pandas is in和not in的使用说明
简介
pandas按条件筛选数据时,除了使用query()方法,还可以使用isin和对isin取反进行条件筛选.
代码
import pandas as pd
df = pd.DataFrame({'a':[1, 2, 3, 4, 5, 6],
'b':[1, 2, 3, 4, 5, 6],
'c':[1, 2, 3, 4, 5, 6]})
filter_condition = {'a':[1, 2, 3]}
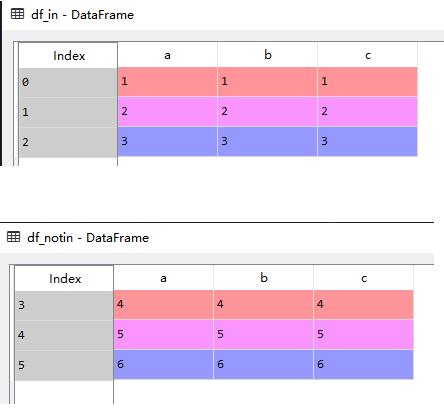
df_in = df[df.isin(filter_condition)['a']]
df_notin = df[~df.isin(filter_condition)['a']]
df.isin(filter_condition)
a b c
0 True True False
1 True True False
2 True False False
3 False False False
4 False False False
5 False False False
使用总结
pandas使用isin时,返回DataFrame中存储的数据为是否满足筛选条件的boolean,可以通过boolean对DataFrame对数据进行筛选。
补充:pandas中isin()函数及其逆函数使用
我使用这个函数就是用来清洗数据,删选过滤掉DataFrame中一些行。
布尔索引
这里你需要知道DateFrame中布尔索引这个东西,可以用满足布尔条件的列值来过滤数据,如下
>>> df=pd.DataFrame(np.random.randn(4,4),columns=['A','B','C','D']) >>> df A B C D 0 -0.018330 2.093506 -0.086293 -2.150479 1 0.104931 -0.271810 -0.054599 0.361612 2 0.590216 0.218049 0.157213 0.643540 3 -0.254449 -0.593278 -0.150455 -0.244485 >>> df.A>0#布尔索引 0 False 1 True 2 True 3 False Name: A, dtype: bool #布尔索引应用 >>> df[df.A>0] A B C D 1 0.104931 -0.271810 -0.054599 0.361612 2 0.590216 0.218049 0.157213 0.643540 >>>
isin()
添加一列E
>>> df['E']=['a','a','c','b'] >>> df A B C D E 0 -0.018330 2.093506 -0.086293 -2.150479 a 1 0.104931 -0.271810 -0.054599 0.361612 a 2 0.590216 0.218049 0.157213 0.643540 c 3 -0.254449 -0.593278 -0.150455 -0.244485 b >>> df.E.isin(['a','c']) 0 True 1 True 2 True 3 False Name: E, dtype: bool >>> df.isin(['b','c'])#整个df也同样适用 A B C D E 0 False False False False False 1 False False False False False 2 False False False False True 3 False False False False True #应用 >>> df[df.E.isin(['a','c'])] A B C D E 0 -0.018330 2.093506 -0.086293 -2.150479 a 1 0.104931 -0.271810 -0.054599 0.361612 a 2 0.590216 0.218049 0.157213 0.643540 c >>>
isin()接受一个列表,判断该列中元素是否在列表中。
同时对多个列过滤,可以如下使用
df[df[某列].isin(条件)&df[某列].isin(条件)] #应用 >>> df.D=[0,1,0,2] >>> df[df.E.isin(['a','d'])&df.D.isin([0,])] A B C D E 0 -0.01833 2.093506 -0.086293 0 a
也可以
不推荐,你试一下就知道
df.isin({
'某列':[条件],
'某列':[条件],
})
#应用
>>> df.D=[0,1,0,2]
>>> df
A B C D E
0 -0.018330 2.093506 -0.086293 0 a
1 0.104931 -0.271810 -0.054599 1 a
2 0.590216 0.218049 0.157213 0 c
3 -0.254449 -0.593278 -0.150455 2 b
>>> df[df.isin({'D':[0,3],'E':['a','d']})]
A B C D E
0 NaN NaN NaN 0.0 a
1 NaN NaN NaN NaN a
2 NaN NaN NaN 0.0 NaN
3 NaN NaN NaN NaN NaN
#没错这不适合选出一行
>>> df.isin({'D':[0,3],'E':['a','d']})
A B C D E
0 False False False True True
1 False False False False True
2 False False False True False
3 False False False False False
isin()的逆函数
告诉你没有isnotin,它的反函数就是在前面加上 ~ ,其他用法同上。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

pandas 查询函数query的用法说明
query() 函数简介 pandas的query()方法是基于DataFrame列的计算代数式,对于按照某列的规则进行过滤的操作,可以使用query方法. 代码示例 import pandas as pd df = pd.DataFrame({'a':[1, 2, 3, 4, 5, 6], 'b':[1, 2, 3, 4, 5, 6], 'c':[1, 2, 3, 4, 5, 6]}) query_list = [1, 2] df_2 = df.query('c not in @query_l
-
Pandas探索之高性能函数eval和query解析
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一. 相较于 Python 的内置函数, Pandas 库为我们提供了一系列性能更高的数据处理函数,本节将向大家介绍 Pandas 库
-
使用pandas读取表格数据并进行单行数据拼接的详细教程
业务需求 一个几十万条数据的Excel表格,现在需要拼接其中某一列的全部数据为一个字符串,例如下面简短的几行表格数据: id code price num 11 22 33 44 22 33 44 55 33 44 55 66 44 55 66 77 55 66 77 88 66 77 88 99 现在需要将code的这一列用逗号,拼接为字符串,并且每个单元格数据都用单引号包含,需要拼接成字符串'22','33','44','55','66','77',这样的情况,我们需要怎么处理呢?当然方式有
-
pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
pandas is in和not in的使用说明
简介 pandas按条件筛选数据时,除了使用query()方法,还可以使用isin和对isin取反进行条件筛选. 代码 import pandas as pd df = pd.DataFrame({'a':[1, 2, 3, 4, 5, 6], 'b':[1, 2, 3, 4, 5, 6], 'c':[1, 2, 3, 4, 5, 6]}) filter_condition = {'a':[1, 2, 3]} df_in = df[df.isin(filter_condition)['a']]
-
Python pandas轴旋转stack和unstack的使用说明
摘要 前面给大家分享了pandas做数据合并的两篇[pandas.merge]和[pandas.cancat]的用法.今天这篇主要讲的是pandas的DataFrame的轴旋转操作,stack和unstack的用法. 首先,要知道以下五点: 1.stack:将数据的列"旋转"为行 2.unstack:将数据的行"旋转"为列 3.stack和unstack默认操作为最内层 4.stack和unstack默认旋转轴的级别将会成果结果中的最低级别(最内层) 5.stack
-
pandas groupby + unstack的使用说明
概述 groupby()可以根据DataFrame中的某一列或者多列内容进行分组聚合,当DataFrame聚合后为两列索引时,可以使用unstack()将聚合的两列中一列值调整为行索引,另一列的值调整为列索引. 代码说明 test_df = pd.DataFrame({ 'col_1':['a', 'a', 'b', 'a', 'a', 'b', 'c', 'a', 'c'], 'col_2':['d', 'd', 'd', 'e', 'f', 'e', 'd', 'f', 'f'], 'col
-
Pandas的MultiIndex多层索引使用说明
目录 MultiIndex多层索引 1.创建方式 1.1.第一种:多维数组 1.2.第二种:MultiIndex 2.多层索引操作 2.1.Series多层索引 2.2.DataFrame多层索引 2.3.交换索引 2.4.索引排序 2.5.索引堆叠 2.6.取消堆叠 2.7.设置索引 2.8.重置索引 MultiIndex多层索引 MultiIndex,即具有多个层次的索引,有些类似于根据索引进行分组的形式.通过多层次索引,我们就可以使用高层次的索引,来操作整个索引组的数据.通过给索引分类分组
-
详解PANDAS 数据合并与重塑(join/merge篇)
在上一篇文章中,我整理了pandas在数据合并和重塑中常用到的concat方法的使用说明.在这里,将接着介绍pandas中也常常用到的join 和merge方法 merge pandas的merge方法提供了一种类似于SQL的内存链接操作,官网文档提到它的性能会比其他开源语言的数据操作(例如R)要高效. 和SQL语句的对比可以看这里 merge的参数 on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名. left_on:左表对齐的列,
-
pandas之query方法和sample随机抽样操作
query方法 在 pandas 中,支持把字符串形式的查询表达式传入 query 方法来查询数据,其表达式的执行结果必须返回布尔列表.在进行复杂索引时,由于这种检索方式无需像普通方法一样重复使用 DataFrame 的名字来引用列名,一般而言会使代码长度在不降低可读性的前提下有所减少. 例如 In [61]: df.query('((School == "Fudan University")&' ....: ' (Grade == "Senior")&am
-
Python入门之使用pandas分析excel数据
1.问题 在python中,读写excel数据方法很多,比如xlrd.xlwt和openpyxl,实际上限制比较多,不是很方便.比如openpyxl也不支持csv格式.有没有更好的方法? 2.方案 更好的方法可以使用pandas,虽然pandas不是专门处理excel数据,但处理excel数据确实很方便. 本文使用excel的数据来自网络,数据内容如下: 2.1.安装 使用pip进行安装. pip3 install pandas 导入pandas: import pandas as pd 下文使
-
Python Pandas读取csv/tsv文件(read_csv,read_table)的区别
目录 前言 read_csv()和read_table()之间的区别 读取没有标题的CSV 读取有标题的CSV 读取有index的CSV 指定(选择)要读取的列 跳过(排除)行的读取 skiprows skipfooter nrows 通过指定类型dtype进行读取 NaN缺失值的处理 读取使用zip等压缩的文件 tsv的读取 总结 前言 要将csv和tsv文件读取为pandas.DataFrame格式,可以使用Pandas的函数read_csv()或read_table(). 在此 read_
-
Python+pandas编写命令行脚本操作excel的tips详情
目录 一.python logging日志模块简单封装 二.pandas编写命令行脚本操作excel的小tips 1.tips 1.1使用说明格式 1.2接收操作目录方法 1.3检测并读取目录下的excel,并限制当前目录只能放一个excel 1.4备份excel 1.5报错暂停,并显示异常信息 1.6判断excel是否包含某列,不包含就新建 1.7进度展示与阶段保存 一.python logging日志模块简单封装 项目根目录创建 utils/logUtil.py import logging
-
Python Pandas的concat合并
目录 使用场景 concat语法 append语法 案例演示 使用场景 批量合并相同格式的Exce,给DataFrame添加行,给DataFrame添加列 使用说明: 1.使用某种合并方式(inner/outer) 2.沿着某个轴向(axis=0/1) 3.把多个Pandas对象(DataFrame/Series)合并成一个 concat语法 pandas.concat(objs,axis=0,join=‘outer’,ignore_index = False) objs:一个列表,内容可以是D