postgreSQL数据库 实现向表中快速插入1000000条数据
不用创建函数,直接向表中快速插入1000000条数据
create table tbl_test (id int, info text, c_time timestamp); insert into tbl_test select generate_series(1,100000),md5(random()::text),clock_timestamp(); select count(id) from tbl_test; --查看个数据条数
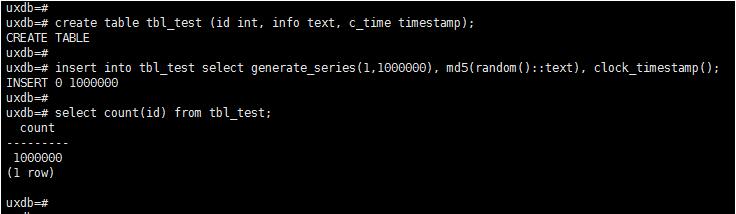
补充:postgreSQL 批量插入10000条数据 ,生成随机字母随机数
啥也不说了,看代码吧~
--随机字母 select chr(int4(random()*26)+65); --随机4位字母 select repeat( chr(int4(random()*26)+65),4); --随机数字 十位不超过6的两位数 select (random()*(6^2))::integer; --三位数 select (random()*(10^3))::integer; insert into t_test SELECT generate_series(1,10000) as key,repeat( chr(int4(random()*26)+65),4), (random()*(6^2))::integer,null,(random()*(10^4))::integer;
10000条数据完成,开始测试吧
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python操作PostgreSql数据库的方法(基本的增删改查)
Python操作PostgreSql数据库(基本的增删改查) 操作数据库最快的方式当然是直接用使用SQL语言直接对数据库进行操作,但是偶尔我们也会碰到在代码中操作数据库的情况,我们可能用ORM类的库对数控库进行操作,但是当需要操作大量的数据时,ORM的数据显的太慢了.在python中,遇到这样的情况,我推荐使用psycopg2操作postgresql数据库 psycopg2 官方文档传送门: http://initd.org/psycopg/docs/index.html 简单的增删改查 连接
-
查看postgresql数据库用户系统权限、对象权限的方法
PostgreSQL简介 PostgreSQL是一种特性非常齐全的自由软件的对象-关系型数据库管理系统(ORDBMS),是以加州大学计算机系开发的POSTGRES,4.2版本为基础的对象关系型数据库管理系统.POSTGRES的许多领先概念只是在比较迟的时候才出现在商业网站数据库中.PostgreSQL支持大部分的SQL标准并且提供了很多其他现代特性,如复杂查询.外键.触发器.视图.事务完整性.多版本并发控制等.同样,PostgreSQL也可以用许多方法扩展,例如通过增加新的数据类型.函数.操作符
-

postgresql插入后返回id的操作
如下所示: 补充:PostgreSQL中执行insert同时返回插入的那行数据 通过使用语句: INSERT INTO tab1 ... RETURNING *; 以上这篇postgresql插入后返回id的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
基于postgresql行级锁for update测试
创建表: CREATE TABLE db_user ( id character varying(50) NOT NULL, age integer, name character varying(100), roleid character varying, CONSTRAINT db_user_pkey PRIMARY KEY (id) ) 随便插入几条数据即可. 一.不加锁演示 1.打开一个postgreSQL的SQL Shell或pgAdmin的SQL编辑器窗口,执行: begin; s
-
postgresql 实现数据的导入导出
最近想把服务器上的测试数据库数据导到我本地的电脑上,本地电脑数据库是安装在windows系统下 之前没使用过pgsql,网上找了点资料,记入如下: 一,首先把服务器上的数据进行备份 pg_dump -U 用户名 数据库名 (-t 表名)> 数据存放路径 二,把.sql 文件下载到本地之后,首先切换到pgsql路径下的bin目录 然后执行这条命令: -d:数据库名 -h:地址 -p:端口 -u:用户名 -f:sql文件路径 之后输入口令: 这样就可以了! 补充:Sqoop从PostgreSQL导入
-
postgreSql分组统计数据的实现代码
1. 背景 比如气象台的气温监控,每半小时上报一条数据,有很多个地方的气温监控,这样数据表里就会有很多地方的不同时间的气温数据 2. 需求: 每次查询只查最新的气温数据按照不同的温度区间来分组查出,比如:高温有多少地方,正常有多少地方,低温有多少地方 3. 构建数据 3.1 创建表结构: -- DROP TABLE public.t_temperature CREATE TABLE public.t_temperature ( id int4 NOT NULL GENERATED ALWAYS
-
Postgresql锁机制详解(表锁和行锁)
表锁 LOCK [ TABLE ] [ ONLY ] name [ * ] [, ...] [ IN lockmode MODE ] [ NOWAIT ] lockmode包括以下几种: ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE LOCK TABLE命令用于获取一个表锁,获取过程将阻塞一直
-
PostgreSQL function返回多行的操作
1. 建表 postgres=# create table tb1(id integer,name character varying); CREATE TABLE postgres=# postgres=# insert into tb1 select generate_series(1,5),'aa'; INSERT 0 5 2. 返回单字段的多行(returns setof datatype) 不指定out参数,使用return next xx: create or replace fun
-
postgreSQL数据库 实现向表中快速插入1000000条数据
不用创建函数,直接向表中快速插入1000000条数据 create table tbl_test (id int, info text, c_time timestamp); insert into tbl_test select generate_series(1,100000),md5(random()::text),clock_timestamp(); select count(id) from tbl_test; --查看个数据条数 补充:postgreSQL 批量插入10000条数据
-
Mysql快速插入千万条数据的实战教程
一.创建数据库 二.创建表 1.创建 dept表 CREATE TABLE `dept` ( `id` int(11) NOT NULL, `deptno` mediumint(9) DEFAULT NULL, `dname` varchar(20) DEFAULT NULL, `loc` varchar(13) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 2.创建emp表 CREATE TABLE
-
mysql 一次向表中插入多条数据实例讲解
mysql一次插入多条数据: INSERT INTO hk_test(username, passwd) VALUES ('qmf2', 'qmf2'),('qmf3', 'qmf3'),('qmf4', 'qmf4'),('qmf5', 'qmf5') GO 我们先来创建一种表Authors: CREATE TABLE Authors( AuthID SMALLINT NOT NULL PRIMARY KEY, AuthFN VARCHAR(20), AuthMN VARCHAR(20), A
-
mysql中迅速插入百万条测试数据的方法
对比一下,首先是用 mysql 的存储过程弄的: 复制代码 代码如下: mysql>delimiter $ mysql>SET AUTOCOMMIT = 0$$ mysql> create procedure test() begin declare i decimal (10) default 0 ; dd:loop INSERT INTO `million` (`categ_id`, `categ_fid`, `SortPath`, `address`, `p_identifier`
-
如何利用insert into values插入多条数据
目录 insert into values插入多条数据 SQL insert into插入的单行,多行的情况 insert into values插入多条数据 insert into 表名(字段名1,字段名2)values(值a1,值b1), (值a2,值b2), 例如: insert into user_info (user_account,user_name,user_age,user_class) values ('00001', '张三 ','20','计算机系'), ('00002',
-
PHP使用PDO创建MySQL数据库、表及插入多条数据操作示例
本文实例讲述了PHP使用PDO创建MySQL数据库.表及插入多条数据操作.分享给大家供大家参考,具体如下: 创建 MySQL 数据库: <?php $servername = "localhost"; $username = "username"; $password = "password"; try { $conn = new PDO("mysql:host=$servername", $username, $pas
-
MySQL如何快速批量插入1000w条数据
听说有个面试题是: 如何快速向mysql中插入1000w条数据? 我私下试了一下, 发现插入10000条数据用了0.9s, 插入10w条数据用了4.7s, 插入100w条数据用了58s左右,1000w条数据,我的笔记本吭哧了5分钟,自己停了, 心中1000w只草泥马呼啸而过,我用的是下面的代码: -- 进入数据库 use test; -- 显示所有表 show tables; -- 创建majors表 create table majors(id int, major varchar(255))
-
oracle取数据库中最新的一条数据可能会遇到的bug(两种情况)
记一次 开发中遇到的坑: 第一种情况 rowid select * from table where rowid=(select max(rowid) from table ) 这种方式是取最大的rowid作为最新的数据,但是有一个隐患 :数据库一旦有删除操作,rowid不能保证每次都是递增的!即max(rowid)并不一定就是最新的数据,尽管可能不会每次复现 但这个问题是绝对存在的! 第二种情况 使用rownum (或相同思路) select t.* from (select ti.sysno
-
MySQL数据库10秒内插入百万条数据的实现
首先我们思考一个问题: 要插入如此庞大的数据到数据库,正常情况一定会频繁地进行访问,什么样的机器设备都吃不消.那么如何避免频繁访问数据库,能否做到一次访问,再执行呢? Java其实已经给了我们答案. 这里就要用到两个关键对象:Statement.PrepareStatement 我们来看一下二者的特性: 要用到的BaseDao工具类 (jar包 / Maven依赖) (Maven依赖代码附在文末)(封装以便于使用) 注:(重点)rewriteBatchedStatements=true,一次插入
-
Python中elasticsearch插入和更新数据的实现方法
首先,我的索引结构是酱紫的. 存储以name_id为主键的索引,待插入或更新数据为: 一般会有有两种操作: 以下图片为个人见解,我没试过能不能直接运行,但形式上没错. 数据不存在,我需要插入地址为空字符串. 单条插入: 批量插入: 该数据存在,我需要更新地址字段为空字符串. 单条更新: 批量更新: 总结 以上所述是小编给大家介绍的Python中elasticsearch插入和更新数据的实现方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的! 您可能感兴趣的文章: 使用