python手写均值滤波
本文实例为大家分享了python手写均值滤波的具体代码,供大家参考,具体内容如下
原理与卷积类似,设置一个n*n的滤波模板,滤波模板内的值累加除以模板的尺寸大小取平均为滤波后的值。
代码如下:
import cv2 as cv
import numpy as np
#均值滤波
def meansBlur(src, ksize):
'''
:param src: input image
:param ksize:kernel size
:return dst: output image
'''
dst = np.copy(src) #创建输出图像
kernel = np.ones((ksize, ksize)) # 卷积核
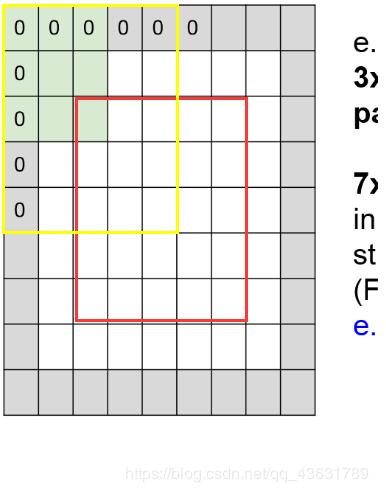
padding_num = int((ksize - 1) / 2) #需要补0
dst = np.pad(dst, (padding_num, padding_num), mode="constant", constant_values=0)
w, h = dst.shape
dst = np.copy(dst)
for i in range(padding_num, w - padding_num):
for j in range(padding_num, h - padding_num):
dst[i, j] = np.sum(kernel * dst[i - padding_num:i + padding_num + 1, j - padding_num:j + padding_num + 1]) \
// (ksize ** 2)
dst = dst[padding_num:w - padding_num, padding_num:h - padding_num] #把操作完多余的0去除,保证尺寸一样大
return dst
img_path = r"F:\03.png"
img = cv.imread(img_path,0)
dst = meansBlur(img,5)
cv.imshow('src',img)
cv.imshow('dst',dst)
print(dst)
cv.waitKey(0)
注释:红框表示两个for循环的范围,i - padding_num:i + padding_num + 1表示第i行上移padding_num行,下移padding_num,+1是因为list列表为左闭右开区间,右边的元素取不到值。padding表示周围填充一圈。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python 实现中值滤波、均值滤波的方法
红包: Lena椒盐噪声图片: # -*- coding: utf-8 -*- """ Created on Sat Oct 14 22:16:47 2017 @author: Don """ from tkinter import * from skimage import io import numpy as np im=io.imread('lena_sp.jpg', as_grey=True) im_copy_med = io.imrea
-

opencv+python实现均值滤波
本文实例为大家分享了opencv+python实现均值滤波的具体代码,供大家参考,具体内容如下 原理 均值滤波其实就是对目标像素及周边像素取平均值后再填回目标像素来实现滤波目的的方法,当滤波核的大小是3×3 3\times 33×3时,则取其自身和周围8个像素值的均值来代替当前像素值. 均值滤波也可以看成滤波核的值均为 1 的滤波. 优点:算法简单,计算速度快: 缺点:降低噪声的同时使图像产生模糊,特别是景物的边缘和细节部分. 代码 import cv2 as cv import numpy a
-
python手写均值滤波
本文实例为大家分享了python手写均值滤波的具体代码,供大家参考,具体内容如下 原理与卷积类似,设置一个n*n的滤波模板,滤波模板内的值累加除以模板的尺寸大小取平均为滤波后的值. 代码如下: import cv2 as cv import numpy as np #均值滤波 def meansBlur(src, ksize): ''' :param src: input image :param ksize:kernel size :return dst: output image ''' d
-
基于Python手写拼音识别
目录 一.算法构造 1.简单介绍一下knn算法 2.Python实现KNN 二.准备数据 1.将图片转换成数组矩阵 三.处理数据:训练集与测试集 1.区分训练集和测试集 2.加载数据 3.建立训练数据 四.测试数据 一.算法构造 1.简单介绍一下knn算法 KNN算法,也叫K最近邻算法.功能是分类.算法逻辑非常简单,说直白点就是:先找到跟你最近的k个邻居(假设k=5),再看你的邻居给哪个类别投票(即邻居的标签),少数服从多数,得票最多的结果就是你的类别. 在这个算法中最关键的三点: k值 :选择
-
Python手写回归树的实现
目录 回归树 创建子节点 预测 计算误差 概括的步骤 更深入的模型 在本篇文章中,我们将介绍回归树及其基本数学原理,并从头开始使用Python实现一个完整的回归树模型. 为了简单起见这里将使用递归来创建树节点,虽然递归不是一个完美的实现,但是对于解释原理他是最直观的. 首先导入库 import pandas as pd import numpy as np import matplotlib.pyplot as plt 首先需要创建训练数据,我们的数据将具有独立变量(x)和一个相关的变量(y),
-
caffe的python接口之手写数字识别mnist实例
目录 引言 一.数据准备 二.导入caffe库,并设定文件路径 二.生成配置文件 三.生成参数文件solver 四.开始训练模型 五.完成的python文件 引言 深度学习的第一个实例一般都是mnist,只要这个例子完全弄懂了,其它的就是举一反三的事了.由于篇幅原因,本文不具体介绍配置文件里面每个参数的具体函义,如果想弄明白的,请参看我以前的博文: 数据层及参数 视觉层及参数 solver配置文件及参数 一.数据准备 官网提供的mnist数据并不是图片,但我们以后做的实际项目可能是图片.因此有些
-
python神经网络编程之手写数字识别
写在之前 首先是写在之前的一些建议: 首先是关于这本书,我真的认为他是将神经网络里非常棒的一本书,但你也需要注意,如果你真的想自己动手去实现,那么你一定需要有一定的python基础,并且还需要有一些python数据科学处理能力 然后希望大家在看这边博客的时候对于神经网络已经有一些了解了,知道什么是输入层,什么是输出层,并且明白他们的一些理论,在这篇博客中我们仅仅是展开一下代码: 然后介绍一下本篇博客的环境等: 语言:Python3.8.5 环境:jupyter 库文件: numpy | matp
-
Python实现带GUI界面的手写数字识别
目录 1.效果图 2.数据集 3.关于模型 4.关于GUI设计 5.缺点 6.遗留问题 1.效果图 有点low,轻喷 点击选择图片会优先从当前目录查找 2.数据集 这部分我是对MNIST数据集进行处理保存 对应代码: import tensorflow as tf import matplotlib.pyplot as plt import cv2 from PIL import Image import numpy as np from scipy import misc (x_train_a
-
如何用Python徒手写线性回归
对于大多数数据科学家而言,线性回归方法是他们进行统计学建模和预测分析任务的起点.这种方法已经存在了 200 多年,并得到了广泛研究,但仍然是一个积极的研究领域.由于良好的可解释性,线性回归在商业数据上的用途十分广泛.当然,在生物数据.工业数据等领域也不乏关于回归分析的应用. 另一方面,Python 已成为数据科学家首选的编程语言,能够应用多种方法利用线性模型拟合大型数据集显得尤为重要. 如果你刚刚迈入机器学习的大门,那么使用 Python 从零开始对整个线性回归算法进行编码是一次很有意义的尝试,
-
Python(TensorFlow框架)实现手写数字识别系统的方法
手写数字识别算法的设计与实现 本文使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统.这是本人的本科毕业论文课题,当然,这个也是机器学习的基本问题.本博文不会以论文的形式展现,而是以编程实战完成机器学习项目的角度去描述. 项目要求:本文主要解决的问题是手写数字识别,最终要完成一个识别系统. 设计识别率高的算法,实现快速识别的系统. 1 LeNet-5模型的介绍 本文实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示
-
Python实战之MNIST手写数字识别详解
目录 数据集介绍 1.数据预处理 2.网络搭建 3.网络配置 关于优化器 关于损失函数 关于指标 4.网络训练与测试 5.绘制loss和accuracy随着epochs的变化图 6.完整代码 数据集介绍 MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片,且内置于keras.本文采用Tensorflow下Keras(Keras中文文档)神经网络API进行网络搭建. 开始之前,先回忆下机器学习
-
Python与人工神经网络:使用神经网络识别手写图像介绍
人体的视觉系统是一个相当神奇的存在,对于下面的一串手写图像,可以毫不费力的识别出他们是504192,轻松到让人都忘记了其实这是一个复杂的工作. 实际上在我们的大脑的左脑和右脑的皮层都有一个第一视觉区域,叫做V1,里面有14亿视觉神经元.而且,在我们识别上面的图像的时候,工作的不止有V1,还有V2.V3.V4.V5,所以这么一看,我们确实威武. 但是让计算机进行模式识别,就比较复杂了,主要困难在于我们如何给计算机描述一个数字9在图像上应该是怎样的,比如我们跟计算机说,9的上面是一个圈,下右边是1竖