Python使用urlretrieve实现直接远程下载图片的示例代码
在实现爬虫任务时,经常需要将一些图片下载到本地当中。那么在python中除了通过open()函数,以二进制写入方式来下载图片以外,还有什么其他方式吗?本文将使用urlretrieve实现直接远程下载图片。
下面我们再来看看 urllib 模块提供的 urlretrieve() 函数。urlretrieve() 方法直接将远程数据下载到本地。
>>> help(urllib.urlretrieve) Help on function urlretrieve in module urllib: urlretrieve(url, filename=None, reporthook=None, data=None)
参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数 reporthook 是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数 data 指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
下面通过例子来演示一下这个方法的使用,这个例子将 google 的 html 抓取到本地,保存在 D:/google.html 文件中,同时显示下载的进度。
import urllib
def cbk(a, b, c):
'''回调函数
@a: 已经下载的数据块
@b: 数据块的大小
@c: 远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100:
per = 100
print '%.2f%%' % per
url = 'http://www.google.com'
local = 'd://google.html'
urllib.urlretrieve(url, local, cbk)
代码实现
在python中除了使用open()函数实现图片的下载,还可以通过urllib.request模块中的urlretrieve实现直接远程下载图片的操作。以远程下载某网页外设产品图片为例,代码如下:
import requests
import urllib.request
import os # 系统模块
import shutil # 文件夹控制
def download_pictures(url):
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"}
response = requests.get(url, headers=headers) # 发送网络请求 获取响应
if response.status_code == 200: # 判断请求是否成功
# print(response.json())
# 每次获取数据之前,先将保存图片的文件夹清空 在创建目录
if os.path.exists("img_download"): # 判断文件夹是否存在
shutil.rmtree("img_download") # 存在则删除
os.makedirs("img_download") # 重新创建
else:
os.makedirs("img_download") # 不存在 直接创建
content = response.json()["products"] # 获取响应内容
print(content)
for index, item in enumerate(content):
# 图片地址
img_path = "http://img13.360buyimg.com/n1/s320x320_" + item["imgPath"]
# print(item["imgPath"])
# 根据下标命名图片名称
urllib.request.urlretrieve(img_path, "img_download/" + "img" + str(index) + ".jpg")
else:
print("请求失败")
if __name__ == '__main__':
download_pictures("https://ch.jd.com/hotsale2?cateid=686")
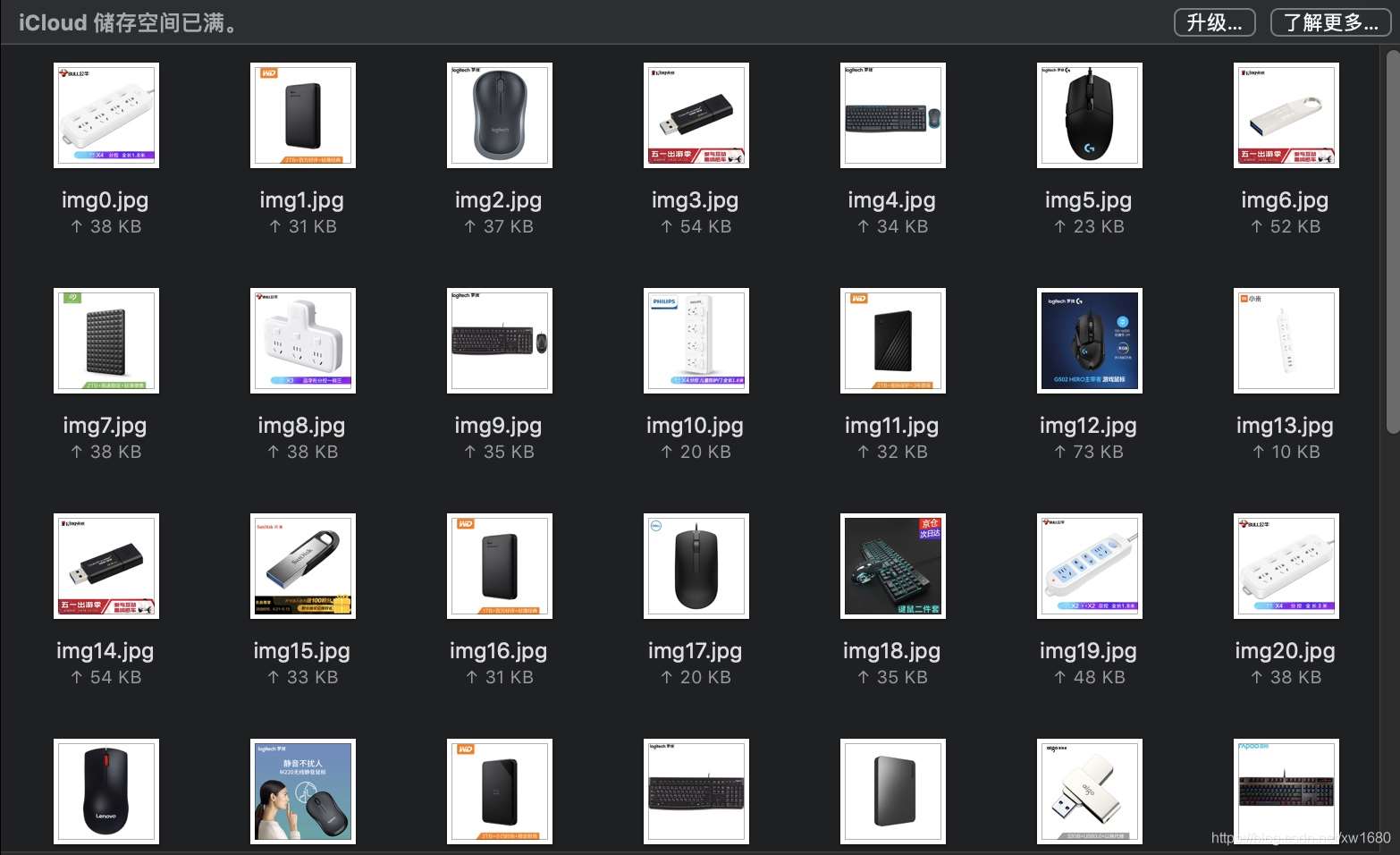
运行结果如下图所示:
到此这篇关于Python使用urlretrieve实现直接远程下载图片的示例代码的文章就介绍到这了,更多相关Python urlretrieve远程下载内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python urllib模块urlopen()与urlretrieve()详解
1.urlopen()方法urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据.参数url表示远程数据的路径,一般是网址:参数data表示以post方式提交到url的数据(玩过web的人应该知道提交数据的两种方式:post与get.如果你不清楚,也不必太在意,一般情况下很少用到这个参数):参数proxies用于设置代理.urlopen返回 一个类文件对象,它提供了如下方法:read(
-
对python中的six.moves模块的下载函数urlretrieve详解
实验环境:windows 7,anaconda 3(python 3.5),tensorflow(gpu/cpu) 函数介绍:所用函数为six.moves下的urllib中的函数,调用如下urllib.request.urlretrieve(url,[filepath,[recall_func,[data]]]).简单介绍一下,url是必填的指的是下载地址,filepath指的是保存的本地地址,recall_func指的是回调函数,下载过程中会调用可以用来显示下载进度. 实验代码:以下载cifa
-
Python urlopen()和urlretrieve()用法解析
这篇文章主要介绍了Python urlopen()和urlretrieve()用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.urlopen()方法 urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据. 参数url表示远程数据的路径,一般是网址: 参数data表示以post方式提交到url的数据(玩过web的人应该知道
-
Python使用urlretrieve实现直接远程下载图片的示例代码
在实现爬虫任务时,经常需要将一些图片下载到本地当中.那么在python中除了通过open()函数,以二进制写入方式来下载图片以外,还有什么其他方式吗?本文将使用urlretrieve实现直接远程下载图片. 下面我们再来看看 urllib 模块提供的 urlretrieve() 函数.urlretrieve() 方法直接将远程数据下载到本地. >>> help(urllib.urlretrieve) Help on function urlretrieve in module urllib
-
Java批量写入文件和下载图片的示例代码
很久没有在WhitMe上写日记了,因为觉着在App上写私密日记的话肯定是不安全的,但是想把日记存下来.,然后看到有导出日记的功能,就把日记导出了(还好可以直接导出,不然就麻烦点).导出的是一个html文件.可以直接打开,排版都还在. 看了下源码,是把日记存在一个json数组里了,图片还是在服务器,利用url访问,文字是在本地了. 但是想把图片下载到本地,然后和文字对应,哪篇日记下的哪些图片. 大概是如下的json数组. 大概有几百条,分别是头像.内容:文字||内容:图片.时间. 简单明了的jso
-

Python之多线程爬虫抓取网页图片的示例代码
目标 嗯,我们知道搜索或浏览网站时会有很多精美.漂亮的图片. 我们下载的时候,得鼠标一个个下载,而且还翻页. 那么,有没有一种方法,可以使用非人工方式自动识别并下载图片.美美哒. 那么请使用python语言,构建一个抓取和下载网页图片的爬虫. 当然为了提高效率,我们同时采用多线程并行方式. 思路分析 Python有很多的第三方库,可以帮助我们实现各种各样的功能.问题在于,我们弄清楚我们需要什么: 1)http请求库,根据网站地址可以获取网页源代码.甚至可以下载图片写入磁盘. 2)解析网页源代码,
-
Python实现多线程下载脚本的示例代码
0x01 分析 一个简单的多线程下载资源的Python脚本,主要实现部分包含两个类: Download类:包含download()和get_complete_rate()两种方法. download()方法种首先用 urlopen() 方法打开远程资源并通过 Content-Length获取资源的大小,然后计算每个线程应该下载网络资源的大小及对应部分吗,最后依次创建并启动多个线程来下载网络资源的指定部分. get_complete_rate()则是用来返回已下载的部分占全部资源大小的比例,用来回
-
Python实现网页文件转PDF文件和PNG图片的示例代码
目录 一.html网页文件转pdf 二.html网页文件转png 一.html网页文件转pdf #将HTML文件导出为PDF def html_to_pdf(html_path,pdf_path='.\\pdf_new.pdf',html_encoding='UTF-8',path_wkpdf = r'.\Tools\wkhtmltopdf.exe'): ''' 将HTML文件导出为PDF :param html_path:str类型,目标HTML文件的路径,可以是一个路径,也可以是多个路径,以
-
如何利用python web框架做文件流下载的实现示例
hello 大家好, 前不久公司里有个需求,把时序数据库中的日志下载到本地. 大家都知道. 数据库里的数据 都是存在数据库里的(废话). 想把他下载到客户的本地. 有的同学第一反应是: 只有文件才能下载. 所以大多数同学会想到先把数据从数据库中读出来,然后写入到服务器中的某个文件夹下生成文件, 然后再下载. 其实这是非常不效率的方法, 最简单的方法是,我们从数据库中读取到文件后, 直接以流的形式让用户去下载. 这里我拿python flask框架来做例子,其实非常简单,步骤一共有3个 1: 取出
-
Python无损压缩图片的示例代码
每个设计师.摄影师或有图片处理需求小编,都会面临批量高清大图的困扰. 因为高清大图放到网站上会严重拖慢加载速度,或是有的地方明确限制了图片大小,因此,为了完成工作,他们总是需要先把图片压缩,再上传. 当需要处理的图片多至十张.百张.千张,则严重影响工作效率.这时候,就可以交给Python啦! 只需要20行Python代码,就可以批量帮你无损压缩数张照片. ---1--- 前期工作 安装Python中现成的图片处理模块,然后将图片打包好导入,用循环的方式自动化处理图片就可以了! ---2--- 运
-
Python生成九宫格图片的示例代码
一.前言 大家在朋友圈应该看到过用一张图片以九宫格的方式显示,效果大致如下: 要实现上面的效果非常简单,我们只需要截取图片的九个区域即可.今天我们就要带大家使用Python来实现一下九宫格图片的生成.在开始之前,我们需要安装一下Pillow模块,语句如下: pip install pillow 下面我们先来看看一些简单的图片操作. 二.图片基本操作 今天我们会使用到三个操作,分别是读取图片.保存图片和截取图片.下面我们分别来看看. 2.1 读取图片 在Pillow中,我们最常用的就是Image子
-
python自动从arxiv下载paper的示例代码
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/02/11 21:44 # @Author : dangxusheng # @Email : dangxusheng163@163.com # @File : download_by_href.py ''' 自动从arxiv.org 下载文献 ''' import os import os.path as osp import requests from lxml impor
-
使用Python获取爱奇艺电视剧弹幕数据的示例代码
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于数据STUDIO,作者龙哥带你飞 Python分析抖音用户行为数据视频讲解地址 https://www.bilibili.com/video/BV1yp4y1q7ZC/ 数据获取是数据分析中的重要的一步,数据获取的途径多种多样,在这个信息爆炸的时代,数据获取的代价也是越来越小.因此如此,仍然有很多小伙伴们无法如何获取有用信息.此处以最近的热播排行榜第一名的<流金岁月>为例,手把手