变长双向rnn的正确使用姿势教学
如何使用双向RNN
在《深度学习之TensorFlow入门、原理与进阶实战》一书的9.4.2中的第4小节中,介绍过变长动态RNN的实现。
这里在来延伸的讲解一下双向动态rnn在处理变长序列时的应用。其实双向RNN的使用中,有一个隐含的注意事项,非常容易犯错。
本文就在介绍下双向RNN的常用函数、用法及注意事项。
动态双向rnn有两个函数:
stack_bidirectional_dynamic_rnn bidirectional_dynamic_rnn
二者的实现上大同小异,放置的位置也不一样,前者放在contrib下面,而后者显得更加根红苗正,放在了tf的核心库下面。在使用时二者的返回值也有所区别。下面就来一一介绍。
示例代码
先以GRU的cell代码为例:
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
# 创建输入数据
X = np.random.randn(2, 4, 5)# 批次 、序列长度、样本维度
# 第二个样本长度为3
X[1,2:] = 0
seq_lengths = [4, 2]
Gstacked_rnn = []
Gstacked_bw_rnn = []
for i in range(3):
Gstacked_rnn.append(tf.contrib.rnn.GRUCell(3))
Gstacked_bw_rnn.append(tf.contrib.rnn.GRUCell(3))
#建立前向和后向的三层RNN
Gmcell = tf.contrib.rnn.MultiRNNCell(Gstacked_rnn)
Gmcell_bw = tf.contrib.rnn.MultiRNNCell(Gstacked_bw_rnn)
sGbioutputs, sGoutput_state_fw, sGoutput_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([Gmcell],[Gmcell_bw], X,sequence_length=seq_lengths, dtype=tf.float64)
Gbioutputs, Goutput_state_fw = tf.nn.bidirectional_dynamic_rnn(Gmcell,Gmcell_bw, X,sequence_length=seq_lengths,dtype=tf.float64)
上面例子中是创建双向RNN的方法示例。可以看到带有stack的双向RNN会输出3个返回值,而不带有stack的双向RNN会输出2个返回值。
这里面还要注意的是,在没有未cell初始化时必须要将dtype参数赋值。不然会报错。
代码:BiRNN输出
下面添加代码,将输出的值打印出来,看一下,这两个函数到底是输出的是啥?
#建立一个会话
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
sgbresult,sgstate_fw,sgstate_bw=sess.run([sGbioutputs,sGoutput_state_fw,sGoutput_state_bw])
print("全序列:\n", sgbresult[0])
print("短序列:\n", sgbresult[1])
print('Gru的状态:',len(sgstate_fw[0]),'\n',sgstate_fw[0][0],'\n',sgstate_fw[0][1],'\n',sgstate_fw[0][2])
print('Gru的状态:',len(sgstate_bw[0]),'\n',sgstate_bw[0][0],'\n',sgstate_bw[0][1],'\n',sgstate_bw[0][2])
先看一下带有stack的双向RNN输出的内容:
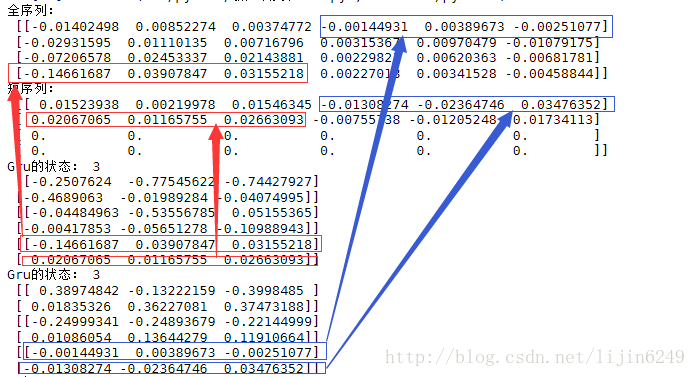
我们输入的数据的批次是2,第一个序列长度是4,第二个序列长度是2.
图中共有4部分输出,可以看到,第一部分(全序列)就是序列长度为4的结果,第二部分(短序列)就是序列长度为2的结果。由于没一层都是由3个RNN的GRU cell组成,所以每个序列的输出都为3.很显然,对于这样的结果输出,必须要将短序列后面的0去掉才可以用。
好在该函数还有第二个输出值,GRU的状态。可以直接使用状态里的值,而不需要对原始结果进行去0的变化。
由于单个GRU本来就是没有状态的。所以该函数将最后的输出作为状态返回。该函数有两个状态返回,分别代表前向和后向。每一个方向的状态都会返回3个元素。这是因为每个方向的网络都有3层GRU组成。在使用时,一般都会取最后一个状态。图中红色部分为前向中,两个样本对应的输出,这个很好理解。
重点要看蓝色的部分,即反向的状态值对应的是原始数据中最其实的序列输入。因为是反向RNN,在反向循环时,是会把序列中最后的放在最前面,所以反向网络的生成结果就会与最开始的序列相对应。
对于特征提取任务处理时,正向与反向的最后值都为该序列的特征,需要合并起来统一处理。但是对于下一个序列预测任务时,建议直接使用正向的RNN网络就可以了。
如果要获取双向RNN的结果,尤其是变长情况下,通过状态拿到值直接拼接起来才是正确的做法。即便不是变长。直接使用输出值来拼接,会损失掉反向的一部分特征结果。这是需要值得注意的地方。
代码:BiRNN输出
好了。在接着看下不带stack的函数输出是什么样子的
gbresult,state_fw=sess.run([Gbioutputs,Goutput_state_fw])
print("正向:\n", gbresult[0])
print("反向:\n", gbresult[1])
print('状态:',len(state_fw),'\n',state_fw[0],'\n',state_fw[1]) #state_fw[0]:【层,批次,cell个数】 重头到最后一个序列
print(state_fw[0][-1],state_fw[1][-1])
out = np.concatenate((state_fw[0][-1],state_fw[1][-1]),axis = 1)
print("拼接",out)
这次,在输出基本内容基础上,直接将结果拼接起来。上面代码运行后会输出如下内容。
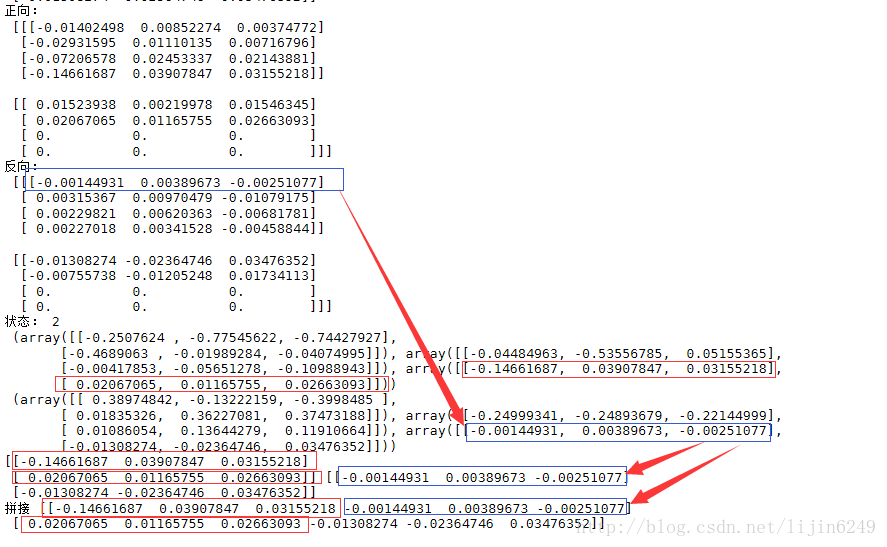
同样正向用红色,反向用蓝色。改函数返回的输出值,没有将正反向拼接。输出的状态虽然是一个值,但是里面有两个元素,一个代表正向状态,一个代表反向状态.
从输出中可以看到,最后一行实现了最终结果的真正拼接。在使用双向rnn时可以按照上面的例子代码将其状态拼接成一条完整输出,然后在进行处理。
代码:LSTM的双向RNN
类似的如果想使用LSTM cell。将前面的GRU部分替换即可,代码如下:
stacked_rnn = []
stacked_bw_rnn = []
for i in range(3):
stacked_rnn.append(tf.contrib.rnn.LSTMCell(3))
stacked_bw_rnn.append(tf.contrib.rnn.LSTMCell(3))
mcell = tf.contrib.rnn.MultiRNNCell(stacked_rnn)
mcell_bw = tf.contrib.rnn.MultiRNNCell(stacked_bw_rnn)
bioutputs, output_state_fw, output_state_bw = tf.contrib.rnn.stack_bidirectional_dynamic_rnn([mcell],[mcell_bw], X,sequence_length=seq_lengths,
dtype=tf.float64)
bioutputs, output_state_fw = tf.nn.bidirectional_dynamic_rnn(mcell,mcell_bw, X,sequence_length=seq_lengths,
dtype=tf.float64)
至于输出的内容是什么,可以按照前面GRU的输出部分显示出来自己观察。如何拼接,也可以参照GRU的例子来做。
通过将正反向的状态拼接起来才可以获得双向RNN的最终输出特征。千万不要直接拿着输出不加处理的来进行后续的运算,这会损失一大部分的运算特征。
该部分内容属于《深度学习之TensorFlow入门、原理与进阶实战》一书的内容补充。关于RNN的更多介绍可以参看书中第九章的详细内容。
我对双向RNN 的理解
1、双向RNN使用的场景:有些情况下,当前的输出不只依赖于之前的序列元素,还可能依赖之后的序列元素; 比如做完形填空,机器翻译等应用。
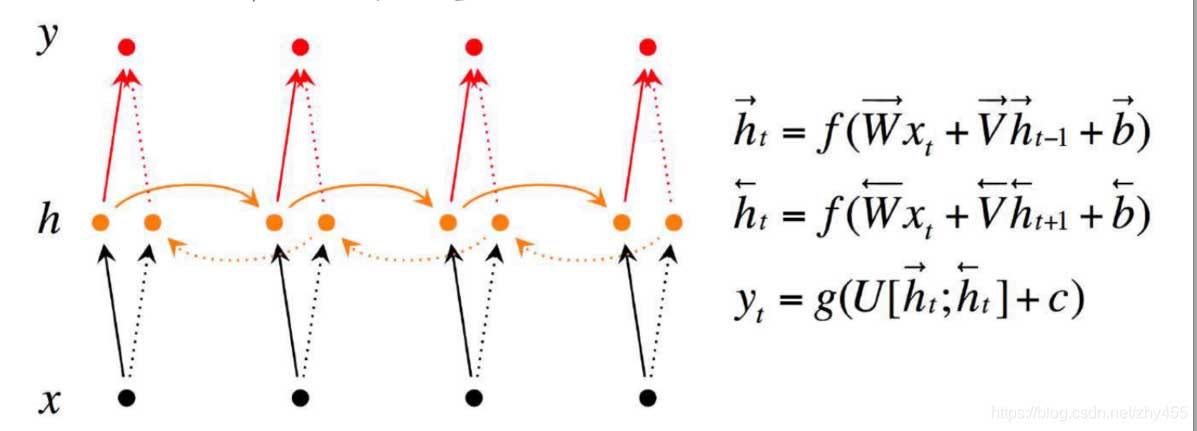
2、Tensorflow 中实现双向RNN 的API是:bidirectional_dynamic_rnn; 其本质主要是做了两次reverse:
第一次reverse:将输入序列进行reverse,然后送入dynamic_rnn做一次运算.
第二次reverse:将上面dynamic_rnn返回的outputs进行reverse,保证正向和反向输出的time是对上的.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Tensorflow与RNN、双向LSTM等的踩坑记录及解决
1.tensorflow(不定长)文本序列读取与解析 tensorflow读取csv时需要指定各列的数据类型. 但是对于RNN这种接受序列输入的模型来说,一条序列的长度是不固定.这时如果使用csv存储序列数据,应当首先将特征序列拼接成一列. 例如两条数据序列,第一项是标签,之后是特征序列 [0, 1.1, 1.2, 2.3] 转换成 [0, '1.1_1.2_2.3'] [1, 1.0, 2.5, 1.6, 3.2, 4.5] 转换成 [1, '1.0_2.5_1.6_3.2_4.5'] 这样每
-
双向RNN:bidirectional_dynamic_rnn()函数的使用详解
双向RNN:bidirectional_dynamic_rnn()函数的使用详解 先说下为什么要使用到双向RNN,在读一篇文章的时候,上文提到的信息十分的重要,但这些信息是不足以捕捉文章信息的,下文隐含的信息同样会对该时刻的语义产生影响. 举一个不太恰当的例子,某次工作会议上,领导进行"简洁地"总结,他会在第一句告诉你:"下面,为了节约时间,我简单地说两点-",(-此处略去五百字-),"首先,-.",(-此处略去一万字-),"碍于时间的
-
浅谈Tensorflow 动态双向RNN的输出问题
tf.nn.bidirectional_dynamic_rnn() 函数: def bidirectional_dynamic_rnn( cell_fw, # 前向RNN cell_bw, # 后向RNN inputs, # 输入 sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度) initial_state_fw=None, # 前向的初始化状态(可选) initial_state_bw=None, # 后向的初始化状态(可选) dtype=No
-
变长双向rnn的正确使用姿势教学
如何使用双向RNN 在<深度学习之TensorFlow入门.原理与进阶实战>一书的9.4.2中的第4小节中,介绍过变长动态RNN的实现. 这里在来延伸的讲解一下双向动态rnn在处理变长序列时的应用.其实双向RNN的使用中,有一个隐含的注意事项,非常容易犯错. 本文就在介绍下双向RNN的常用函数.用法及注意事项. 动态双向rnn有两个函数: stack_bidirectional_dynamic_rnn bidirectional_dynamic_rnn 二者的实现上大同小异,放置的位置也不一样
-
解决pytorch rnn 变长输入序列的问题
pytorch实现变长输入的rnn分类 输入数据是长度不固定的序列数据,主要讲解两个部分 1.Data.DataLoader的collate_fn用法,以及按batch进行padding数据 2.pack_padded_sequence和pad_packed_sequence来处理变长序列 collate_fn Dataloader的collate_fn参数,定义数据处理和合并成batch的方式. 由于pack_padded_sequence用到的tensor必须按照长度从大到小排过序的,所以在
-
详解Java日志正确使用姿势
前言 关于日志,在大家的印象中都是比较简单的,只须引入了相关依赖包,剩下的事情就是在项目中"尽情"的打印我们需要的信息了.但是往往越简单的东西越容易让我们忽视,从而导致一些不该有的bug发生,作为一名严谨的程序员,怎么能让这种事情发生呢?所以下面我们就来了解一下关于日志的那些正确使用姿势. 正文 日志规范 命名 首先是日志文件的命名,尽量要做到见名知意,团队里面也必须使用统一的命名规范,不然"脏乱差"的日志文件会影响大家排查问题的效率.这里推荐以"proj
-
keras在构建LSTM模型时对变长序列的处理操作
我就废话不多说了,大家还是直接看代码吧~ print(np.shape(X))#(1920, 45, 20) X=sequence.pad_sequences(X, maxlen=100, padding='post') print(np.shape(X))#(1920, 100, 20) model = Sequential() model.add(Masking(mask_value=0,input_shape=(100,20))) model.add(LSTM(128,dropout_W=
-
IDEA中JetBrains Mono字体的正确安装姿势
Intellij IDEA 公司 JetBrains 推出了一种新字体:JetBrains Mono,它是专为开发人员设计的.为什么说它是专门为开发人员设计的呢?因为当前流行使用的各种字体,并未考虑到在代码开发阅读时的美观舒适,往往一天下来,聚精会神的你两眼难免会干涩难受.因此,在 JetBrains Mono 的设计阶段,它就充分考虑到了长时间工作可能导致的眼睛疲劳问题,比如字母的大小和形状.空间量.自然等宽平衡.不必要的细节.连字.以及难以区分的符号等,从而最终设计出了这么一款字体. 概览
-
vue3中element-plus icon图标的正确使用姿势
目录 前言: 改变: 错误使用: 正确使用: setup script扩展 更新 总结 前言: 为了适应vue3的更新,element组件也将其内容升级为了plus用以配套的使用,很多组件新增了更加多元的功能,但我用的时候就觉得那个icon图标,怎么变得特别难用呢?原来是没有掌握正确的使用方法 改变: // 原来 <i class="el-icon-edit"></i> // plus <el-icon :size="size" :co
-
一文了解Java 线程池的正确使用姿势
目录 概述 线程池介绍 线程池创建 ThreadPoolExecutor创建 Executors创建 newFixedThreadPool newCachedThreadPool newSingleThreadExecutor newScheduledThreadPool newWorkStealingPool 线程池关键API和例子 提交执行任务API 关闭线程池API 线程池监控API 扩展API 使用注意事项 概述 线程池在平时的工作中出场率非常高,基本大家多多少少都要了解过,可能不是很全
-
oracle中变长数组varray,嵌套表,集合使用方法
创建变长数组类型 CREATE TYPE varray_type AS VARRAY(2) OF VARCHAR2(50); 这个变长数组最多可以容纳两个数据,数据的类型为 varchar2(50) 更改元素类型的大小或精度 可以更改变长数组类型和嵌套表类型 元素的大小. ALTER TYPE varray_type MODIFY ELEMENT TYPE varchar2(100) CASCADE; CASCADE选项吧更改传播到数据库中的以来对象.也可以用 INVALIDATE 选项使依赖对