详解ArrayList的扩容机制
目录
- 一、ArrayList 了解过吗?它是啥?有啥用?
- 二、ArrayList 如何指定底层数组大小的
- 三、数组的大小一旦被规定就无法改变
- 四、ArrayList 具体是怎么添加数据的
- 五、ArrayList 又是如何删除数据的呢
- 六、ArrayList 是线程安全的吗?不安全的表现
- 七、为什么线程不安全还要用它呢
一、ArrayList 了解过吗?它是啥?有啥用?
众所周知,Java 集合框架拥有两大接口 Collection 和 Map,其中,Collection 麾下三生子 List、Set 和 Queue。ArrayList 就实现了 List 接口,其实就是一个数组列表,不过作为 Java 的集合框架,它只能存储对象引用类型,也就是说当我们需要装载的数据是诸如 int、float 等基本数据类型的时候,必须把它们转换成对应的包装类。
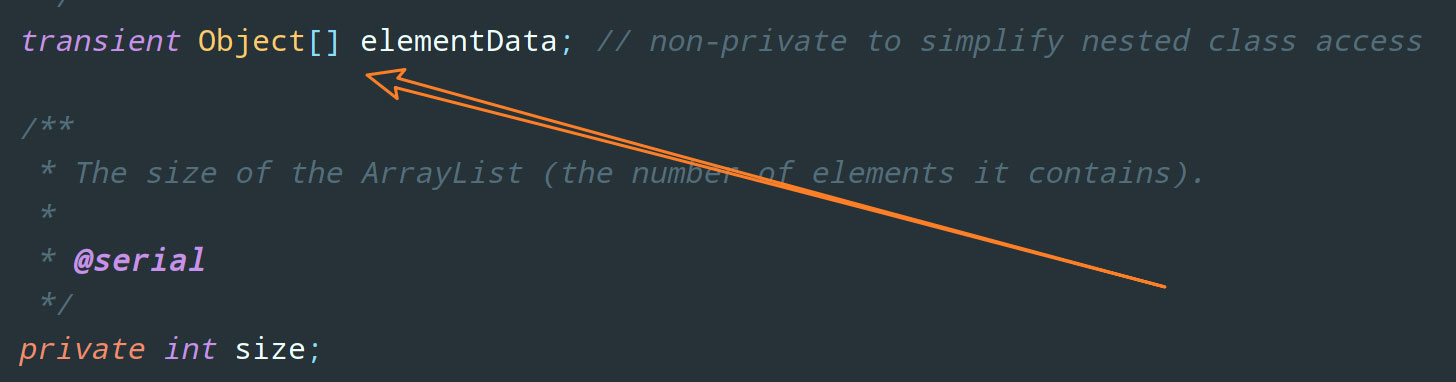
ArrayList 的底层实现是一个 Object 数组:
既然它是基于数组实现的,数组在内存空间中是连续分配的,那必然查询速率非常快,不过当然也肯定逃不过增删效率低的缺陷。
另外,和 ArrayList 一样同样实现了 List 接口的、我们比较常用的还有 LinkedList。LinkedList 比较特殊,它不仅实现了 List 接口,还实现了 Queue 接口,所以你可以看见 LinkedList 经常被当作队列使用:
Queue<Integer> queue = new LinkedList<>();
LinkedList 人如其名,它的底层自然是基于链表的,而且还是个双向链表。链表的特性和数组正好是反的,由于没有索引,所以查询效率低,但是增删速度快。
二、ArrayList 如何指定底层数组大小的
OK,首先,既然咱真正存储数据的地方是数组,那我们初始化 ArrayList 的时候自然要给数组分配一个大小,开辟一个内存空间。我们先来看看 ArrayList 的无参构造函数:
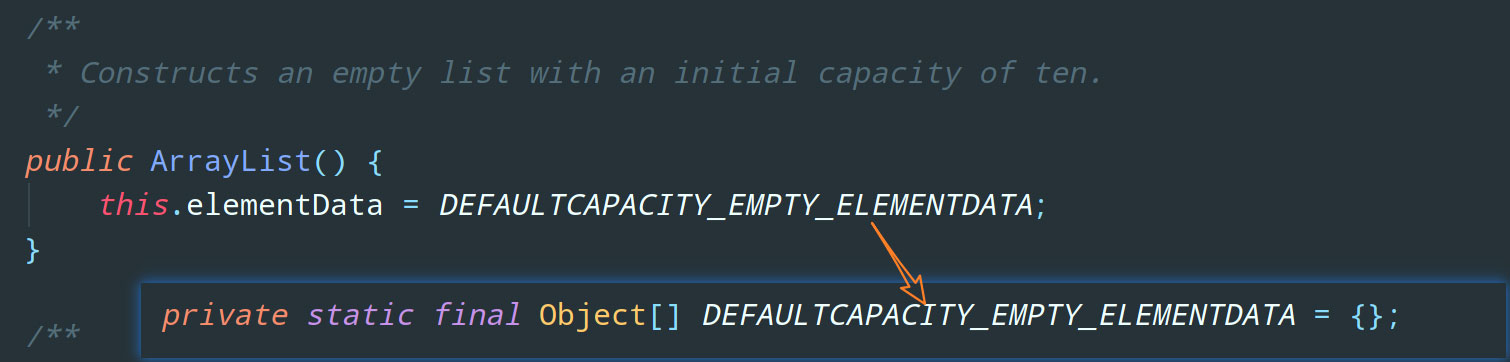
可以看到,它为底层的 Object 数组也就是 elementData 赋值了一个默认的空数组 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。也就是说,使用无参构造函数初始化 ArrayList 后,它当时的数组容量为 0 。
这给咱初始化一个容量为 0 的数组有啥用?啥也存不了啊?别急,如果使用了无参构造函数来初始化 ArrayList, 只有当我们真正对数据进行添加操作 add 时,才会给数组分配一个默认的初始容量 DEFAULT_CAPACITY = 10。看下图:
说完了无参构造,ArrayList 的有参构造函数就是中规中矩了,按照用户传入的大小开辟数组空间:
三、数组的大小一旦被规定就无法改变
ArrayList 是怎么对底层数组进行扩容的?
ArrayList 的底层实现是 Object 数组,我们知道,数组的大小一旦被规定就无法改变。那如果我们不断的往里面添加数据的话,ArrayList 是如何进行扩容的呢?或者说 ArrayList 是如何实现存放任意数量对象的呢?
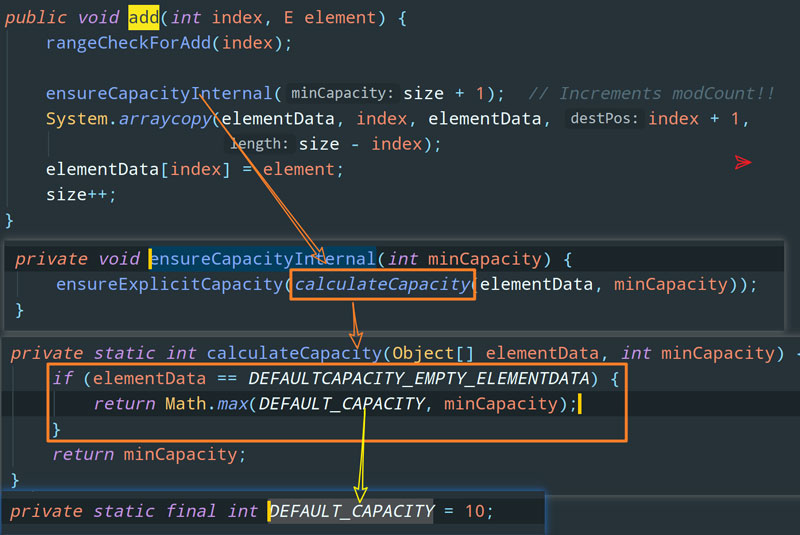
OK,扩容发生在啥时候?那肯定是我们往数组中新加入一个元素但是发现数组满了的时候。没错,我们去 add 方法中看看 ArrayList 是怎么做扩容的:

ensureExplicitCapacity 判断是否需要进行扩容,很显然,grow 方法是扩容的关键:

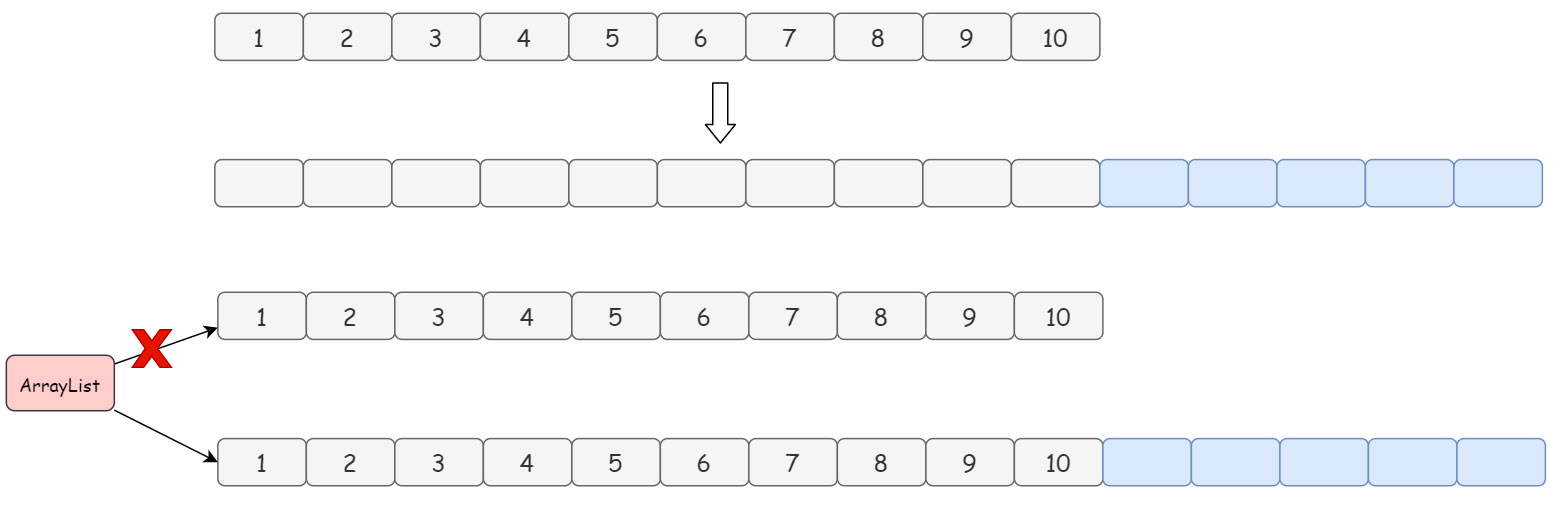
说实话,别的都不用看了,看上面图中的黄色框框就知道 ArrayList 是怎么扩容的了:扩容后的数组长度 = 当前数组长度 + 当前数组长度 / 2。最后使用 Arrays.copyOf 方法直接把原数组中的数组 copy 过来,需要注意的是,Arrays.copyOf 方法会创建一个新数组然后再进行拷贝。
举个例子画个图来演示一下:
四、ArrayList 具体是怎么添加数据的
OK,add 方法我们刚刚讲了一半,添加数据前会先判断一下是否需要扩容,真正的添加数据的操作在下半部分:
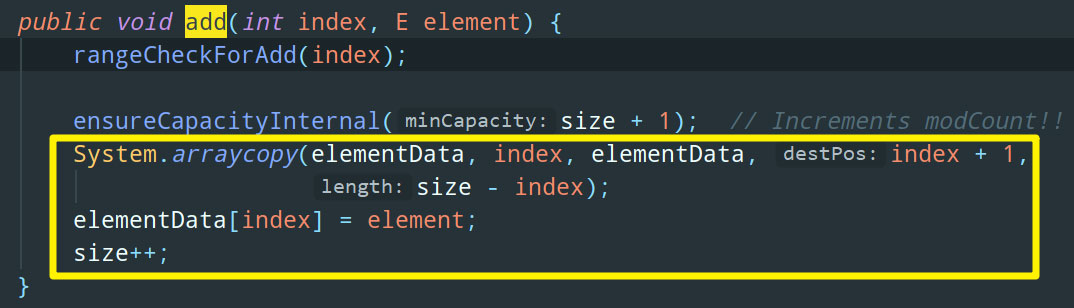
先讲下 add(int index, E element) 这个方法的含义,就是在指定索引 index 处插入元素 element。比如说 ArrayList.add(0, 3),意思就是在头部插入元素 3。
再来看看 add 方法的核心 System.arraycopy,这个方法有 5 个参数:
- elementData:源数组
- index:从源数组中的哪个位置开始复制
- elementData:目标数组
- index + 1:复制到目标数组中的哪个位置
- size - index:要复制的源数组中数组元素的数量
解释一下上面代码中 arraycopy 的意思,举个例子,我们想要在 index = 5 的位置插入元素,首先,我们会复制一遍源数组 elementData(这里我们称复制的数组为新数组吧),然后把源数组中从 index = 5 的位置开始到数组末尾的元素,放到新数组的 index + 1 = 6 的位置上:
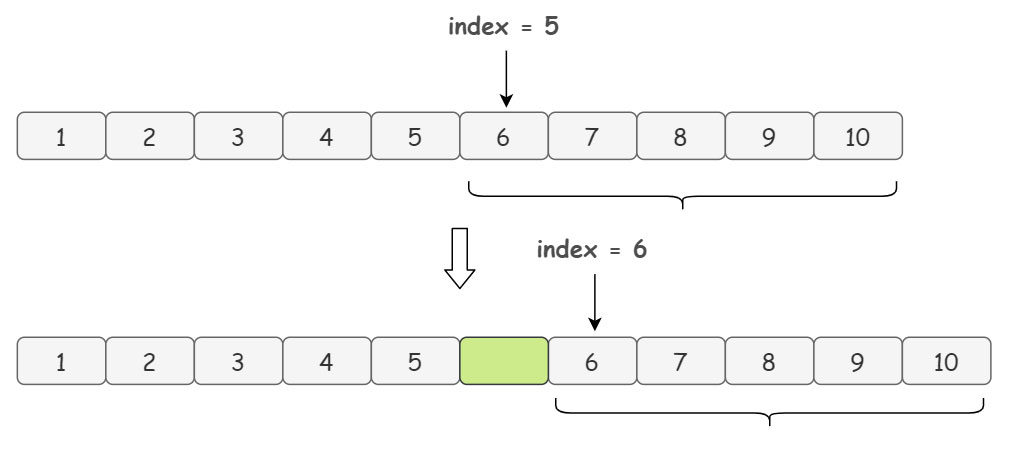
于是,这就给我们要新增的元素腾出了位置,然后在新数组 index = 5 的位置放入元素 element 就完成了添加的操作:
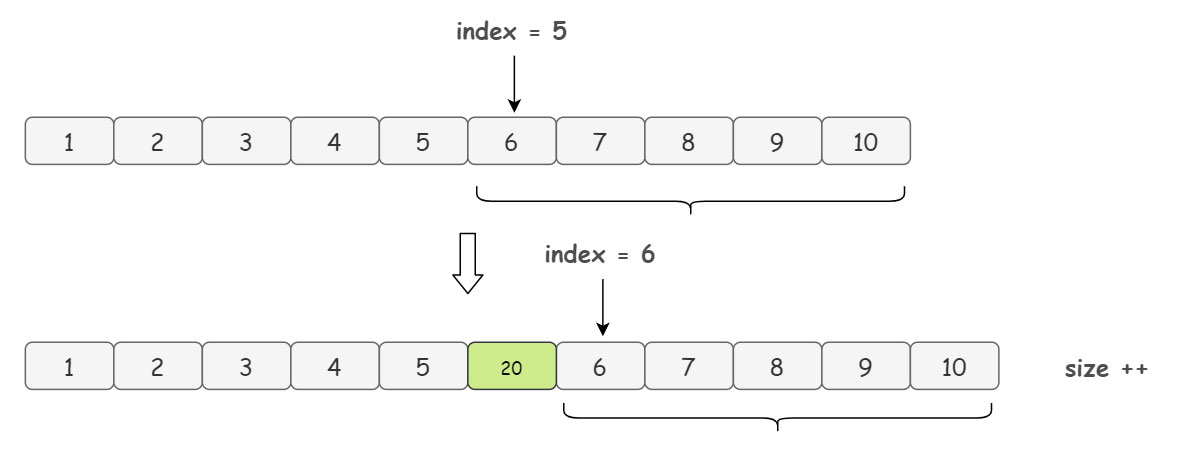
显然,不用多说,ArrayList 的将数据插入到指定位置的操作性能非常低下,因为要开辟新数组复制元素啊,要是涉及到扩容那就更慢了。
另外,ArrayList 还内置了一个直接在末尾添加元素的 add 方法,不用复制数组,直接 size ++ 就好,这个方法应该是我们最常使用的:

五、ArrayList 又是如何删除数据的呢
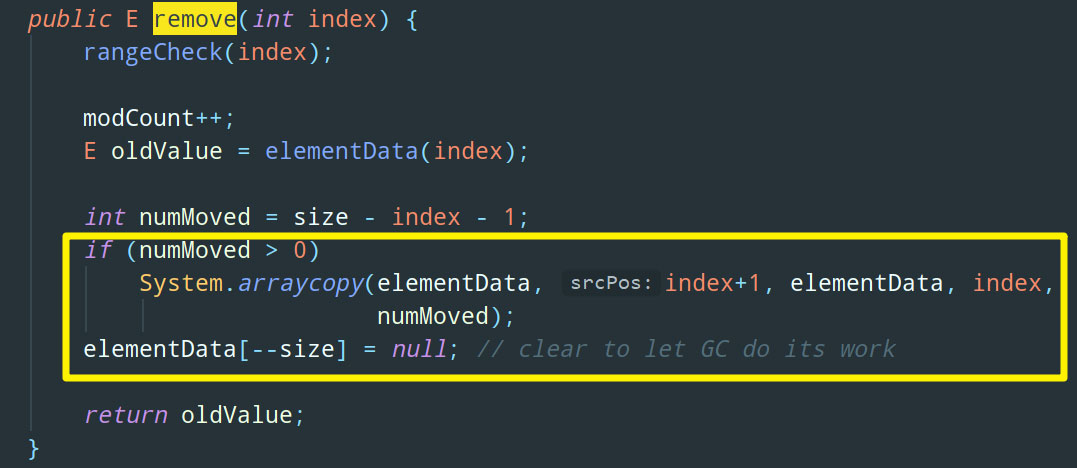
Ctrl + F 找到 remove 方法,就这?和添加一个道理,也是复制数组
举个例子,假设我们要删除数组的 index = 5 的元素,首先,我们会复制一遍源数组,然后把源数组中从 index + 1 = 6 的位置开始到数组末尾的元素,放到新数组的 index = 5 的位置上:
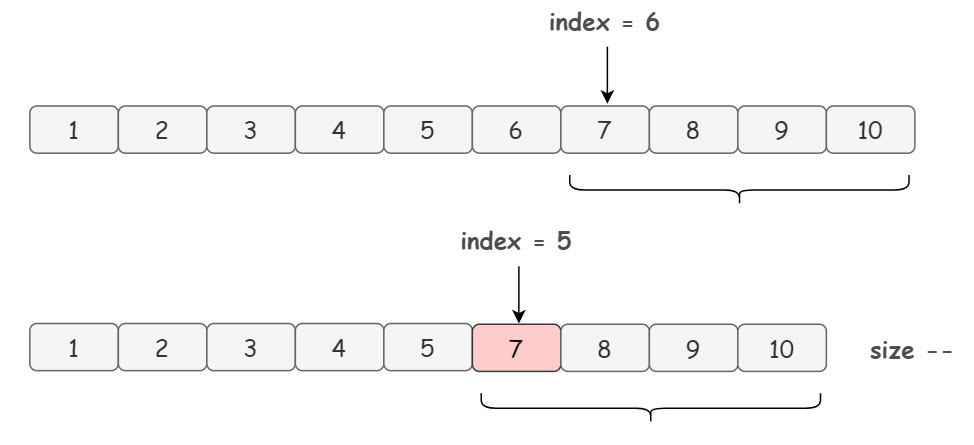
也就是说 index = 5 的元素直接被覆盖掉了,给了你被删除的感觉。同样的,它的效率自然也是十分低下的
六、ArrayList 是线程安全的吗?不安全的表现
ArrayList 和 LinkedList 都不是线程安全的,我们以在末尾添加元素的 add 方法为例,来看看 ArrayList 线程不安全的表现是啥:

黄色框里的并不是一个原子操作,它由两步操作构成:
elementData[size] = e; size = size + 1;
在单线程执行这两条代码时,那当然没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程添加的值覆盖另一个线程添加的值。举个例子:
- 假设 size = 0,我们要往这个数组的末尾添加元素
- 线程 A 开始添加一个元素,值为 A。此时它执行第一条操作,将 A 放在了数组 elementData 下标为 0 的位置上
- 接着线程 B 刚好也要开始添加一个值为 B 的元素,且走到了第一步操作。此时线程 B 获取到的 size 值依然为 0,于是它将 B 也放在了 elementData 下标为 0 的位置上
- 线程 A 开始增加 size 的值,size = 1
- 线程 B 开始增加 size 的值,size = 2
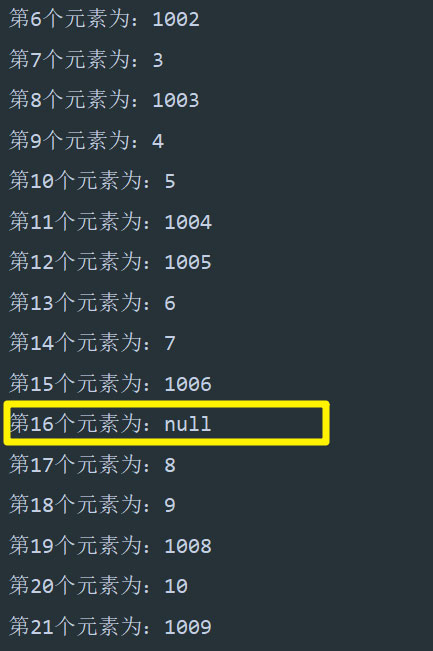
这样,线程 A、B 都执行完毕后,理想的情况应该是 size = 2,elementData[0] = A,elementData[1] = B。而实际情况变成了 size = 2,elementData[0] = B(线程 B 覆盖了线程 A 的操作),下标 1 的位置上什么都没有。并且后续除非我们使用 set 方法修改下标为 1 的值,否则这个位置上将一直为 null,因为在末尾添加元素时将会从 size = 2 的位置上开始。
上段代码验证下:
结果和我们分析的一样:
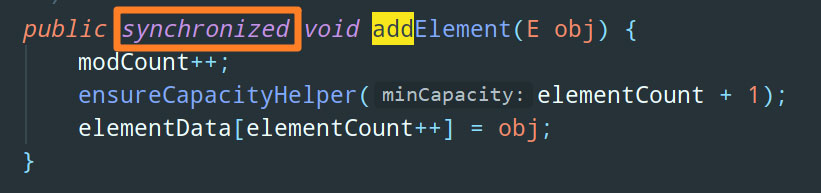
ArrayList 的线程安全版本是 Vector,它的实现很简单,就是把所有的方法统统加上 synchronized :
既然它需要额外的开销来维持同步锁,所以理论上来说它要比 ArrayList 要慢。
七、为什么线程不安全还要用它呢
因为在大多数场景中,查询的情况居多,不会涉及太频繁的增删。那如果真的涉及频繁的增删,可以使用LinkedList,底层链表实现,为增删而生。而如果你非得保证线程安全那就使用 Vector。当然实际开发中使用最多的还是 ArrayList,虽然线程不安全、增删效率低,但是查询效率高啊。
以上就是详解ArrayList的扩容机制的详细内容,更多关于ArrayList 扩容机制的资料请关注我们其它相关文章!
相关推荐
-

Java基础之ArrayList的扩容机制
我们知道Java中的ArrayList对象底层是基于数组实现的,而数组是有长度限制的,那基于数组实现的ArrayList是否有长度限制呢?我们通过ArrayList的构造方法来剖析 ArrayList提供了3种构造方法以便我们来获取: ArrayList(int initialCapacity) 第一种需要赋值长度进行new ArrayList() 第二种无参构造,不需要赋值数组初始长度 ArrayList(Collection<? extends E> c) 第三种入参一个继承了Collec
-
新手入门了解ArrayList扩容机制
我们下面用最简单的代码创建ArrayList并添加11个元素,并 一 一 讲解底层源码:在说之前,给大家先普及一些小知识: >ArrayList底层是用数组来实现的 >数组一旦创建后,大小就是固定的,如果超出了数组大小后,就会创建一个新的数组 >接下来所谓数组的扩容实质上是重新创建一个大小更大的新数组 @Test public void testArrayList() { //创建一个泛型为String的ArrayList(这里泛型是什么不重要) ArrayList<String&
-
对Java ArrayList的自动扩容机制示例讲解
注意: 不同的JDK版本的扩容机制可能有差异 实验环境:JDK1.8 扩容机制: 当向ArrayList中添加元素的时候,ArrayList如果要满足新元素的存储超过ArrayList存储新元素前的存储能力,ArrayList会增强自身的存储能力,已达到存储新元素的要求 ArrayList:本质通过内部维护的数组对象进行数据存储 ①:分析ArrayList的add(E)方法 public boolean add(E e) { ensureCapacityInternal(size + 1); /
-
聊一聊jdk1.8中的ArrayList 底层数组是如何扩容的
一.结论先行 ArrayList在JDK1.8与JDK1.7底层区别 JDK1.7:ArrayList像饿汉式,直接创建一个初始容量为10的数组,当数组的长度不能容下所添加的内容时候,数组会扩容至原大小的1.5倍 JDK1.8:ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时再创建一个始容量为10的数组,当数组的长度不能容下所添加的内容时候,数组会扩容至原大小的1.5倍 二.JDK1.8 ArrayList源码分析 1.ArrayList 属性 /** * 默认容量的
-
Java中Arraylist动态扩容方法详解
前言 本文主要给大家介绍了关于Java中Arraylist动态扩容的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. ArrayList 概述 ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长.ArrayList不是线程安全的,只能用在单线程环境下.实现了Serializable接口,因此它支持序列化,能够通过序列化传输:实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问:实现了Cloneable接口,能被克隆.
-
Java使用数组实现ArrayList的动态扩容的方法
提到数组大家肯定不会陌生,但我们也知道数组有个缺点就是在创建时就确定了长度,之后就不能更改长度.所以Java官方向我们提供了ArrayList这个可变长的容器.其实ArrayList底层也是用数组进行实现的,今天我们就自己使用数组实现ArrayList的功能. 一.整体框架 废话不多说,我们以存放int类型元素为例,看一下ArrayList需要的成员变量和需要实现的方法. public class ArrayList private int size;//用来记录实际存储元素个数 private
-
ArrayList及HashMap的扩容规则讲解
1.ArrayList 默认大小为10 /** * Default initial capacity. */ private static final int DEFAULT_CAPACITY = 10; 最大容量为2^30 - 8 /** * The maximum size of array to allocate. * Some VMs reserve some header words in an array. * Attempts to allocate larger arrays m
-
在java中ArrayList集合底层的扩容原理
第一章 前言概述 第01节 概述 底层说明 ArrayList是List的实现类,它的底层是用Object数组存储,线程不安全 后期应用 适合用于频繁的查询工作,因为底层是数组,可以快速通过数组下标进行查找 第02节 区别 区别方向 ArrayList集合 LinkedList集合 线程安全 不安全 不安全 底层原理 Object类型数组 双向链表 随机访问 支持(实现 RandomAccess接口) 不支持 内存占用 ArrayList 浪费空间, 底层是数组,末尾预留一部分容量空间 Link
-
Java ArrayList扩容问题实例详解
本文研究的主要是Java ArrayList扩容问题实例详解的相关内容,具体介绍如下. 首先我们需要知道ArrayList里面的实质的其实是一个Object类型的数组,ArrayList的扩容问题其实就是这个Object类型的数组的扩容问题. transient Object[] elementData; 一.创建时,ArrayList的容量分配 创建一个ArrayList有三种情况 1.默认大小创建(默认为0) ArrayList al = new ArrayList(); 创建完成之后,al
-
详解ArrayList的扩容机制
目录 一.ArrayList 了解过吗?它是啥?有啥用? 二.ArrayList 如何指定底层数组大小的 三.数组的大小一旦被规定就无法改变 四.ArrayList 具体是怎么添加数据的 五.ArrayList 又是如何删除数据的呢 六.ArrayList 是线程安全的吗?不安全的表现 七.为什么线程不安全还要用它呢 一.ArrayList 了解过吗?它是啥?有啥用? 众所周知,Java 集合框架拥有两大接口 Collection 和 Map,其中,Collection 麾下三生子 List.S
-
详解java实践SPI机制及浅析源码
1.概念 正式步入今天的核心内容之前,溪源先给大家介绍一下关于SPI机制的相关概念,最后会提供实践源代码. SPI即Service Provider Interface,属于JDK内置的一种动态的服务提供发现机制,可以理解为运行时动态加载接口的实现类.更甚至,大家可以将SPI机制与设计模式中的策略模式建立联系. SPI机制: 从上图中理解SPI机制:标准化接口+策略模式+配置文件: SPI机制核心思想:系统设计的各个抽象,往往有很多不同的实现方案,在面向的对象的设计里,一般推荐模块之间基于接口编
-
详解Java的类加载机制及热部署的原理
一.什么是类加载 类的加载指的是将类的.class文件的二进制数据读入到内存中,将其放在运行数据区的方法去,然后再堆区创建一个java.lang.Class对象,用来封装类在方法区的数据结构.类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区的数据结构,并且向Java程序员提供了访问方法区的数据结构的接口. 类加载器并不需要等到某个类被"首次主动使用"时再加载它,JVM规范允许类加载器在预料某个类将要被使用时就预先加载它,如果在预先加载的过程中遇到了.cla
-
详解php内存管理机制与垃圾回收机制
一.内存管理机制 先看一段代码: <?php //内存管理机制 var_dump(memory_get_usage());//获取内存方法,加上true返回实际内存,不加则返回表现内存 $a = "laruence"; var_dump(memory_get_usage()); unset($a); var_dump(memory_get_usage()); //输出(在我的个人电脑上, 可能会因为系统,PHP版本,载入的扩展不同而不同): //int 240552 //int
-
详解Spring的核心机制依赖注入
详解Spring的核心机制依赖注入 对于一般的Java项目,他们都或多或少有一种依赖型的关系,也就是由一些互相协作的对象构成的.Spring把这种互相协作的关系称为依赖关系.如A组件调用B组件的方法,可称A组件依赖于B组件,依赖注入让Spring的Bean以配置文件组织在一起,而不是以硬编码的方式耦合在一起 一.理解依赖注入 依赖注入(Dependency Injection) = 控制反转(Inversion ofControl,IoC):当某个Java实例(调用者)需另一个Java实例(被调
-
详解struts2的token机制和cookie来防止表单重复提交
详解struts2的token机制和cookie来防止表单重复提交 今天在做一个投票系统时要实现防止表单重复提交! 当时就想到了用struts2提供的token机制 struts2的token机制防止表单重复提交: 首先需要在提交的jsp页面(要使用token机制,必须使用struts2提供的标签库)加上 <s:token></s:token> 这段代码,然后在struts.xml里面需要进行如下配置: <action name="token" class
-
详解java中反射机制(含数组参数)
详解java中反射机制(含数组参数) java的反射是我一直非常喜欢的地方,因为有了这个,可以让程序的灵活性大大的增加,同时通用性也提高了很多.反射原理什么的,我就不想做过大介绍了,网上一搜,就一大把.(下面我是只附录介绍下) Reflection 是Java被视为动态(或准动态)语言的一个关键性质.这个机制允许程序在运行时透过Reflection APIs取得任何一个已知名称的class的内部信息,包括其modifiers(诸如public, static 等等).superclass(例如O
-
详解C语言进程同步机制
本文是对进程同步机制的一个大总结(9000+字吐血总结),涵盖面非常的全,包括了进程同步的一些概念.软件同步机制.硬件同步机制.信号量机制和管程机制,对每种机制结合代码做了详细的介绍,并且对琐碎的知识点和概念解释的非常清晰. 在前面的博客中讲述了进程的状态及其状态的转换,每种状态的含义和转换的原因.同样我们也知道,在OS引入了进程后,可以使系统中的多道程序可以并发的执行,进程的并发执行一方面极大的提高了系统的资源利用率和吞吐量,但是另一方面却使系统变得更加复杂,如果不能采取有效的措施,对多个
-
详解Python中import机制
Python语言中import的使用很简单,直接使用import module_name语句导入即可.这里我主要写一下"import"的本质. Python官方定义: Python code in one module gains access to the code in another module by the process of importing it. 1.定义: 模块(module):用来从逻辑(实现一个功能)上组织Python代码(变量.函数.类),本质就是*.py文
-
详解JavaScript 的执行机制
一.关于javascript javascript是一门单线程语言,在最新的HTML5中提出了Web Worker,但javascript是单线程这一核心仍未改变. 为什么js是单线程的语言?因为最初的js是用来在浏览器验证表单操纵DOM元素的.如果js是多线程的话,两个线程同时对一个DOM进行了相互冲突的操作,那么浏览器的解析是无法执行的. Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行.在主线程运行的同