Pytorch GPU内存占用很高,但是利用率很低如何解决
1.GPU 占用率,利用率
输入nvidia-smi来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util)
GPU内存占用率(Memory-Usage) 往往是由于模型的大小以及batch size的大小,来影响这个指标 显卡的GPU利用率(GPU-util) 往往跟代码有关,有更多的io运算,cpu运算就会导致利用率变低。
比如打印loss, 输出图像,等等
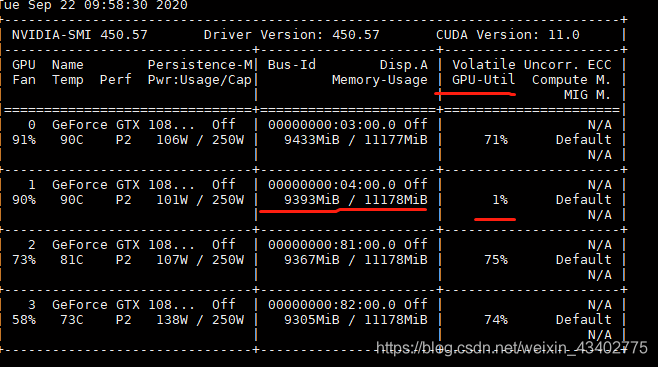
这个时候发现,有一块卡的利用率经常跳到1%,而其他三块卡经常维持在70%以上
2.原因分析
当没有设置好CPU的线程数时,Volatile GPU-Util参数是在反复的跳动的,0%,20%,70%,95%,0%。
这样停息1-2 秒然后又重复起来。其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐起计算来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。
因此,这个GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。
最好当然就是换更好的四代或者更强大的内存条,配合更好的CPU。
3.解决方法:
(1)为了提高利用率,首先要将num_workers(线程数)设置得体,4,8,16是几个常选的几个参数。本人测试过,将num_workers设置的非常大,例如,24,32,等,其效率反而降低,因为模型需要将数据平均分配到几个子线程去进行预处理,分发等数据操作,设高了反而影响效率。当然,线程数设置为1,是单个CPU来进行数据的预处理和传输给GPU,效率也会低。其次,当你的服务器或者电脑的内存较大,性能较好的时候,建议打开pin_memory打开,就省掉了将数据从CPU传入到缓存RAM里面,再给传输到GPU上;为True时是直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
(2) 另外的一个方法是,在PyTorch这个框架里面,数据加载Dataloader上做更改和优化,包括num_workers(线程数),pin_memory,会提升速度。解决好数据传输的带宽瓶颈和GPU的运算效率低的问题。在TensorFlow下面,也有这个加载数据的设置。
(3) 修改代码(我遇到的问题)
每个iteration 都写文件了,这个就会导致cpu 一直运算,GPU 等待

造成GPU利用率低还有其他原因
1. CPU数据读取更不上:读到内存+多线程+二进制文件(比如tf record)
2. GPU温度过高,使用功率太大:每次少用几个GPU,降低功耗(但是多卡的作用何在?)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pytorch GPU显存充足却显示out of memory的解决方式
今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorch版本的问题,原来我的pytorch版本是0.4.1,于是我就把这个版本卸载,然后安装了pytorch1.1.0,程序就可以神奇的运行了,不会再有OOM的提示了.虽然具体原因还不知道为何,这里还是先mark一下,具体过程如下: 卸载旧版本pytorch: conda uninstall pyt
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代
-
pytorch 限制GPU使用效率详解(计算效率)
问题 用过 tensorflow 的人都知道, tf 可以限制程序在 GPU 中的使用效率,但 pytorch 中没有这个操作. 思路 于是我想到了一个代替方法,玩过单片机点灯的同学都知道,灯的亮度是靠占空比实现的,这实际上也是计算机的运行原理. 那我们是不是也可以通过增加 GPU 不工作的时间,进而降低 GPU 的使用效率 ? 主要代码 import time ... rest_time = 0.15 ... for _ in range( XXX ): ... outputs = all_G
-

Pytorch GPU内存占用很高,但是利用率很低如何解决
1.GPU 占用率,利用率 输入nvidia-smi来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util) GPU内存占用率(Memory-Usage) 往往是由于模型的大小以及batch size的大小,来影响这个指标 显卡的GPU利用率(GPU-util) 往往跟代码有关,有更多的io运算,cpu运算就会导致利用率变低. 比如打印loss, 输出图像,等等 这个时候发现,有一块卡的利用率经常跳到1%,而其他三块卡经常维持在70%以上 2.原因分析 当
-
Mysql5.6启动内存占用过高解决方案
vps的内存为512M,安装好nginx,php等启动起来,mysql死活启动不起来看了日志只看到对应pid被结束了,后跟踪看发现是内存不足被killed; 调整my.cnf 参数,重新配置(系统默认配置太高直接占用400M内存,小玩家玩不起呢)即可 performance_schema_max_table_instances=200 table_definition_cache=200 table_open_cache=128 下面附一个相关的my.cnf配置文件的说明 [client] po
-
NodeJs内存占用过高的排查实战记录
前言 一次线上容器扩容引发的排查,虽然最后查出并不是真正的 OOM 引起的,但还是总结记录一下其中的排查过程,整个过程像是破案,一步步寻找蛛丝马迹,一步步验证出结果. 做这件事的意义和必要性个人觉得有这么几个方面吧: 从程序员角度讲:追求代码极致,不放过问题,务必保证业务的稳定性这几个方面 从资源角度讲:就是为了降低无意义的资源开销 从公司角度讲:降低服务器成本,给公司省钱 环境:腾讯 Taf 平台上运行的 NodeJs 服务. 问题起因 最开始是因为一个定时功能上线后,线上的容器自动进行了扩容
-
w3wp.exe内存占用过高(网站打不开,应用程序池回收就正常)
服务器cpu,内存正常, 部分网站打不开,应用程序池回收就正常,如何解决? 提问: 服务器\IIS和ASP问题请问下各位``网站最近每天要出现几次打不开很慢`只显示tile标题其它无,站点是ASP的,前台生成的html,今天看到的W3WP.exe占用最高达280M,一般都只有170M左右IIS管理里地址池回收一下就正常`是什么原因? 补充:服务器CPU占用极少`只有百分几点物理内存6G 内存占用量也极少.PS:主要问题就是这个程序池.网站出现慢或打不开,一回收就正常. WEB服务器高手--们在哪
-
Linux 查看磁盘IO并找出占用IO读写很高的进程
背景-线上告警 线上一台服务器告警,磁盘利用率 disk.util > 90,并持续告警. 登录该服务器后通过iostat -x 1 10查看了相关磁盘使用信息.相关截图如下: # 如果没有 iostat 命令,那么使用 yum install sysstat 进行安装 # iostat -x 1 10 由上图可知,vdb磁盘的 %util[IO]几乎都在100%,原因是频繁的读取数据造成的. 其他字段说明 Device:设备名称 tps:每秒的IO读.写请求数量,多个逻辑请求可以组合成对设备的
-
w3wp.exe占用CPU和内存问题过高的解决方法
今天研究了一下,可以做以下配置: 1.在IIS中对每个网站进行单独的应用程序池配置.即互相之间不影响. 2.设置应用程序池的回收时间,默认为1720小时,可以根据情况修改.同时,设置同时运行的w3wp进程数目为1.再设置当内存或者cpu占用超过多少,就自动回收内存 一般来说,这样就可以解决了.但仍然会出现个别网站因为程序问题,不能正确释放. 那么,怎么样才能找到是哪一个网站的? 1.在任务管理器中增加显示pid字段.就可以看到占用内存或者cpu最高的进程pid 2.在命令提示符下运行iisapp
-
在windows下揪出java程序占用cpu很高的线程并完美解决
我的一个java程序偶尔会出现cpu占用很高的情况 一直不知道什么原因 今天终于抽时间解决了 系统是win2003 jvisualvm 和 jconsole貌似都只能看到总共占用的cpu 看不到每个线程分别占用的cpu呢所以在windows平台上要找出到底是哪个线程占用的cpu还不那么容易,linux用top就简单多了 最后的解决方法: 1.找到java进程对应的pid. 找pid的方法是:打开任务管理器,然后点击 "查看" 菜单,然后点击 "选择列",把pid勾上
-
Mysql占用过高CPU时的优化手段(必看)
Mysql占用CPU过高的时候,该从哪些方面下手进行优化? 占用CPU过高,可以做如下考虑: 1)一般来讲,排除高并发的因素,还是要找到导致你CPU过高的哪几条在执行的SQL,show processlist语句,查找负荷最重的SQL语句,优化该SQL,比如适当建立某字段的索引: 2)打开慢查询日志,将那些执行时间过长且占用资源过多的SQL拿来进行explain分析,导致CPU过高,多数是GroupBy.OrderBy排序问题所导致,然后慢慢进行优化改进.比如优化insert语句.优化group