python opencv通过4坐标剪裁图片
本文主要介绍了python opencv通过4坐标剪裁图片,分享给大家,具体如下:
效果展示,

裁剪出的单词图像(如下)


这里程序我是用在paddleOCR里面,通过识别模型将识别出的图根据程序提供的坐标(即四个顶点的值)进行抠图的程序(上面的our和and就是扣的图),并进行了封装,相同格式的在这个基础上改就是了
[[[368.0, 380.0], [437.0, 380.0], [437.0, 395.0], [368.0, 395.0]], [[496.0, 376.0], [539.0, 378.0], [538.0, 397.0], [495.0, 395.0]], [[466.0, 379.0], [498.0, 379.0], [498.0, 395.0], [466.0, 395.0]], [[438.0, 379
.0], [466.0, 379.0], [466.0, 395.0], [438.0, 395.0]], ]
从程序得到的数据格式大概长上面的样子,由多个四个坐标一组的数据(如下)组成,即下面的[368.0, 380.0]为要裁剪图片左上角坐标,[437.0, 380.0]为要裁剪图片右上角坐标,[437.0, 395.0]为要裁剪图片右下角坐标,[368.0, 395.0]为要裁剪图片左下角坐标.
[[368.0, 380.0], [437.0, 380.0], [437.0, 395.0], [368.0, 395.0]]
而这里剪裁图片使用的是opencv(由于参数的原因没有设置角度的话就只能裁剪出平行的矩形,如果需要裁减出不与矩形图片编译平行的图片的话,参考这个博客进行进一步的改进点击进入)
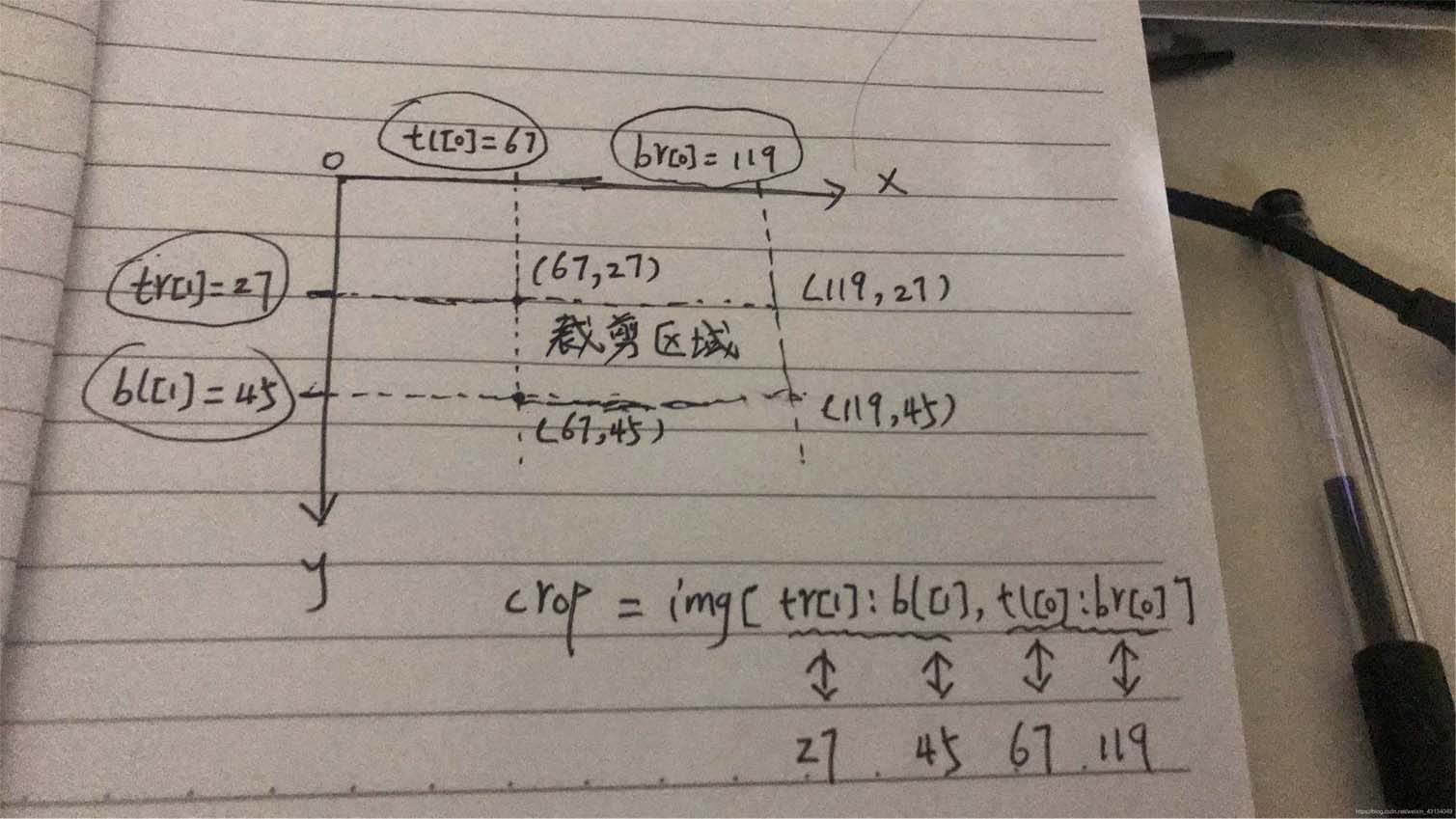
裁剪部分主要是根据下面这一行代码进行的,这里要记住(我被这里坑了一下午),
参数 tr[1]:左上角或右上角的纵坐标值
参数bl[1]:左下角或右下角的纵坐标值
参数tl[0]:左上角或左下角的横坐标值
参数br[0]:右上角或右下角的横坐标值
crop = img[int(tr[1]):int(bl[1]), int(tl[0]):int(br[0]) ]
总的程序代码如下
import numpy as np
import cv2
def np_list_int(tb):
tb_2 = tb.tolist() #将np转换为列表
return tb_2
def shot(img, dt_boxes):#应用于predict_det.py中,通过dt_boxes中获得的四个坐标点,裁剪出图像
dt_boxes = np_list_int(dt_boxes)
boxes_len = len(dt_boxes)
num = 0
while 1:
if (num < boxes_len):
box = dt_boxes[num]
tl = box[0]
tr = box[1]
br = box[2]
bl = box[3]
print("打印转换成功数据num =" + str(num))
print("tl:" + str(tl), "tr:" + str(tr), "br:" + str(br), "bl:" + str(bl))
print(tr[1],bl[1], tl[0],br[0])
crop = img[int(tr[1]):int(bl[1]), int(tl[0]):int(br[0]) ]
# crop = img[27:45, 67:119] #测试
# crop = img[380:395, 368:119]
cv2.imwrite("K:/paddleOCR/PaddleOCR/screenshot/a/" + str(num) + ".jpg", crop)
num = num + 1
else:
break
def shot1(img_path,tl, tr, br, bl,i):
tl = np_list_int(tl)
tr = np_list_int(tr)
br = np_list_int(br)
bl = np_list_int(bl)
print("打印转换成功数据")
print("tl:"+str(tl),"tr:" + str(tr), "br:" + str(br), "bl:"+ str(bl))
img = cv2.imread(img_path)
crop = img[tr[1]:bl[1], tl[0]:br[0]]
# crop = img[27:45, 67:119]
cv2.imwrite("K:/paddleOCR/PaddleOCR/screenshot/shot/" + str(i) + ".jpg", crop)
# tl1 = np.array([67,27])
# tl2= np.array([119,27])
# tl3 = np.array([119,45])
# tl4 = np.array([67,45])
# shot("K:\paddleOCR\PaddleOCR\screenshot\zong.jpg",tl1, tl2 ,tl3 , tl4 , 0)
特别注意对np类型转换成列表,以及crop = img[tr[1]:bl[1], tl[0]:br[0]]的中参数的位置,
实例
用了两种方法保存图片,opencv和Image,实践证明opencv非常快
from PIL import Image
import os
import cv2
import time
import matplotlib.pyplot as plt
def label2picture(cropImg,framenum,tracker):
pathnew ="E:\\img2\\"
# cv2.imshow("image", cropImg)
# cv2.waitKey(1)
if (os.path.exists(pathnew + tracker)):
cv2.imwrite(pathnew + tracker+'\\'+framenum + '.jpg', cropImg,[int(cv2.IMWRITE_JPEG_QUALITY), 100])
else:
os.makedirs(pathnew + tracker)
cv2.imwrite(pathnew + tracker+'\\'+framenum + '.jpg', cropImg,[int(cv2.IMWRITE_JPEG_QUALITY), 100])
f = open("E:\\hypotheses.txt","r")
lines = f.readlines()
for line in lines:
li = line.split(',')
print(li[0],li[1],li[2],li[3],li[4],li[5])
filename = li[0]+'.jpg'
img = cv2.imread("E:\\DeeCamp\\img1\\" + filename)
crop_img = img[int(li[3][:-3]):(int(li[3][:-3]) + int(li[5][:-3])),
int(li[2][:-3]):(int(li[2][:-3]) + int(li[4][:-3]))]
# print(int(li[2][:-3]),int(li[3][:-3]),int(li[4][:-3]),int(li[5][:-3]))
label2picture(crop_img, li[0], li[1])
# #
# x,y,w,h = 87,158,109,222
# img = cv2.imread("E:\\DeeCamp\\img1\\1606.jpg")
# # print(img.shape)
# crop = img[y:(h+y),x:(w+x)]
# cv2.imshow("image", crop)
# cv2.waitKey(0)
# img = Image.open("E:\\DeeCamp\\img1\\3217.jpg")
#
# cropImg = img.crop((x,y,x+w,y+h))
# cropImg.show()
# img = Image.open("E:\\deep_sort-master\\MOT16\\train\\try1\\img1\\"+filename)
# print(int(li[2][:-3]),(int(li[2][:-3])+int(li[4][:-3])), int(li[3][:-3]),(int(li[3][:-3])+int(li[5][:-3])))
# #裁切图片
# # cropImg = img.crop(region)
# # cropImg.show()
# framenum ,tracker= li[0],li[1]
# pathnew = 'E:\\DeeCamp\\deecamp项目\\deep_sort-master\\crop_picture\\'
# if (os.path.exists(pathnew + tracker)):
# # 保存裁切后的图片
# plt.imshow(cropImg)
# plt.savefig(pathnew + tracker+'\\'+framenum + '.jpg')
# else:
# os.makedirs(pathnew + tracker)
# plt.imshow(cropImg)
# plt.savefig(pathnew + tracker+'\\'+framenum + '.jpg')
到此这篇关于python opencv通过4坐标剪裁图片的文章就介绍到这了,更多相关opencv 剪裁图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

OpenCV Java实现人脸识别和裁剪功能
本文实例为大家分享了OpenCV Java实现人脸识别和裁剪的具体代码,供大家参考,具体内容如下 安装及配置 1.首先安装OpenCV,地址 这里我下载的是Windows版的3.4.5 然后安装即可-- 2.Eclipse配置OpenCV Window->Preferences->Java->User Libraries New输入你的Libraries名 这里我的安装目录是D:\OpenCV,所以是: 然后引入dll,我是64位机子,所以是: Ok,下面创建Java项目做Java与Op
-
python通过opencv实现批量剪切图片
上一篇文章中,我们介绍了python实现图片处理和特征提取详解,这里我们再来看看Python通过OpenCV实现批量剪切图片,具体如下. 做图像处理需要大批量的修改图片尺寸来做训练样本,为此本程序借助opencv来实现大批量的剪切图片. import cv2 import os def cutimage(dir,suffix): for root,dirs,files in os.walk(dir): for file in files: filepath = os.path.join(root
-
OpenCV使用鼠标响应裁剪图像
给定一幅图像,将其中的某一部分兴趣区域裁剪出来,这在PS中很好实现,但是使用openCV如何实现呢?因此本文主要介绍openCV使用鼠标响应来裁剪图像: 一.代码部分: #include "stdafx.h" #include "cv.h" #include <highgui.h> #include <stdio.h> IplImage* org = 0; IplImage* img = 0; IplImage* tmp = 0; IplIm
-
python通过opencv实现图片裁剪原理解析
这篇文章主要介绍了python通过opencv实现图片裁剪原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 图像裁剪的基本概念 : 图像裁剪是指将图像中我们想要的研究区以外的区域去除,经常是按照行政区划或研究区域的边界对图像进行裁剪.例如,一张500×400的图像,我们只想要中间的250×200的区域,就可以使用图像裁剪将四周的区域去除. 在实际开发工作中,我们经常需要对图像进行分幅裁剪,按照ERDAS实际图像分幅裁剪的过程,可以将图像分
-
详解Python+opencv裁剪/截取图片的几种方式
前言 在计算机视觉任务中,如图像分类,图像数据集必不可少.自己采集的图片往往存在很多噪声或无用信息会影响模型训练.因此,需要对图片进行裁剪处理,以防止图片边缘无用信息对模型造成影响.本文介绍几种图片裁剪的方式,供大家参考. 一.手动单张裁剪/截取 selectROI:选择感兴趣区域,边界框框选x,y,w,h selectROI(windowName, img, showCrosshair=None, fromCenter=None): . 参数windowName:选择的区域被显示在的窗口的名字
-
Python实现图片裁剪的两种方式(Pillow和OpenCV)
在这篇文章里我们聊一下Python实现图片裁剪的两种方式,一种利用了Pillow,还有一种利用了OpenCV.两种方式都需要简单的几行代码,这可能也就是现在Python那么流行的原因吧. 首先,我们有一张原始图片,如下图所示: 原始图片 然后,我们利用OpenCV对其进行裁剪,代码如下所示: import cv2 img = cv2.imread("./data/cut/thor.jpg") print(img.shape) cropped = img[0:128, 0:512] #
-
python opencv对图像进行旋转且不裁剪图片的实现方法
最近在做深度学习时需要用到图像处理相关的操作,在度娘上找到的图片旋转方法千篇一律,旋转完成的图片都不是原始大小,很苦恼,于是google到歪果仁的网站扒拉了一个方法,亲测好用,再次嫌弃天下文章一大抄的现象,虽然我也是抄歪果仁的. 废话不多说了,直接贴代码了. def rotate_bound(image, angle): # grab the dimensions of the image and then determine the # center (h, w) = image.shape[
-
OpenCV Python实现图像指定区域裁剪
在工作中.在做数据集时,需要对图片进行处理,照相的图片我们只需要特定的部分,所以就想到裁剪一种所需的部分.当然若是图片有规律可循则使用opencv对其进行膨胀腐蚀等操作.这样更精准一些. 一.指定图像位置的裁剪处理 import os import cv2 # 遍历指定目录,显示目录下的所有文件名 def CropImage4File(filepath,destpath): pathDir = os.listdir(filepath) # 列出文件路径中的所有路径或文件 for allDir i
-
实现opencv图像裁剪分屏显示示例
使用OPENCV图像处理库,将图片裁剪分屏显示 复制代码 代码如下: //#include "stdafx.h"#include <opencv2/opencv.hpp> //#include <opencv2/imgproc/imgproc.hpp>//#include <opencv2/highgui/highgui.hpp>#include <iostream>#include <vector>using namespa
-
python opencv通过4坐标剪裁图片
本文主要介绍了python opencv通过4坐标剪裁图片,分享给大家,具体如下: 效果展示, 裁剪出的单词图像(如下) 这里程序我是用在paddleOCR里面,通过识别模型将识别出的图根据程序提供的坐标(即四个顶点的值)进行抠图的程序(上面的our和and就是扣的图),并进行了封装,相同格式的在这个基础上改就是了 [[[368.0, 380.0], [437.0, 380.0], [437.0, 395.0], [368.0, 395.0]], [[496.0, 376.0], [539.0,
-
python openCV实现摄像头获取人脸图片
本文实例为大家分享了python openCV实现摄像头获取人脸图片的具体代码,供大家参考,具体内容如下 在机器学习中,训练模型需要大量图片,通过openCV中的库可以快捷的调用摄像头,截取图片,可以快速的获取大量人脸图片 需要注意将CascadeClassifier方法中的地址改为自己包cv2包下面的文件 import cv2 def load_img(path,name,mun = 100,add_with = 0): # 获取人脸识别模型 # # #以下路径需要更改为自己环境下xml文件
-
Python + opencv对拍照得到的图片进行背景去除的实现方法
有时候我们没办法得到pdf或者word文档,这个时候会使用手机或者相机进行拍照,往往会出现背景,打印出来就是灰色的或者有黑色的背景,这个时候影响视野观看,通过代码实现对背景去除,还原清晰图像.代码如下: #!/usr/bin/python3.6 # -*- coding: utf-8 -*- # @Time : 2020/11/17 19:06 # @Author : ptg # @Email : zhxwhchina@163.com # @File : 去背景.py # @Software:
-
python opencv实现切变换 不裁减图片
本文实例为大家分享了python opencv实现切变换的具体代码,供大家参考,具体内容如下 # -*- coding:gb2312 -*- import cv2 from math import * import numpy as np img = cv2.imread("3-2.jpg") height,width=img.shape[:2] degreeAffine=45 #切变换最后结果 heightAffine=height widthAffine=int(2*height*
-
Python+Opencv识别两张相似图片
在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 看到一篇博客是介绍这个,但他用的是PIL中的Image实现的,感觉比较麻烦,于是利用Opencv库进行了更简洁化的实现. 相关背景 要识别两张相似图像,我们从感性上来谈是怎么样的一个过程?首先我们会区分这两张相片的类型,例如是风景照,还是人物照.风景照中
-
Python实现将照片变成卡通图片的方法【基于opencv】
本文实例讲述了Python实现将照片变成卡通图片的方法.分享给大家供大家参考,具体如下: 之前的文章介绍了使用Photoshop将照片变成卡通图片,今次介绍用代码来实现这项任务,可以就此探查各种滤镜的内部机制. 制作环境:Windows10,Python2.7,Anaconda 任务描述:将D盘某文件夹中的所有图片使用代码进行卡通化,然后保存到另一文件夹中. 如前文所述,卡通化的关键是强化边缘与减少色彩,所以使用Photoshop进行卡通化的时候就使用了照亮边缘和干笔画的滤镜来处理.使用代码处理
-
Python基于opencv调用摄像头获取个人图片的实现方法
接触图像领域的应该对于opencv都不会感到陌生,这个应该算是功能十分强劲的一个算法库了,当然了,使用起来也是很方便的,之前使用Windows7的时候出现多该库难以安装成功的情况,现在这个问题就不存在了,需要安装包的话可以去我的资源中下载使用,使用pip安装方式十分地便捷. 今天主要是基于opencv模块来调用笔记本的内置摄像头,然后从视频流中获取到人脸的图像数据用于之后的人脸识别项目,也就是为了构建可用的数据集.整个实现过程并不复杂,具体如下: #!usr/bin/env python #en
-
python+opencv识别图片中的圆形
本文实例为大家分享了python+opencv识别图片中足球的方法,供大家参考,具体内容如下 先补充下霍夫圆变换的几个参数知识: dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器.上述文字不好理解的话,来看例子吧.例如,如果dp= 1时,累加器和输入图像具有相同的分辨率.如果dp=2,累加器便有输入图像一半那么大的宽度和高度. minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离.这
-
python+opencv实现动态物体识别
注意:这种方法十分受光线变化影响 自己在家拿着手机瞎晃的成果图: 源代码: # -*- coding: utf-8 -*- """ Created on Wed Sep 27 15:47:54 2017 @author: tina """ import cv2 import numpy as np camera = cv2.VideoCapture(0) # 参数0表示第一个摄像头 # 判断视频是否打开 if (camera.isOpened()
-
python图片剪裁代码(图片按四个点坐标剪裁)
用了两种方法保存图片,opencv和Image,实践证明opencv非常快 from PIL import Image import os import cv2 import time import matplotlib.pyplot as plt def label2picture(cropImg,framenum,tracker): pathnew ="E:\\img2\\" # cv2.imshow("image", cropImg) # cv2.waitKe