postgresql 实现取出分组中最大的几条数据
看代码吧~
WITH Name AS (
SELECT
*
FROM
(
SELECT
xzqdm,
SUBSTRING (zldwdm, 1, 9) xzdm,
COUNT (*) sl
FROM
sddltb_qc
WHERE
xzqdm IN ('130432', '210604')
GROUP BY
xzqdm,
SUBSTRING (zldwdm, 1, 9)
) AS A
ORDER BY
xzqdm,
xzdm,
sl
) SELECT
xzqdm,
xzdm,
sl
FROM
(
SELECT
*, ROW_NUMBER () OVER (
PARTITION BY xzqdm
ORDER BY
sl DESC
) AS Row_ID
FROM
Name
) AS A
WHERE
Row_ID <= 2
ORDER BY
xzqdm
其中
select * from (select xzqdm,substring(zldwdm,1,9) xzdm,count(*) sl from sddltb_qc where xzqdm in ('130432','210604') group by xzqdm,substring(zldwdm,1,9)) as a order by xzqdm,xzdm,sl
执行结果:
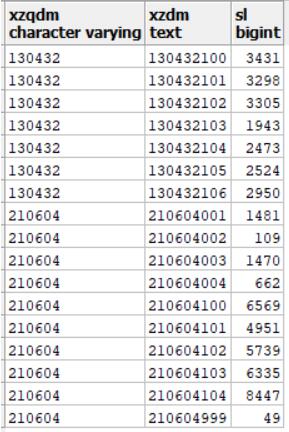
添加行序号:ROW_NUMBER () OVER (ORDER BY A.bsm ASC) AS 序号
分组添加序号:ROW_NUMBER () OVER (PARTITION BY xzqdm ORDER BY A.bsm ASC) AS 序号
补充:pgsql 表随机取几条数据
取100条
select * from map_route_info_composite order by random() limit 100
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

解决sqoop从postgresql拉数据,报错TCP/IP连接的问题
问题: sqoop从postgresql拉数据,在执行到mapreduce时报错Connection refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections 问题定位过程: 1.postgresql 5432端口已开放,执行任务的节点能telnet通,并且netcat测试通过 2.sqoop list-tables命令可正常执行,sq
-
Postgresql 检查数据库主从复制进度的操作
如何查看主从复制的状态,且备库应用落后了多少字节 这些信息要在主库中查询 查看流复制的信息可以使用主库上的视图 select pid,state,client_addr,sync_priority,sync_state from pg_stat_replication; pg_stat_replication中几个字断记录了发送wal的位置及备库接收到的wal的位置. sent_location--发送wal的位置 write_location--备库接收到的wal的位置 flush_locat
-
基于postgresql数据库锁表问题的解决
查询是否锁表了 select oid from pg_class where relname='可能锁表了的表' select pid from pg_locks where relation='上面查出的oid' 如果查询到了结果,表示该表被锁 则需要释放锁定 select pg_cancel_backend(上面查到的pid) 补充:PostgreSQL 解决锁表.死锁问题 1.-- 查询ACTIVITY的状态等信息 SELECT T .PID, T.STATE, T.QUERY, T.WA
-
在postgresql数据库中创建只读用户的操作
在pg数据库中创建只读用户可以采用如下方法.大体实现就是将特定schema的相关权限赋予只读用户. --创建用户 CREATE USER readonly WITH ENCRYPTED PASSWORD '123456'; --设置用户默认开启只读事务 ALTER USER readonly SET default_transaction_read_only = ON; --将schema中usage权限赋予给readonly用户,访问所有已存在的表 GRANT usage ON SCHEMA
-
解决postgreSql远程连接数据库超时的问题
首先在cmd中ping 这个ip如果发现可以ping通就可以考虑是 远程数据库开启了防火墙.或者数据库设置该ip不能访问. 防火墙问题:可以考虑直接关闭防火墙,或者设置防火墙开放5432端口 然后到postgresql安装目录下data中修改pg_hba.conf文件,配置用户的访问权限,拉到底部 host all all 127.0.0.1/32 trust host all all 192.168.1.0/24 md5 #表示允许网段192.168.1.0上的所有主机使用所有合法的数据库用户
-
sqoop读取postgresql数据库表格导入到hdfs中的实现
最近再学习spark streaming做实时计算这方面内容,过程中需要从后台数据库导出数据到hdfs中,经过调研发现需要使用sqoop进行操作,本次操作环境是Linux下. 首先确保环境安装了Hadoop和sqoop,安装只需要下载 ,解压 以及配置环境变量,这里不多说了,网上教程很多. 一.配置sqoop以及验证是否成功 切换到配置文件下:cd $SQOOP_HOME/conf 创建配置环境文件: cp sqoop-env-template.sh sqoop-env.sh 修改配置文件:co
-
postgresql 实现取出分组中最大的几条数据
看代码吧~ WITH Name AS ( SELECT * FROM ( SELECT xzqdm, SUBSTRING (zldwdm, 1, 9) xzdm, COUNT (*) sl FROM sddltb_qc WHERE xzqdm IN ('130432', '210604') GROUP BY xzqdm, SUBSTRING (zldwdm, 1, 9) ) AS A ORDER BY xzqdm, xzdm, sl ) SELECT xzqdm, xzdm, sl FROM (
-
postgreSQL数据库 实现向表中快速插入1000000条数据
不用创建函数,直接向表中快速插入1000000条数据 create table tbl_test (id int, info text, c_time timestamp); insert into tbl_test select generate_series(1,100000),md5(random()::text),clock_timestamp(); select count(id) from tbl_test; --查看个数据条数 补充:postgreSQL 批量插入10000条数据
-
oracle取数据库中最新的一条数据可能会遇到的bug(两种情况)
记一次 开发中遇到的坑: 第一种情况 rowid select * from table where rowid=(select max(rowid) from table ) 这种方式是取最大的rowid作为最新的数据,但是有一个隐患 :数据库一旦有删除操作,rowid不能保证每次都是递增的!即max(rowid)并不一定就是最新的数据,尽管可能不会每次复现 但这个问题是绝对存在的! 第二种情况 使用rownum (或相同思路) select t.* from (select ti.sysno
-
vue 如何删除数组中的某一条数据
目录 删除数组中的某一条数据 删除普通数组 删除数组对象 使用splice()删除数组中的一个数据 删除数组中的某一条数据 删除普通数组 let arr = [1,2,3,4,5]; //方法一 let index = arr.indexOf('3'); arr.splice(index, 1) //打印结果 [1,2,4,5] //方法二 let index = arr .findIndex(item => { if (item == '3') {
-
oracle实现根据字段分组排序,取其第一条数据
目录 以某个字段分组 取其第一条数据 oracle中对表中数据分组排序取最值 首先创建操作表emp 业务场景 总结 以某个字段分组 取其第一条数据 select * from (select t.app_id, t.emp_no, t.device_id, t.device_type, t.last_connect_time, t.device
-
SQL语句分组获取记录的第一条数据的方法
使用Northwind 数据库 首先查询Employees表 查询结果: city列里面只有5个城市 使用ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2) 先进行分组 注:根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的). sql语句为: select EmployeeID,LastName,FirstName,Title,TitleOfCourtesy,City,ROW_NUM
-
ajax 数据库中随机读取5条数据动态在页面中刷新
不能用数据库中的Top,后面发现了用这样一个方法可以实现...现就这个方法总结写了一个页面.有兴趣的朋友们可以一起学习下.... 前台代码: 复制代码 代码如下: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="ajaxRandomData.aspx.cs" Inherits="ajaxRandomData" %> <!DOCTYPE html
-
pyodps中的apply用法及groupby取分组排序第一条数据
目录 1.apply用法 2.取分组排序后的第一条数据 1.apply用法 apply在pandas里非常好用的,那在pyodps里如何去使用,还是有一些区别的,在pyodps中要对一行数据使用自定义函数,可以使用 apply 方法,axis 参数必须为 1,表示在行上操作. apply 的自定义函数接收一个参数,为上一步 Collection 的一行数据,用户可以通过属性.或者偏移取得一个字段的数据. iris.apply(lambda row: row.sepallength + row.s
-
mysql 一次向表中插入多条数据实例讲解
mysql一次插入多条数据: INSERT INTO hk_test(username, passwd) VALUES ('qmf2', 'qmf2'),('qmf3', 'qmf3'),('qmf4', 'qmf4'),('qmf5', 'qmf5') GO 我们先来创建一种表Authors: CREATE TABLE Authors( AuthID SMALLINT NOT NULL PRIMARY KEY, AuthFN VARCHAR(20), AuthMN VARCHAR(20), A
-
mysql中迅速插入百万条测试数据的方法
对比一下,首先是用 mysql 的存储过程弄的: 复制代码 代码如下: mysql>delimiter $ mysql>SET AUTOCOMMIT = 0$$ mysql> create procedure test() begin declare i decimal (10) default 0 ; dd:loop INSERT INTO `million` (`categ_id`, `categ_fid`, `SortPath`, `address`, `p_identifier`