Python使用Appium在移动端抓取微博数据的实现
目录
- 使用Appium在移动端抓取微博数据
- 查找Android App的Package和入口
- 记录微博刷新动作
- 爬取微博第一条信息
使用Appium在移动端抓取微博数据
Appium是移动端的自动化测试工具,读者可以类比为PC端的selenium。通过它,我们可以驱动App完成自动化的一系列操作,同样也可以爬取需要的内容。
这里,我们需要首先在PC端安装Appium软件,安装下载的地址如下:https://github.com/appium/appium-desktop/releases
安装软件的步骤非常简单,就与大多数软件安装步骤一样,这里不在赘述。
但是只安装Appium软件并不能操作手机App,还需要下载专业的Android工具Android SDK,这里读者可以直接下载安装Android Studio即可,安装完成之后,Android SDK也就安装完成了。
基础的配置到这里就结束了。下面,我们来通过Appium软件操作手机App。
查找Android App的Package和入口
这里,博主主要介绍如何操作Android手机,感兴趣的可以自己查阅资料配置IOS端。我们先来打开Appium软件,看看其登录界面。

如上图所示,我们不需要更改任何参数,只需要点击"Start Server v1.18.0"按钮,进行登录操作,登录之后,会出现如下界面。
这里,我们点击放大镜即可。点击之后,会出现步骤4的界面,我们需要在这里界面之中配置你需要操作或者说爬取的App。
比如,这里博主需要爬取微博App的数据,那么你需要下载微博App的.apk安装文件,然后通过反编译查找其包名与启动界面。具体反编译步骤如下:

如上图所示,我们需要通过压缩文件打开weibo.apk安装包,将AndroidManifest.xml拷贝出来。然后通过AXMLPrinter2.jar工具反编译AndroidManifest.xml,默认AndroidManifest.xml是乱码,反编译命令如下:
java -jar AXMLPrinter2.jar AndroidManifest.xml > AndroidManifest.txt
然后,我们在打开其AndroidManifest.txt就可以看到微博的包名以及启动界面的Activity名称,具体如下所示:

这里,我们得到微博的包名为:com.sina.weibo,而微博的启动界面为:com.sina.weibo.MainTabActivity。接着,可以配置Appium软件,效果如下:
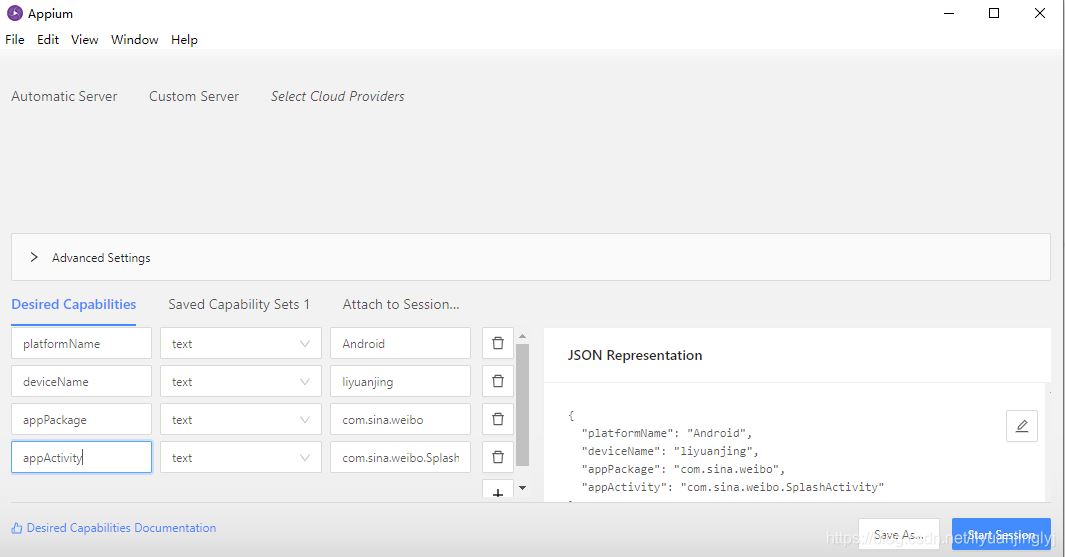
这里,读者可以直接点击Start Session,也可以点击保存Save As方便下一次直接使用。这里,博主先保存再点击Start Session(注意,deviceName是关于手机里面的设备名称,并不一定是你的手机名称):
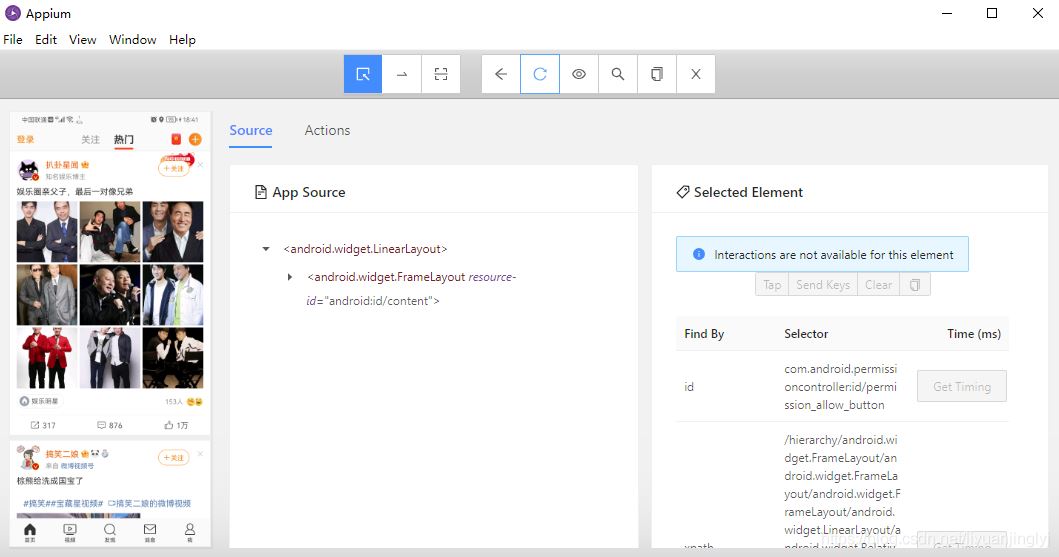
可以看到,现在我们的微博手机界面已经在Appium软件上显示了。下面,我们可以使用上面的眼睛按钮,监听我们要操作的步骤,然后保存为一个动作链。
记录微博刷新动作
在实际的微博中,我们通过下拉刷新微博界面。不过,其实还可以通过点击底部的首页按钮进行刷新,记录操作并生成Python代码的步骤如下所示:

这里,我们需要先点击上面的眼睛记录我们后续的操作。然后你可以选中首页按钮,再点击最右边的Tap,即完成了首页的刷新动作,同时也会生成对应的操作代码:
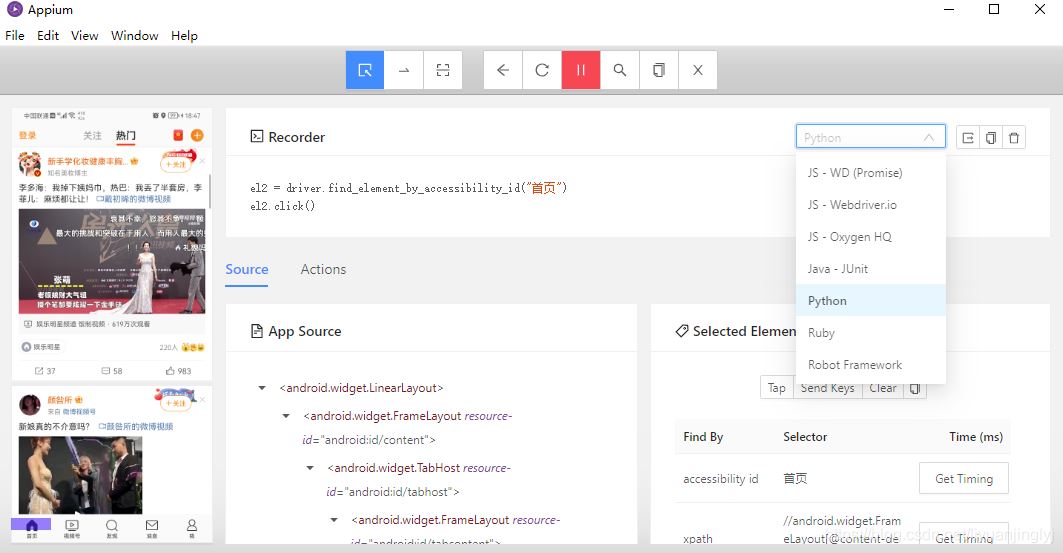
默认生成的操作语言是Java,你可以通过上图下拉选择自己需要的语言。这里,博主选择Python,毕竟讲解的是Python爬虫。
虽然上面的代码确实是操作手机App的代码,但是你直接copy到python编辑器,肯定是无法运行的,我们需要安装Appium-Python-Client包:
pip install Appium-Python-Client
安装完成之后,我们通过”from appium import webdriver“引入开发包,然后就可以通过上面的代码进行App爬虫或者说一系列动作链的操作了。
这里,我们先来实现将刚才通过Appium的操作,全部转换为代码形式,具体代码如下所示:
from appium import webdriver
import time
server="http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver=webdriver.Remote(server,desired_caps)
time.sleep(10)
el2 = driver.find_element_by_accessibility_id("首页")
el2.click()
如上面代码所示,这样我们就实现了通过软件操作App的全部步骤。不过,这里有一个小问题,因为打开App首次都是要赋予权限的,博主刚才手动关了,并没有录制这个动作。
所以,读者可以自己把赋予权限的步骤也录制进去,那么就是全自动了,这里作者偷个懒,就不录制了。
爬取微博第一条信息
刚刚我们通过刷新的步骤,重新获取了一遍微博首页的内容。现在,我们通过代码来获取首页第一条微博的内容。我们先来看看代码:
from appium import webdriver
import time
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
time.sleep(10)
descs = driver.find_element_by_id("com.sina.weibo:id/contentTextView")
print(descs.get_attribute("content-desc"))
这里,我们通过ID找到了第一条微博的控件,同时通过其属性"content-desc"获取到了微博的内容。图解效果如下:
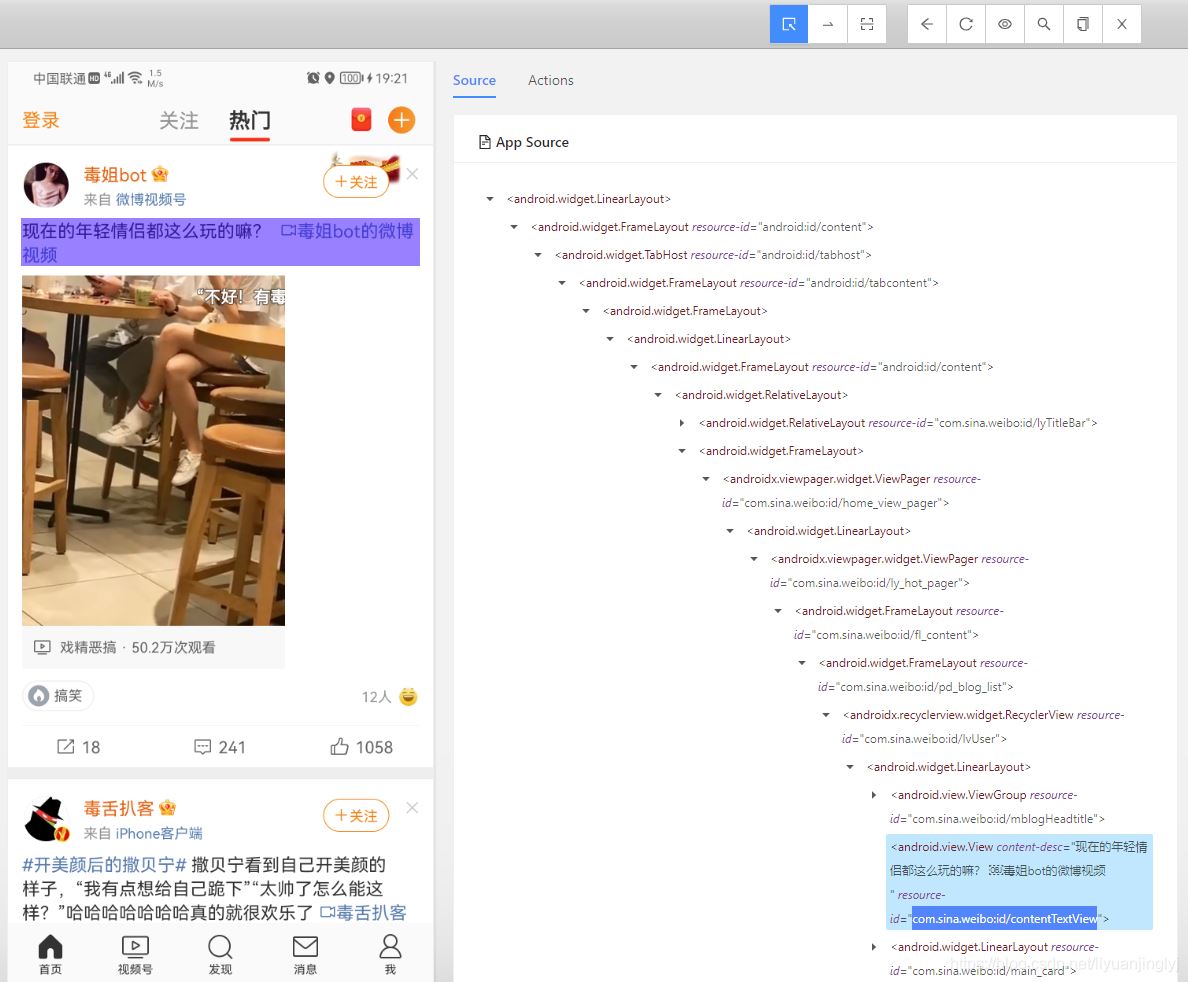
运行之后,效果如下:

当然,这里之所以不同是因为我们手机运行代码将微博界面又重新启动了一遍。不过这是我们手机运行后的第一条微博的信息。
到此这篇关于Python使用Appium在移动端抓取微博数据的实现的文章就介绍到这了,更多相关Python Appium抓取微博数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于Python3爬虫利器Appium的安装步骤
Appium是移动端的自动化测试工具,类似于前面所说的Selenium,利用它可以驱动Android.iOS等设备完成自动化测试,比如模拟点击.滑动.输入等操作,其官方网站为:http://appium.io/.本节中,我们就来了解一下Appium的安装方式. 1. 相关链接 GitHub:https://github.com/appium/appium 官方网站:http://appium.io 官方文档:http://appium.io/introduction.html 下载链接:http
-

用基于python的appium爬取b站直播消费记录
基于python的Appium进行b站直播消费记录爬取 之前看文章说fiddler也可以进行爬取,但尝试了一下没成功,这次选择appium进行爬取.类似的,可以运用爬取微信朋友圈和抖音等手机app相关数据 正文 #环境配置参考 前期工作准备,需要安装python.jdk.PyCharm.Appium-windows-x.x.Appium_Python_Client.Android SDK,pycharm可以用anaconda的jupyter来替代 具体可以参考这篇博客,讲的算是很清楚啦 http
-
详解使用python爬取抖音app视频(appium可以操控手机)
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
Python使用Appium在移动端抓取微博数据的实现
目录 使用Appium在移动端抓取微博数据 查找Android App的Package和入口 记录微博刷新动作 爬取微博第一条信息 使用Appium在移动端抓取微博数据 Appium是移动端的自动化测试工具,读者可以类比为PC端的selenium.通过它,我们可以驱动App完成自动化的一系列操作,同样也可以爬取需要的内容. 这里,我们需要首先在PC端安装Appium软件,安装下载的地址如下:https://github.com/appium/appium-desktop/releases 安装软
-
python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检测是否可用,可用保存,通过函数get_proxies可以获得ip,如:{'HTTPS': '106.12.7.54:8118'} 下面放上源代码,并详细注释: import requests from lxml import etree from requests.packages import u
-
如何使用Python逆向抓取APP数据
今天给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固,所以除了抓包之外,还需要对 APP 进行查壳脱壳反编译等操作. 所需设备和环境: 设备:安卓手机 抓包: fiddler+xposed+JustTrustme 查壳:ApkScan-PKID 脱壳:frida-DEXDump 反编译:jadx-gui hook:frida 抓包 手机安装app,设置好
-
实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7).官方文档中介绍了三种方法进行安装,我采用的是使用 easy_install 进行安装,首先是下载Windows版本的setuptools(下载地址:http://pypi.python.org/pypi/setuptools),下载完后一路NEXT就可以了. 安装完setuptool以后.执行CMD,然后运行一下命令: easy_i
-
Python使用Selenium模块模拟浏览器抓取斗鱼直播间信息示例
本文实例讲述了Python使用Selenium模块模拟浏览器抓取斗鱼直播间信息.分享给大家供大家参考,具体如下: import time from multiprocessing import Pool from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.web
-
Python基于分析Ajax请求实现抓取今日头条街拍图集功能示例
本文实例讲述了Python基于分析Ajax请求实现抓取今日头条街拍图集功能.分享给大家供大家参考,具体如下: 代码: import os import re import json import time from hashlib import md5 from multiprocessing import Pool import requests from requests.exceptions import RequestException from pymongo import Mongo
-
Python selenium抓取微博内容的示例代码
Selenium简介与安装 Selenium是什么? Selenium也是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mozilla Firefox.Mozilla Suite等. 安装 直接使用pip命令安装即可! pip install selenium Python抓取微博有两种方式,一是通过selenium自动登录后从页面直接爬取,二是通过api. 这里采用selenium的方式. 程序: from selen
-
python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
使用python爬取微博数据打造一颗“心”
前言 一年一度的虐狗节终于过去了,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗"爱心",我想她一定会感动得哭了吧.哈哈 准备工作 有了想法之后就开始行动了,自然最先想到的就是用 Python 了,大体思路就是把微博数据爬下来,数据经过清洗加工后再进行分词处理,处理后的数据交给词云工具,配合科学计算工具和绘图工具制作成图像出来,涉及到的工具包有: requests
-
PHP中4种常用的抓取网络数据方法
本小节的名称为 fsockopen,curl与file_get_contents,具体是探讨这三种方式进行网络数据输入输出的一些汇总.关于 fsockopen 前面已经谈了不少,下面开始转入其它.这里先简单罗列一下一些常见的抓取网络数据的一些方法. 1. 用 file_get_contents 以 get 方式获取内容: $url = 'http://localhost/test2.php'; $html = file_get_contents($url); echo $html; 2. 用fo