.NET Core使用C#扫描并读取图片中的文字
本文介绍如何通过C# 程序来扫描并读取图片中的文字,这里以创建一个.Net Core程序为例。下面是具体步骤,供参考。
程序测试环境:
- Visual Studio版本要求不低于2017
- 图片扫描工具:Spire.OCR for .NET
- 图片格式:png(这里的图片格式支持JPG、PNG、GIF、BMP、TIFF等格式)
- 扫描的图片文字:中文(另可支持中文、英语、日语、韩语、德语、法语等)
- .Net Core 2.1
详细步骤
1. 创建一个.Net Core控制台应用程序。
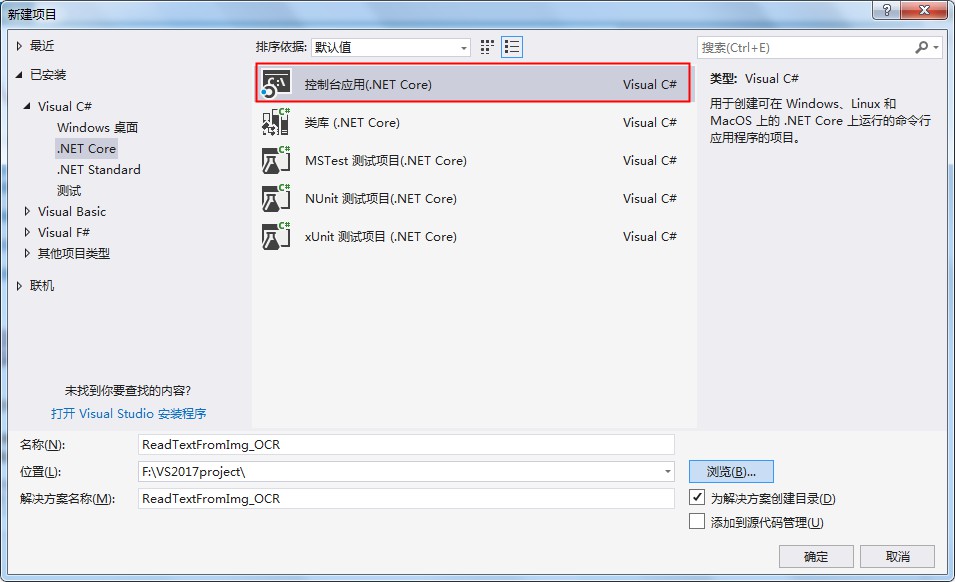
2. 通过NuGet添加依赖
- (1)在【解决方案资源管理器】中,鼠标右键点击【依赖项】,选择【管理NuGet程序包】
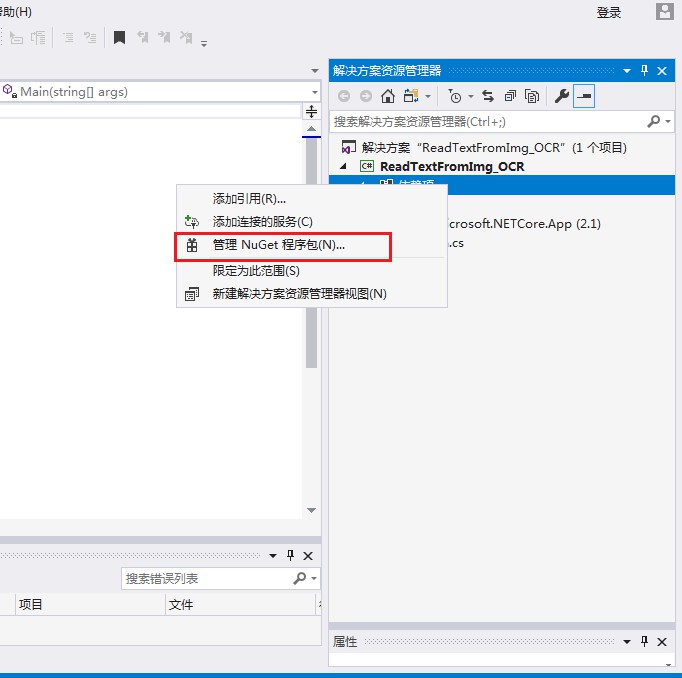
- (2)在弹出的界面中,选择【浏览】-在搜索框中输入Spire.OCR,点击“安装”
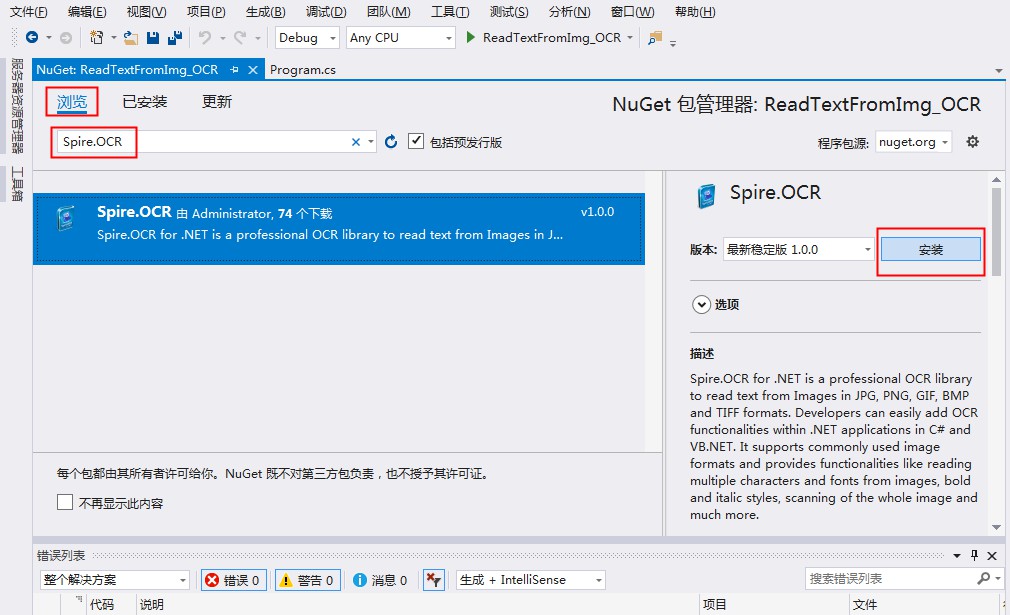
在依次弹出的2个窗口中选择“确定”和“我接受”
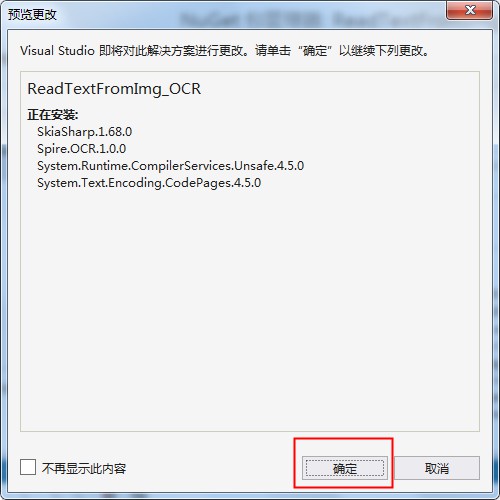
- (3)完成后,可查看到已添加的依赖项

- 3.复制dll
情况1:如果为.net core 3.0及以上版本,则从bin\Debug\netcoreapp3.0\runtimes\win-x64\native文件夹中复制如图中的6个dll文件到程序运行路径bin\Debug\netcoreapp3.0;
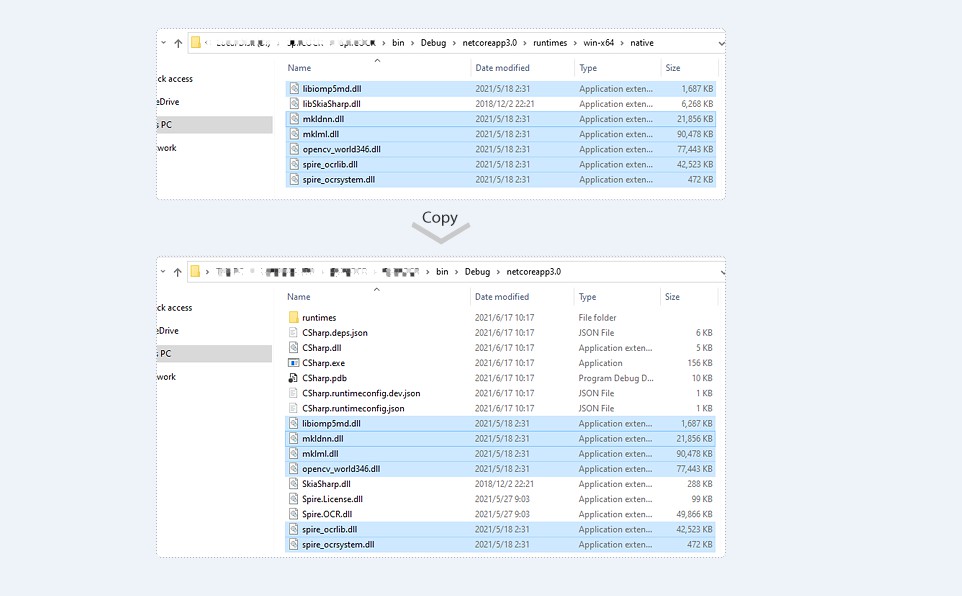
情况2:如果是.net core 3.0以下版本(如本文本中的测试环境),则需要下载Spire.OCR包,并解压,将该文件路径Spire.OCR\Spire.OCR_Dependency\x64中的6个dll复制到程序运行路径F:\VS2017project\ReadTextFromImg_OCR\ReadTextFromImg_OCR\bin\Debug\netcoreapp2.1

- 4.完成以上操作后,可参考如下代码内容,读取图片上的文本内容
using Spire.OCR;
using System.IO;
namespace ReadTextFromImg_OCR
{
class Program
{
static void Main(string[] args)
{
OcrScanner scanner = new OcrScanner();
scanner.Scan("image.png");
File.WriteAllText("output.txt", scanner.Text.ToString());
}
}
}
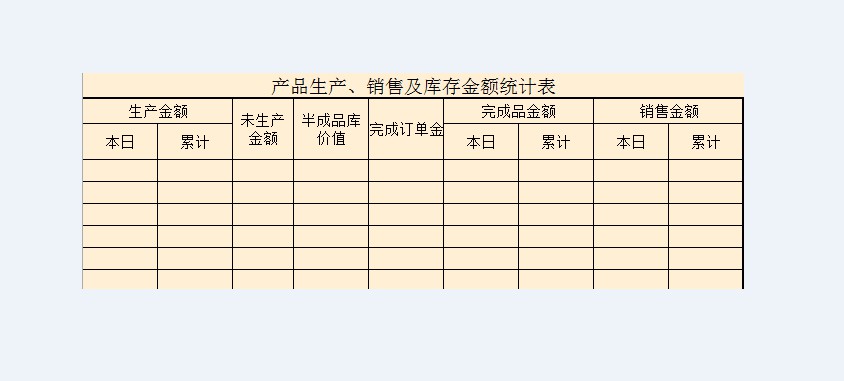
测试图片:
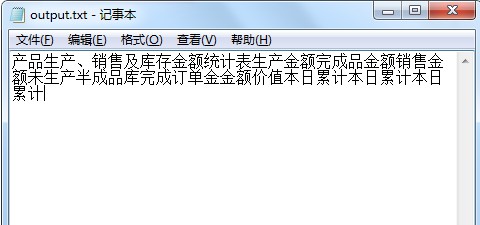
文字读取结果:
★★★注意事项:目前,该OCR控件仅支持64位系统!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

如何使用C#扫描并读取图片中的文字
目录 程序测试环境: 详细步骤 程序测试环境: Visual Studio版本要求不低于2017 图片扫描工具:Spire.OCR for .NET 图片格式:png(这里的图片格式支持JPG.PNG.GIF.BMP.TIFF等格式) 扫描的图片文字:中文(另可支持中文.英语.日语.韩语.德语.法语等) .Net Core 2.1 详细步骤 1. 创建一个.Net Core控制台应用程序. 2. 通过NuGet添加依赖 (1)在[解决方案资源管理器]中,鼠标右键点击[依赖项],选择[管理NuGe
-
C# .NET实现扫描识别图片中的文字
目录 环境配置 操作步骤 调用API接口扫描并读取图片中的文字 C# VB.NET 注意事项 环境配置 本文以C#及VB.NET代码为例,介绍如何扫描并读取图片中的文字. 本次程序环境如下: Visual Studio版本要求不低于2017 图片扫描工具:Spire.OCR for .NET 图片格式:png(这里的图片格式支持JPG.PNG.GIF.BMP.TIFF等格式) 扫描的图片文字:中文(另外可支持英语.日语.韩语.德语.法语等) .NET Framework 4.6.1 下面是具体步
-
c#扫描图片去黑边(扫描仪去黑边)
自动去除图像扫描黑边 复制代码 代码如下: /// <summary> /// 自动去除图像扫描黑边 /// </summary> /// <param name="fileName"></param> public static void AutoCutBlackEdge(string fileName) { //打开图像
-
.NET Core使用C#扫描并读取图片中的文字
本文介绍如何通过C# 程序来扫描并读取图片中的文字,这里以创建一个.Net Core程序为例.下面是具体步骤,供参考. 程序测试环境: Visual Studio版本要求不低于2017 图片扫描工具:Spire.OCR for .NET 图片格式:png(这里的图片格式支持JPG.PNG.GIF.BMP.TIFF等格式) 扫描的图片文字:中文(另可支持中文.英语.日语.韩语.德语.法语等) .Net Core 2.1 详细步骤 1. 创建一个.Net Core控制台应用程序. 2. 通过NuGe
-
如何利用Python识别图片中的文字
一.前言 不知道大家有没有遇到过这样的问题,就是在某个软件或者某个网页里面有一篇文章,你非常喜欢,但是不能复制.或者像百度文档一样,只能复制一部分,这个时候我们就会选择截图保存.但是当我们想用到里面的文字时,还是要一个字一个字打出来.那么我们能不能直接识别图片中的文字呢?答案是肯定的. 二.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需
-
如何利用Python识别图片中的文字详解
一.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需要完成一个繁琐的工作. (1)Tesseract的安装及配置 Tesseract的安装我们可以移步到该网址 https://digi.bib.uni-mannheim.de/tesseract/,我们可以看到如下界面: 有很多版本供大家选择,大家可以根据自己的需求选择.其中w32表示32
-
Android编程实现支持拖动改变位置的图片中叠加文字功能示例
本文实例讲述了Android编程实现支持拖动改变位置的图片中叠加文字功能.分享给大家供大家参考,具体如下: 之所以做了这么一个Demo,是因为最近项目中有一个奇葩的需求:用户拍摄照片后,分享到微信的同时添加备注,想获取用户在微信的弹出框输入的内容,保存在自己的服务器上.而事实上,这个内容程序是无法获取的,因此采取了一个折衷方案,将文字直接写在图片上. 首先上Demo效果图: 功能: 1.用户自由输入内容,可手动换行,并且行满也会自动换行. 2.可拖动改变图片中文本位置(文字不会超出图片区域).
-
python 识别图片中的文字信息方法
最近朋友需要一个可以识别图片中的文字的程序,以前做过java验证码识别的程序: 刚好最近在做一个python项目,所以顺便用Python练练手 1.需要的环境: 2.7或者3.4版本的python 2.需要安装pytesseract库 依赖PIL和tesseract-ocr库 本地环境是ubuntu,下面说一下 具体步骤: 2.7 1.安装PIL: 直接使用pip 安装: pip install Pillow 2.安装tesseract-ocr: apt-get install tesserac
-
Python3调用百度AI识别图片中的文字功能示例【测试可用】
本文实例讲述了Python3调用百度AI识别图片中的文字功能.分享给大家供大家参考,具体如下: 首先pip install命令安装baidu-aip模块,如下图所示(这里使用pip3 install baidu-aip命令): 编辑Python代码时注意,需要首先引入AipOcr和re两个模块,即: from aip import AipOcr import re 示例代码如下: from aip import AipOcr import re APP_ID='***' API_KEY='***
-
Python中文件的写入读取以及附加文字方法
今天学习到python的读取文件部分. 还是以一段代码为例: filename='programming.txt' with open(filename,'w') as file_object: file_object.write("I love programming.\n") file_object.write("I love travelling.\n") 在这里调用open打开文件,两个实参,一个是要打开的文件名称,第二个实参('w')是告诉Python我们
-
如何使用Python进行OCR识别图片中的文字
朋友需要一个工具,将图片中的文字提取出来.我帮他在网上找了一些OCR的应用,都不好用.所以准备自己研究,写一个Web APP供他使用. OCR1,全称Optical character recognition,或者optical character reader,中文译名叫做光学文字识别.它是把图像文件中的手写文本,打印文本转换为机器编码文本的一种方法. OCR技术广泛用于识别打印纸张中的文字数据 -- 比如护照,支票,银行声明,收据,统计表单,邮件等.OCR的早期版本,需要对图片中的每个文字都