SparkSQL快速入门教程
目录
- (一)概述
- (二)SparkSQL实战
- (三)非JSON格式的Dataset创建
- (四)通过JDBC创建DataFrame
- (五)总结
(一)概述
SparkSQL可以理解为在原生的RDD上做的一层封装,通过SparkSQL可以在scala和java中写SQL语句,并将结果作为Dataset/DataFrame返回。简单来讲,SparkSQL可以让我们像写SQL一样去处理内存中的数据。
Dataset是一个数据的分布式集合,是Spark1.6之后新增的接口,它提供了RDD的优点和SparkSQL优化执行引擎的优点,一个Dataset相当于RDD+Schema的结合。
Dataset的底层封装是RDD,当RDD的泛型是Row类型时,该类型就可以称为DataFrame。DataFrame是一种表格型的数据结构,就和传统的Mysql结构一样,通过DataFrame我们可以更加高效地去执行Sql。
特点
- 易整合,在程序中既可以使用SQL,还可以使用API!
- 统一的数据访问, 不同数据源中的数据,都可以使用SQL或DataFrameAPI进行操作,还可以进行不同数据源的Join!
- 对Hive的无缝支持
- 支持标准的JDBC和ODBC
(二)SparkSQL实战
使用SparkSQL首先需要引入相关的依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
该依赖需要和sparkCore保持一致。
SparkSQL的编码主要通过四步:
- 创建SparkSession
- 获取数据
- 执行SQL
- 关闭SparkSession
public class SqlTest {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
Dataset<Row> json = sparkSession.read().json("data/json");
json.printSchema();
json.show();
sparkSession.stop();
}
}
在data的目录下创建一个名为json的文件
{"name":"a","age":23}
{"name":"b","age":24}
{"name":"c","age":25}
{"name":"d","age":26}
{"name":"e","age":27}
{"name":"f","age":28}
运行项目后输出两个结果,schema结果如下:

Dataset<Row>输出结果如下:
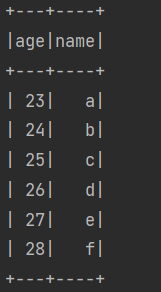
通过SparkSQL可以执行和SQL十分相似的查询操作:
public class SqlTest {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
Dataset<Row> json = sparkSession.read().json("data/json");
json.select("age","name").where("age > 26").show();
sparkSession.stop();
}
}
在上面的语句中,通过一系列的API实现了SQL查询操作,除此之外,SparkSQL还支持直接写原始SQL语句的操作。
在写SQL语句之前,首先需要让Spark知道对哪个表进行查询,因此需要建立一张临时表,再执行SQL查询:
json.createOrReplaceTempView("json");
sparkSession.sql("select * from json where age > 26").show();
(三)非JSON格式的Dataset创建
在上一节中创建Dataset时使用了最简单的json,因为json自己带有schema结构,因此不需要手动去增加,如果是一个txt文件,就需要在创建Dataset时手动塞入schema。
下面展示读取txt文件的例子,首先创建一个user.txt
a 23 b 24 c 25 d 26
现在我要将上面的这几行变成DataFrame,第一列表示姓名,第二列表示年龄,于是就可以像下面这样操作:
public class SqlTest2 {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
SparkContext sparkContext = sparkSession.sparkContext();
JavaSparkContext sc = new JavaSparkContext(sparkContext);
JavaRDD<String> lines = sc.textFile("data/user.txt");
//将String类型转化为Row类型
JavaRDD<Row> rowJavaRDD = lines.map(new Function<String, Row>() {
@Override
public Row call(String v1) throws Exception {
String[] split = v1.split(" ");
return RowFactory.create(
split[0],
Integer.valueOf(split[1])
);
}
});
//定义schema
List<StructField> structFields = Arrays.asList(
DataTypes.createStructField("name", DataTypes.StringType, true),
DataTypes.createStructField("age", DataTypes.IntegerType, true)
);
StructType structType = DataTypes.createStructType(structFields);
//生成dataFrame
Dataset<Row> dataFrame = sparkSession.createDataFrame(rowJavaRDD, structType);
dataFrame.show();
}
}
(四)通过JDBC创建DataFrame
通过JDBC可直接将对应数据库中的表放入Spark中进行一些处理,下面通过MySQL进行展示。
使用MySQL需要在依赖中引入MySQL的引擎:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
接着通过类似JDBC的方式读取MySQL数据:
public class SqlTest3 {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
Map<String,String> options = new HashMap<>();
options.put("url","jdbc:mysql://127.0.0.1:3306/books");
options.put("driver","com.mysql.jdbc.Driver");
options.put("user","root");
options.put("password","123456");
options.put("dbtable","book");
Dataset<Row> jdbc = sparkSession.read().format("jdbc").options(options).load();
jdbc.show();
sparkSession.close();
}
}
读取到的数据是DataFrame,接下来的操作就是对DataFrame的操作了。
(五)总结
SparkSQL是对Spark原生RDD的增强,虽然很多功能通过RDD就可以实现,但是SparkSQL可以更加灵活地实现一些功能。
到此这篇关于SparkSQL快速入门教程的文章就介绍到这了,更多相关SparkSQL入门内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SparkSQL使用IDEA快速入门DataFrame与DataSet的完美教程
目录 1.使用IDEA开发Spark SQL 1.1创建DataFrame/DataSet 1.1.1指定列名添加Schema 1.1.2StructType指定Schema 1.1.3反射推断Schema 1.使用IDEA开发Spark SQL 1.1创建DataFrame/DataSet 1.指定列名添加Schema 2.通过StrucType指定Schema 3.编写样例类,利用反射机制推断Schema 1.1.1指定列名添加Schema //导包 import org.apache.sp
-

SparkSQL使用快速入门
目录 一.SparkSQL的进化之路 二.认识SparkSQL 2.1 什么是SparkSQL? 2.2 SparkSQL的作用 2.3 运行原理 2.4 特点 2.5 SparkSession 2.6 DataFrames 三.RDD转换成为DataFrame 3.1通过case class创建DataFrames(反射) 3.2通过structType创建DataFrames(编程接口) 3.3通过 json 文件创建DataFrames 四.DataFrame的read和save和save
-
SparkSQL快速入门教程
目录 (一)概述 (二)SparkSQL实战 (三)非JSON格式的Dataset创建 (四)通过JDBC创建DataFrame (五)总结 (一)概述 SparkSQL可以理解为在原生的RDD上做的一层封装,通过SparkSQL可以在scala和java中写SQL语句,并将结果作为Dataset/DataFrame返回.简单来讲,SparkSQL可以让我们像写SQL一样去处理内存中的数据. Dataset是一个数据的分布式集合,是Spark1.6之后新增的接口,它提供了RDD的优点和Spark
-
jQuery Easyui快速入门教程
1.什么是JQuery EasyUI jQuery EasyUI是一组基于JQuery的UI插件集合,而JQueryEasyUI的目标就是帮助开发者更轻松的打造出功能丰富并且美观的UI界面.开发者不需要编写复杂的JavaScript,也不需要对css样式有深入的了解,开发者需要了解的只是一些简单的html标签. 2.学习jQuery EasyUI的条件 因为JQueryEasyUI是基于jQuery的UI库,所以,必须需要JQuery课程的基础. 3.JQuery EasyUI的特点 基于JQu
-
OpenStack云计算快速入门教程(1)之OpenStack及其构成简介
该教程基于Ubuntu12.04版,它将帮助读者建立起一份OpenStack最小化安装.我是五岳之巅,翻译中多采用意译法,所以个别词与原版有出入,请大家谅解.我不是英语专业,我觉着搞技术最重要的就是理解,而不是四级和考研中那烦人的英译汉,所以我的目标是忠于原意.通俗表达,Over.英文原文在这里(http://docs.openstack.org/es@***/openstack-compute/starter/content/ ,请将ex@***中的@去掉,CU屏蔽的F词),下面步入正题: 第
-
ReactJs快速入门教程(精华版)
现在最热门的前端框架有AngularJS.React.Bootstrap等.自从接触了ReactJS,ReactJs的虚拟DOM(Virtual DOM)和组件化的开发深深的吸引了我,下面来跟我一起领略ReactJs的风采吧~~ 文章有点长,耐心读完,你会有很大收获哦~ 一.ReactJS简介 React 起源于 Facebook 的内部项目,因为该公司对市场上所有 JavaScript MVC 框架,都不满意,就决定自己写一套,用来架设 Instagram 的网站.做出来以后,发现这套东西
-
Yii2框架制作RESTful风格的API快速入门教程
先给大家说下什么是REST restful REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次出现在2000年Roy Fielding的博士论文中,Roy Fielding是HTTP规范的主要编写者之一. 他在论文中提到:"我这篇文章的写作目的,就是想在符合架构原理的前提下,理解和评估以网络为基础的应用软件的架构设计,得到一个功能强.性能好.适宜通信的架构.REST指的是一组架构约束条件和原则." 如
-
Vue.js快速入门教程
像AngularJS这种前端框架可以让我们非常方便地开发出强大的单页应用,然而有时候Angular这种大型框架对于我们的项目来说过于庞大,很多功能不一定会用到.这时候我们就需要评估一下使用它的必要性了.如果我们仅仅需要在一个简单的网页里添加屈指可数的几个功能,那么用Angular就太麻烦了,必要的安装.配置.编写路由和设计控制器等等工作显得过于繁琐. 这时候我们需要一个更加轻量级的解决方案.Vue.js就是一个不错的选择.Vue.js是一个专注于视图模型(ViewModal)的框架.视图模型是U
-
Vue.js 60分钟快速入门教程
vuejs是当下很火的一个JavaScript MVVM库,它是以数据驱动和组件化的思想构建的.相比于Angular.js,Vue.js提供了更加简洁.更易于理解的API,使得我们能够快速地上手并使用Vue.js. 如果你之前已经习惯了用jQuery操作DOM,学习Vue.js时请先抛开手动操作DOM的思维,因为Vue.js是数据驱动的,你无需手动操作DOM.它通过一些特殊的HTML语法,将DOM和数据绑定起来.一旦你创建了绑定,DOM将和数据保持同步,每当变更了数据,DOM也会相应地更新. 当
-
Java的JNI快速入门教程(推荐)
1. JNI简介 JNI是Java Native Interface的英文缩写,意为Java本地接口. 问题来源:由于Java编写底层的应用较难实现,在一些实时性要求非常高的部分Java较难胜任(实时性要求高的地方目前还未涉及,实时性这类话题有待考究). 解决办法:Java使用JNI可以调用现有的本地库(C/C++开发任何和系统相关的程序和类库),极大地灵活Java的开发. 2. JNI快速学习教程 2.1 问题: 使用JNI写一段代码,实现string_Java_Test_helloworld
-
Jupyter notebook快速入门教程(推荐)
本文主要介绍了Jupyter notebook快速入门教程,分享给大家,具体如下: 本篇将给大家介绍一款超级好用的工具:Jupyter notebook. 为什么要介绍这款工具呢? 如果你想使用Python学习数据分析或数据挖掘,那么它应该是你第一个应该知道并会使用的工具,它很容易上手,用起来非常方便,是个对新手非常友好的工具.而事实也证明它的确很好用,在数据挖掘平台 Kaggle 上,使用 Python 的数据爱好者绝大多数使用 jupyter notebook 来实现分析和建模的过程,因此,
-
Navicat使用快速入门教程
学习数据库的时候,经常接触到 navicat 这个管理数据库的工具.下面介绍这个数据库管理工具的使用. 一. 连接使用 1.1 连接数据库 打开 navicat ,点击 连接 ,选择 数据库 弹出以下界面 (以MySQL为例),熟悉各部分的作用 测试是否可以连接,有以下提示,点击确定开始使用数据库 双击 或 右键 打开连接,图标变亮表示已经打开连接 1.2 操作数据库 右键 连接 ,点击 新建数据库 输入 数据库名 和 编码规则 双击 或 右键 打开数据库(灰色图标变亮表示打开) 二. 导入备份