 使用API 假设数据如下: import pandas as pd import numpy as np df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(), 'B': 'one one
-
mysql 列转行,合并字段的方法(必看)
数据表: 列转行:利用max(case when then) max---聚合函数 取最大值 (case course when '语文' then score else 0 end) ---判断 as 语文---别名作为列名 SELECT `name`, MAX( CASE WHEN course='语文' THEN score END ) AS 语文, MAX( CASE WHEN course='数学' THEN score END ) AS 数学, MAX( CASE WHEN cour
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
numpy 进行数组拼接,分别在行和列上合并的实例
在进行数据分析的时候,会把把一些具有多个特征的样本数据进行拼接合并吗,放在一起分析,预测.... 下面是用numpy中的函数进行数组的拼接. (1)方法一.np.vstack() v 表示vertical 垂直,也就是竖着拼接 和np.hstack() h表示Horizontal 横向 (2)方法二,np.c_[array1,array2] c_表示colum列 np.r_[array1,array2] r_表示row行 以上这篇numpy 进行数组拼接,分别在行和列上合并的实例就是小编分享给大
-
对Python中DataFrame选择某列值为XX的行实例详解
如下所示: #-*-coding:utf8-*- import pandas as pd all_data=pd.read_csv("E:/协和问答系统/SenLiu/熵测试数据.csv") #获取某一列值为xx的行的候选列数据 print(all_data) feature_data=all_data.iloc[:,[0,-1]][all_data[all_data.T.index[0]]=='青年'] print(feature_data) 实验结果如下: "C:\Pro