python DataFrame的shift()方法的使用
目录
- 语法
- 示例
在python数据分析中,可以使用shift()方法对DataFrame对象的数据进行位置的前滞、后滞移动。
语法
DataFrame.shift(periods=1, freq=None, axis=0)
- periods可以理解为移动幅度的次数,shift默认一次移动1个单位,也默认移动1次(periods默认为1),则移动的长度为1 * periods。
- periods可以是正数,也可以是负数。负数表示前滞,正数表示后滞。
- freq是一个可选参数,默认为None,可以设为一个timedelta对象。适用于索引为时间序列数据时。
- freq为None时,移动的是其他数据的值,即移动periods*1个单位长度。
- freq部位None时,移动的是时间序列索引的值,移动的长度为periods * freq个单位长度。
- axis默认为0,表示对列操作。如果为行则表示对行操作。
移动滞后没有对应值的默认为NaN。
示例
period为正,无freq
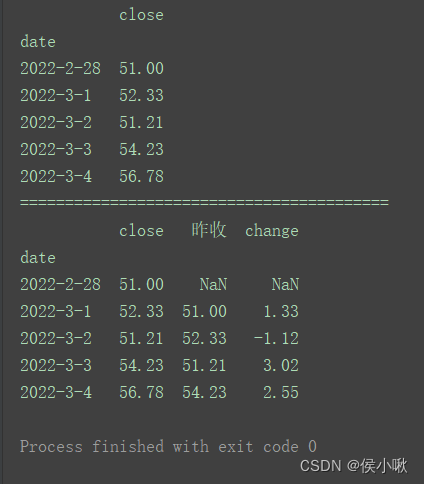
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
data = [51.0, 52.33, 51.21, 54.23, 56.78]
index = ['2022-2-28', '2022-3-1', '2022-3-2', '2022-3-3', '2022-3-4']
df = pd.DataFrame(data=data, index=index, columns=['close'])
df.index.name = 'date'
print(df)
print("=========================================")
df['昨收'] = df['close'].shift()
df['change'] = df['close'] - df['close'].shift()
print(df)
period为负,无freq
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
data = [51.0, 52.33, 51.21, 54.23, 56.78]
index = ['2022-2-28', '2022-3-1', '2022-3-2', '2022-3-3', '2022-3-4']
index = pd.to_datetime(index)
index.name = 'date'
df = pd.DataFrame(data=data, index=index, columns=['昨收'])
print(df)
print("=========================================")
df['close'] = df['昨收'].shift(-1)
df['change'] = df['昨收'].shift(-1) - df['close']
print(df)

period为正,freq为正
import pandas as pd
import datetime
pd.set_option('display.unicode.east_asian_width', True)
data = [51.0, 52.33, 51.21, 54.23, 56.78]
index = ['2022-2-28', '2022-3-1', '2022-3-2', '2022-3-3', '2022-3-4']
index = pd.to_datetime(index)
index.name = 'date'
df = pd.DataFrame(data=data, index=index, columns=['close'])
print(df)
print("=========================================")
print(df.shift(periods=2, freq=datetime.timedelta(3)))
如图,索引列的时间序列数据滞后了6天。(二乘以三)

period为正,freq为负
import pandas as pd
import datetime
pd.set_option('display.unicode.east_asian_width', True)
data = [51.0, 52.33, 51.21, 54.23, 56.78]
index = ['2022-2-28', '2022-3-1', '2022-3-2', '2022-3-3', '2022-3-4']
index = pd.to_datetime(index)
index.name = 'date'
df = pd.DataFrame(data=data, index=index, columns=['close'])
print(df)
print("=========================================")
print(df.shift(periods=3, freq=datetime.timedelta(-3)))
如图,索引列的时间序列数据前滞了9天(三乘以负三)

period为负,freq为负
import pandas as pd
import datetime
pd.set_option('display.unicode.east_asian_width', True)
data = [51.0, 52.33, 51.21, 54.23, 56.78]
index = ['2022-2-28', '2022-3-1', '2022-3-2', '2022-3-3', '2022-3-4']
index = pd.to_datetime(index)
index.name = 'date'
df = pd.DataFrame(data=data, index=index, columns=['close'])
print(df)
print("=========================================")
print(df.shift(periods=-3, freq=datetime.timedelta(-3)))
如图,索引列的时间序列数据滞后了9天(负三乘以负三)

到此这篇关于python DataFrame的shift()方法的使用的文章就介绍到这了,更多相关python DataFrame shift() 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python pandas.DataFrame 找出有空值的行
0.摘要 pandas中DataFrame类型中,找出所有有空值的行,可以使用.isnull()方法和.any()方法. 1.找出含有空值的行 方法:DataFrame[DataFrame.isnull().T.any()] 其中,isnull()能够判断数据中元素是否为空值:T为转置:any()判断该行是否有空值. import pandas as pd import numpy as np n = np.arange(20, dtype=float).reshape(5,4) n[2,3]
-
Python DataFrame使用drop_duplicates()函数去重(保留重复值,取重复值)
摘要 在进行数据分析时,我们经常需要对DataFrame去重,但有时候也会需要只保留重复值. 这里就简单的介绍一下对于DataFrame去重和取重复值的操作. 创建DataFrame 这里首先创建一个包含一行重复值的DataFrame. 2.DataFrame去重,可以选择是否保留重复值,默认是保留重复值,想要不保留重复值的话直接设置参数keep为False即可. 3.取DataFrame重复值.大多时候我们都是需要将数据去重,但是有时候很我们也需要取重复数据,这个时候我们就可以根据刚刚上面我们
-
python DataFrame获取行数、列数、索引及第几行第几列的值方法
1.df=DataFrame([{'A':'11','B':'12'},{'A':'111','B':'121'},{'A':'1111','B':'1211'}]) print df.columns.size#列数 2 print df.iloc[:,0].size#行数 3 print df.ix[[0]].index.values[0]#索引值 0 print df.ix[[0]].values[0][0]#第一行第一列的值 11 print df.ix[[1]].values[0][1]
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
python 给DataFrame增加index行名和columns列名的实现方法
在工作中遇到需要对DataFrame加上列名和行名,不然会报错 开始的数据是这样的 需要的格式是这样的: 其实,需要做的就是添加行名和列名,下面开始操作下. # a是DataFrame格式的数据集 a.index.name = 'date' a.columns.name = 'code' 这样就可以修改过来. 以上这篇python 给DataFrame增加index行名和columns列名的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-

python DataFrame的shift()方法的使用
目录 语法 示例 在python数据分析中,可以使用shift()方法对DataFrame对象的数据进行位置的前滞.后滞移动. 语法 DataFrame.shift(periods=1, freq=None, axis=0) periods可以理解为移动幅度的次数,shift默认一次移动1个单位,也默认移动1次(periods默认为1),则移动的长度为1 * periods. periods可以是正数,也可以是负数.负数表示前滞,正数表示后滞. freq是一个可选参数,默认为None,可以设为一
-
python DataFrame中stack()方法、unstack()方法和pivot()方法浅析
目录 1.stack() 2. unstack() 3. pivot() 总结 1.stack() stack()用于将列索引转换为最内层的行索引,这样叙述比较抽象,看示例就容易理解啦: 准备一组数据,给其设置双索引. import pandas as pd data = [['A类', 'a1', 123, 224, 254], ['A类', 'a2', 234, 135, 444], ['A类', 'a3', 345, 241, 324], ['B类', 'b1', 112, 412, 46
-
关于python DataFrame的合并方法总结
目录 python DataFrame的合并方法 #concat函数 #merge函数 #append函数 把两个dataframe合并成一个 python DataFrame的合并方法 Python的Pandas针对DataFrame,Series提供了多个合并函数,通过参数的调整可以轻松实现DatafFrame的合并. 首先,定义3个DataFrame df1,df2,df3,进行concat.merge.append函数的实验. df1=pd.DataFrame([[1,2,3],[2,3
-
对python dataframe逻辑取值的方法详解
我遇到的一个小需求,就是希望通过判断pandas dataframe中一列的值在两个条件范围(比如下面代码中所描述的逻辑,取小于u-3ε和大于u+3ε的值),然后取出dataframe中的所有符合条件的值,这个需求的解决与普通的iloc.loc.ix的方式不同,所以我想分享一下,希望可以帮到遇到这个困难的朋友们,下面是我的实例代码: doc[~((doc.iloc[:,141:142]<(mean_value-3*std_value))&(doc.iloc[:,141:142]>(me
-
Python Dataframe 指定多列去重、求差集的方法
1)去重 指定多列去重,这是在dataframe没有独一无二的字段作为PK(主键)时,需要指定多个字段一起作为该行的PK,在这种情况下对整体数据进行去重. Attention:主要用到了drop_duplicates方法,并设置参数subset为多个字段名构成的数组. 具体代码如下: >>>import pandas as pd >>>data={'state':[1,1,2,2,1,2,2],'pop':['a','b','c','d','b','c','d']} &
-
python dataframe向下向上填充,fillna和ffill的方法
首先新建一个dataframe: In[8]: df = pd.DataFrame({'name':list('ABCDA'),'house':[1,1,2,3,3],'date':['2010-01-01','2010-06-09','2011-12-03','2011-04-05','2012-03-23']}) In[9]: df Out[9]: date house name 0 2010-01-01 1 A 1 2010-06-09 1 B 2 2011-12-03 2 C 3 201
-
Python DataFrame设置/更改列表字段/元素类型的方法
Python DataFrame 如何设置列表字段/元素类型? 比如笔者想将列表的两个字段由float64设置为int64,那么就要用到DataFrame的astype属性,举例如图: 该例列表为"m_pred_survived"字段为"PassengerId"及"Survived",设置为int64类型,最后可以输出检验下是否正确. m_pred_survived = pd.DataFrame(columns=['PassengerId', '
-
在Python dataframe中出生日期转化为年龄的实现方法
我们在做数据挖掘项目或大数据竞赛时,如果个体是人的时候,获得的数据中可能有出生日期的Series,举个简单例子,比如这样的一些数: # -*- coding: utf-8 -*- import pandas as pd from pandas import Series, DataFrame import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline data = {'bi
-
python dataframe 输出结果整行显示的方法
在使用dataframe时遇到datafram在列太多的情况下总是自动换行显示的情况,导致数据阅读困难,效果如下: # -*- coding: utf-8 -*- import numpy as np import pandas as pd df = pd.DataFrame(np.random.randn(1, 20)) print df 显示效果: 0 1 2 3 4 5 6 \ 0 -1.193428 -0.870381 -0.970323 -1.062275 1.227282 -3.01