Pytorch中的backward()多个loss函数用法
Pytorch的backward()函数
假若有多个loss函数,如何进行反向传播和更新呢?
x = torch.tensor(2.0, requires_grad=True) y = x**2 z = x # 反向传播 y.backward() x.grad tensor(4.) z.backward() x.grad tensor(5.) ## 累加
补充:Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析
backward函数
官方定义:
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)
Computes the sum of gradients of given tensors w.r.t. graph leaves.The graph is differentiated using the chain rule. If any of tensors are non-scalar (i.e. their data has more than one element) and require gradient, the function additionally requires specifying grad_tensors. It should be a sequence of matching length, that contains gradient of the differentiated function w.r.t. corresponding tensors (None is an acceptable value for all tensors that don't need gradient tensors). This function accumulates gradients in the leaves - you might need to zero them before calling it.
翻译和解释:
参数tensors如果是标量,函数backward计算参数tensors对于给定图叶子节点的梯度( graph leaves,即为设置requires_grad=True的变量)。
参数tensors如果不是标量,需要另外指定参数grad_tensors,参数grad_tensors必须和参数tensors的长度相同。在这一种情况下,backward实际上实现的是代价函数(loss = torch.sum(tensors*grad_tensors); 注:torch中向量*向量实际上是点积,因此tensors和grad_tensors的维度必须一致 )关于叶子节点的梯度计算,而不是参数tensors对于给定图叶子节点的梯度。如果指定参数grad_tensors=torch.ones((size(tensors))),显而易见,代价函数关于叶子节点的梯度,也就等于参数tensors对于给定图叶子节点的梯度。
每次backward之前,需要注意叶子梯度节点是否清零,如果没有清零,第二次backward会累计上一次的梯度。
下面给出具体的例子:
import torch x=torch.randn((3),dtype=torch.float32,requires_grad=True) y = torch.randn((3),dtype=torch.float32,requires_grad=True) z = torch.randn((3),dtype=torch.float32,requires_grad=True) t = x + y loss = t.dot(z) #求向量的内积
在调用 backward 之前,可以先手动求一下导数,应该是:
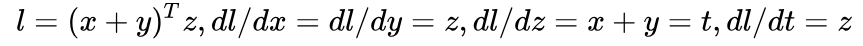
用代码实现求导:
loss.backward(retain_graph=True) print(z,x.grad,y.grad) #预期打印出的结果都一样 print(t,z.grad) #预期打印出的结果都一样 print(t.grad) #在这个例子中,x,y,z就是叶子节点,而t不是,t的导数在backward的过程中求出来回传之后就会被释放,因而预期结果是None
结果和预期一致:
tensor([-2.6752, 0.2306, -0.8356], requires_grad=True) tensor([-2.6752, 0.2306, -0.8356]) tensor([-2.6752, 0.2306, -0.8356])
tensor([-1.1916, -0.0156, 0.8952], grad_fn=<AddBackward0>) tensor([-1.1916, -0.0156, 0.8952]) None
敲重点:
注意到前面函数的解释中,在参数tensors不是标量的情况下,tensor.backward(grad_tensors)实现的是代价函数(torch.sum(tensors*grad_tensors))关于叶子节点的导数。
在上面例子中,loss = t.dot(z),因此用t.backward(z),实现的就是loss对于所有叶子结点的求导,实际运算结果和预期吻合。
t.backward(z,retain_graph=True) print(z,x.grad,y.grad) print(t,z.grad)
运行结果如下:
tensor([-0.7830, 1.4468, 1.2440], requires_grad=True) tensor([-0.7830, 1.4468, 1.2440]) tensor([-0.7830, 1.4468, 1.2440])
tensor([-0.7145, -0.7598, 2.0756], grad_fn=<AddBackward0>) None
上面的结果中,出现了一个问题,虽然loss关于x和y的导数正确,但是z不再是叶子节点了。
问题1:
当使用t.backward(z,retain_graph=True)的时候, print(z.grad)结果是None,这意味着z不再是叶子节点,这是为什么呢?
另外一个尝试,loss = t.dot(z)=z.dot(t),但是如果用z.backward(t)替换t.backward(z,retain_graph=True),结果却不同。
z.backward(t) print(z,x.grad,y.grad) print(t,z.grad)
运行结果:
tensor([-1.0716, -1.3643, -0.0016], requires_grad=True) None None
tensor([-0.7324, 0.9763, -0.4036], grad_fn=<AddBackward0>) tensor([-0.7324, 0.9763, -0.4036])
问题2:
上面的结果中可以看到,使用z.backward(t),x和y都不再是叶子节点了,z仍然是叶子节点,且得到的loss相对于z的导数正确。
上述仿真出现的两个问题,我还不能解释,希望和大家交流。
问题1:
当使用t.backward(z,retain_graph=True)的时候, print(z.grad)结果是None,这意味着z不再是叶子节点,这是为什么呢?
问题2:
上面的结果中可以看到,使用z.backward(t),x和y都不再是叶子节点了,z仍然是叶子节点,且得到的loss相对于z的导数正确。
另外强调一下,每次backward之前,需要注意叶子梯度节点是否清零,如果没有清零,第二次backward会累计上一次的梯度。
简单的代码可以看出:
#测试1,:对比上两次单独执行backward,此处连续执行两次backward t.backward(z,retain_graph=True) print(z,x.grad,y.grad) print(t,z.grad) z.backward(t) print(z,x.grad,y.grad) print(t,z.grad) # 结果x.grad,y.grad本应该是None,因为保留了第一次backward的结果而打印出上一次梯度的结果 tensor([-0.5590, -1.4094, -1.5367], requires_grad=True) tensor([-0.5590, -1.4094, -1.5367]) tensor([-0.5590, -1.4094, -1.5367])tensor([-1.7914, 0.8761, -0.3462], grad_fn=<AddBackward0>) Nonetensor([-0.5590, -1.4094, -1.5367], requires_grad=True) tensor([-0.5590, -1.4094, -1.5367]) tensor([-0.5590, -1.4094, -1.5367])tensor([-1.7914, 0.8761, -0.3462], grad_fn=<AddBackward0>) tensor([-1.7914, 0.8761, -0.3462])
#测试2,:连续执行两次backward,并且清零,可以验证第二次backward没有计算x和y的梯度 t.backward(z,retain_graph=True) print(z,x.grad,y.grad) print(t,z.grad) x.grad.data.zero_() y.grad.data.zero_() z.backward(t) print(z,x.grad,y.grad) print(t,z.grad) tensor([ 0.8671, 0.6503, -1.6643], requires_grad=True) tensor([ 0.8671, 0.6503, -1.6643]) tensor([ 0.8671, 0.6503, -1.6643])tensor([1.6231e+00, 1.3842e+00, 4.6492e-06], grad_fn=<AddBackward0>) Nonetensor([ 0.8671, 0.6503, -1.6643], requires_grad=True) tensor([0., 0., 0.]) tensor([0., 0., 0.])tensor([1.6231e+00, 1.3842e+00, 4.6492e-06], grad_fn=<AddBackward0>) tensor([1.6231e+00, 1.3842e+00, 4.6492e-06])
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

pytorch loss反向传播出错的解决方案
今天在使用pytorch进行训练,在运行 loss.backward() 误差反向传播时出错 : RuntimeError: grad can be implicitly created only for scalar outputs File "train.py", line 143, in train loss.backward() File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", li
-
Pytorch训练网络过程中loss突然变为0的解决方案
问题 // loss 突然变成0 python train.py -b=8 INFO: Using device cpu INFO: Network: 1 input channels 7 output channels (classes) Bilinear upscaling INFO: Creating dataset with 868 examples INFO: Starting training: Epochs: 5 Batch size: 8 Learning rate: 0.001
-
PyTorch梯度裁剪避免训练loss nan的操作
近来在训练检测网络的时候会出现loss为nan的情况,需要中断重新训练,会很麻烦.因而选择使用PyTorch提供的梯度裁剪库来对模型训练过程中的梯度范围进行限制,修改之后,不再出现loss为nan的情况. PyTorch中采用torch.nn.utils.clip_grad_norm_来实现梯度裁剪,链接如下: https://pytorch.org/docs/stable/_modules/torch/nn/utils/clip_grad.html 训练代码使用示例如下: from torch
-
pytorch MSELoss计算平均的实现方法
给定损失函数的输入y,pred,shape均为bxc. 若设定loss_fn = torch.nn.MSELoss(reduction='mean'),最终的输出值其实是(y - pred)每个元素数字的平方之和除以(bxc),也就是在batch和特征维度上都取了平均. 如果只想在batch上做平均,可以这样写: loss_fn = torch.nn.MSELoss(reduction='sum') loss = loss_fn(pred, y) / pred.size(0) 补充:PyTorc
-
Pytorch损失函数nn.NLLLoss2d()用法说明
最近做显著星检测用到了NLL损失函数 对于NLL函数,需要自己计算log和softmax的概率值,然后从才能作为输入 输入 [batch_size, channel , h, w] 目标 [batch_size, h, w] 输入的目标矩阵,每个像素必须是类型.举个例子.第一个像素是0,代表着类别属于输入的第1个通道:第二个像素是0,代表着类别属于输入的第0个通道,以此类推. x = Variable(torch.Tensor([[[1, 2, 1], [2, 2, 1], [0, 1, 1]]
-
pytorch使用tensorboardX进行loss可视化实例
最近pytorch出了visdom,也没有怎么去研究它,主要是觉得tensorboardX已经够用,而且用起来也十分的简单 pip install tensorboardX 然后在代码里导入 from tensorboardX import SummaryWriter 然后声明一下自己将loss写到哪个路径下面 writer = SummaryWriter('./log') 然后就可以愉快的写loss到你得这个writer了 niter = epoch * len(train_loader) +
-
Pytorch BCELoss和BCEWithLogitsLoss的使用
BCELoss 在图片多标签分类时,如果3张图片分3类,会输出一个3*3的矩阵. 先用Sigmoid给这些值都搞到0~1之间: 假设Target是: 下面我们用BCELoss来验证一下Loss是不是0.7194! emmm应该是我上面每次都保留4位小数,算到最后误差越来越大差了0.0001.不过也很厉害啦哈哈哈哈哈! BCEWithLogitsLoss BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步.我们直接用刚刚的input验证一下是不是0.7193: 嘻嘻,我
-
Pytorch中的backward()多个loss函数用法
Pytorch的backward()函数 假若有多个loss函数,如何进行反向传播和更新呢? x = torch.tensor(2.0, requires_grad=True) y = x**2 z = x # 反向传播 y.backward() x.grad tensor(4.) z.backward() x.grad tensor(5.) ## 累加 补充:Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析 backward函数 官方定义
-
pytorch中torch.max和Tensor.view函数用法详解
torch.max() 1. torch.max()简单来说是返回一个tensor中的最大值. 例如: >>> si=torch.randn(4,5) >>> print(si) tensor([[ 1.1659, -1.5195, 0.0455, 1.7610, -0.2064], [-0.3443, 2.0483, 0.6303, 0.9475, 0.4364], [-1.5268, -1.0833, 1.6847, 0.0145, -0.2088], [-0.86
-
pytorch中tensor.expand()和tensor.expand_as()函数详解
tensor.expend()函数 >>> import torch >>> a=torch.tensor([[2],[3],[4]]) >>> print(a.size()) torch.Size([3, 1]) >>> a.expand(3,2) tensor([[2, 2], [3, 3], [4, 4]]) >>> a tensor([[2], [3], [4]]) 可以看出expand()函数括号里面为变形
-
浅谈pytorch中torch.max和F.softmax函数的维度解释
在利用torch.max函数和F.Ssoftmax函数时,对应该设置什么维度,总是有点懵,遂总结一下: 首先看看二维tensor的函数的例子: import torch import torch.nn.functional as F input = torch.randn(3,4) print(input) tensor([[-0.5526, -0.0194, 2.1469, -0.2567], [-0.3337, -0.9229, 0.0376, -0.0801], [ 1.4721, 0.1
-
pytorch中的nn.ZeroPad2d()零填充函数实例详解
在卷积神经网络中,有使用设置padding的参数,配合卷积步长,可以使得卷积后的特征图尺寸大小不发生改变,那么在手动实现图片或特征图的边界零填充时,常用的函数是nn.ZeroPad2d(),可以指定tensor的四个方向上的填充,比如左边添加1dim.右边添加2dim.上边添加3dim.下边添加4dim,即指定paddin参数为(1,2,3,4),本文中代码设置的是(3,4,5,6)如下: import torch.nn as nn import cv2 import torchvision f
-
Keras之自定义损失(loss)函数用法说明
在Keras中可以自定义损失函数,在自定义损失函数的过程中需要注意的一点是,损失函数的参数形式,这一点在Keras中是固定的,须如下形式: def my_loss(y_true, y_pred): # y_true: True labels. TensorFlow/Theano tensor # y_pred: Predictions. TensorFlow/Theano tensor of the same shape as y_true . . . return scalar #返回一个标量
-
python中map、any、all函数用法分析
本文实例讲述了python中map.any.all函数用法.分享给大家供大家参考.具体分析如下: 最近想学python,就一直比较关注python,昨天在python吧看到有个帖子提问怎么在python中怎么判断密码是否符合规范,回帖中有很多用循环的,除此外还有一个没有用循环,代码非常简练,下面是代码: def volid(pwd): a = any(map(str.isupper,pwd)) b = any(map(str.islower,pwd)) c = any(map(str.isdig
-
php中current、next与reset函数用法实例
本文实例讲述了php中current.next与reset函数用法.分享给大家供大家参考. 具体代码如下: 复制代码 代码如下: $array=array('step one','step two','step three','step four'); //定义一个数组 echo current($array)."<br/>n"; //返回数组第一个元素 next($array); //数组指针后移一位 next($array);
-
php中debug_backtrace、debug_print_backtrace和匿名函数用法实例
本文实例讲述了php中debug_backtrace.debug_print_backtrace和匿名函数用法.分享给大家供大家参考.具体分析如下: debug_print_backtrace() 是一个很低调的函数,很少有人注意过它. 不过当我们对着一个对象调用另一个对象再调用其它的对象和文件中的一个函数出错时,它正在一边笑呢. debug_print_backtrace() 可以打印出一个页面的调用过程,从哪儿来到哪儿去一目了然.不过这是一个PHP5的专有函数,好在pear中已经有了实现.
-
Pytorch中torch.nn.Softmax的dim参数用法说明
Pytorch中torch.nn.Softmax的dim参数使用含义 涉及到多维tensor时,对softmax的参数dim总是很迷,下面用一个例子说明 import torch.nn as nn m = nn.Softmax(dim=0) n = nn.Softmax(dim=1) k = nn.Softmax(dim=2) input = torch.randn(2, 2, 3) print(input) print(m(input)) print(n(input)) print(k(inp