plotly分割显示mnist的方法详解
目录
- 加载mnist
- plotly显示多个mnist样本
- plotly显示单个图片
- mnist单样本分拆显示
- mnist单样本错误的分拆显示
- 总结
加载mnist
import numpy
def loadMnist() -> (numpy.ndarray,numpy.ndarray,numpy.ndarray,numpy.ndarray):
"""
:return: (xTrain,yTrain,xTest,yTest)
"""
global _TRAIN_SAMPLE_CNT
global PIC_H
global PIC_W
global _TEST_SAMPLE_CNT
global PIC_HW
from tensorflow import keras #修改点: tensorflow:2.6.2,keras:2.6.0 此版本下, import keras 换成 from tensorflow import keras
import tensorflow
print(f"keras.__version__:{keras.__version__}")#2.6.0
print(f"tensorflow.__version__:{tensorflow.__version__}")#2.6.2
# avatar_img_path = "/kaggle/working/data"
import os
import cv2
xTrain:numpy.ndarray; label_train:numpy.ndarray; xTest:numpy.ndarray; label_test:numpy.ndarray
yTrain:numpy.ndarray; yTest:numpy.ndarray
#%userprofile%\.keras\datasets\mnist.npz
(xTrain, label_train), (xTest, label_test) = keras.datasets.mnist.load_data()
# x_train.shape,y_train.shape, x_test.shape, label_test.shape
# (60000, 28, 28), (60000,), (10000, 28, 28), (10000,)
_TRAIN_SAMPLE_CNT,PIC_H,PIC_W=xTrain.shape
PIC_HW=PIC_H*PIC_W
xTrain=xTrain.reshape((-1, PIC_H * PIC_W))
xTest=xTest.reshape((-1, PIC_H * PIC_W))
_TEST_SAMPLE_CNT=label_test.shape[0]
from sklearn import preprocessing
#pytorch 的 y 不需要 oneHot
#_label_train是1列多行的样子. _label_train.shape : (60000, 1)
yTrain=label_train
# y_train.shape:(60000) ; y_train.dtype: dtype('int')
CLASS_CNT=yTrain.shape[0]
yTest=label_test
# y_test.shape:(10000) ; y_test.dtype: dtype('int')
xTrainMinMaxScaler:preprocessing.MinMaxScaler; xTestMinMaxScaler:preprocessing.MinMaxScaler
xTrainMinMaxScaler=preprocessing.MinMaxScaler()
xTestMinMaxScaler=preprocessing.MinMaxScaler()
# x_train.dtype: dtype('uint8') -> dtype('float64')
xTrain=xTrainMinMaxScaler.fit_transform(xTrain)
# x_test.dtype: dtype('uint8') -> dtype('float64')
xTest = xTestMinMaxScaler.fit_transform(xTest)
return (xTrain,yTrain,xTest,yTest)
xTrain:torch.Tensor;yTrain:torch.Tensor; xTest:torch.Tensor; yTest:torch.Tensor(xTrain,yTrain,xTest,yTest)=loadMnist()
plotly 显示多个mnist样本
import plotly.express import plotly.graph_objects import plotly.subplots import numpy xTrain:numpy.ndarray=numpy.random.random((2,28,28)) #xTrain[0].shape:(28,28) #fig:plotly.graph_objects.Figure=None fig=plotly.subplots.make_subplots(rows=1,cols=2,shared_xaxes=True,shared_yaxes=True) #共1行2列 fig.add_trace(trace=plotly.express.imshow(img=xTrain[0]).data[0],row=1,col=1) #第1行第1列 fig.add_trace(trace=plotly.express.imshow(img=xTrain[1]).data[0],row=1,col=2) #第1行第2列 fig.show() #参数row、col从1开始, 不是从0开始的
plotly 显示单个图片
import numpy xTrain:numpy.ndarray=numpy.random.random((2,28,28)) #xTrain[0].shape:(28,28) import plotly.express import plotly.graph_objects plotly.express.imshow(img=xTrain[0]).show() #其中plotly.express.imshow(img=xTrain[0]) 的类型是 plotly.graph_objects.Figure
xTrain[0]显示如下:
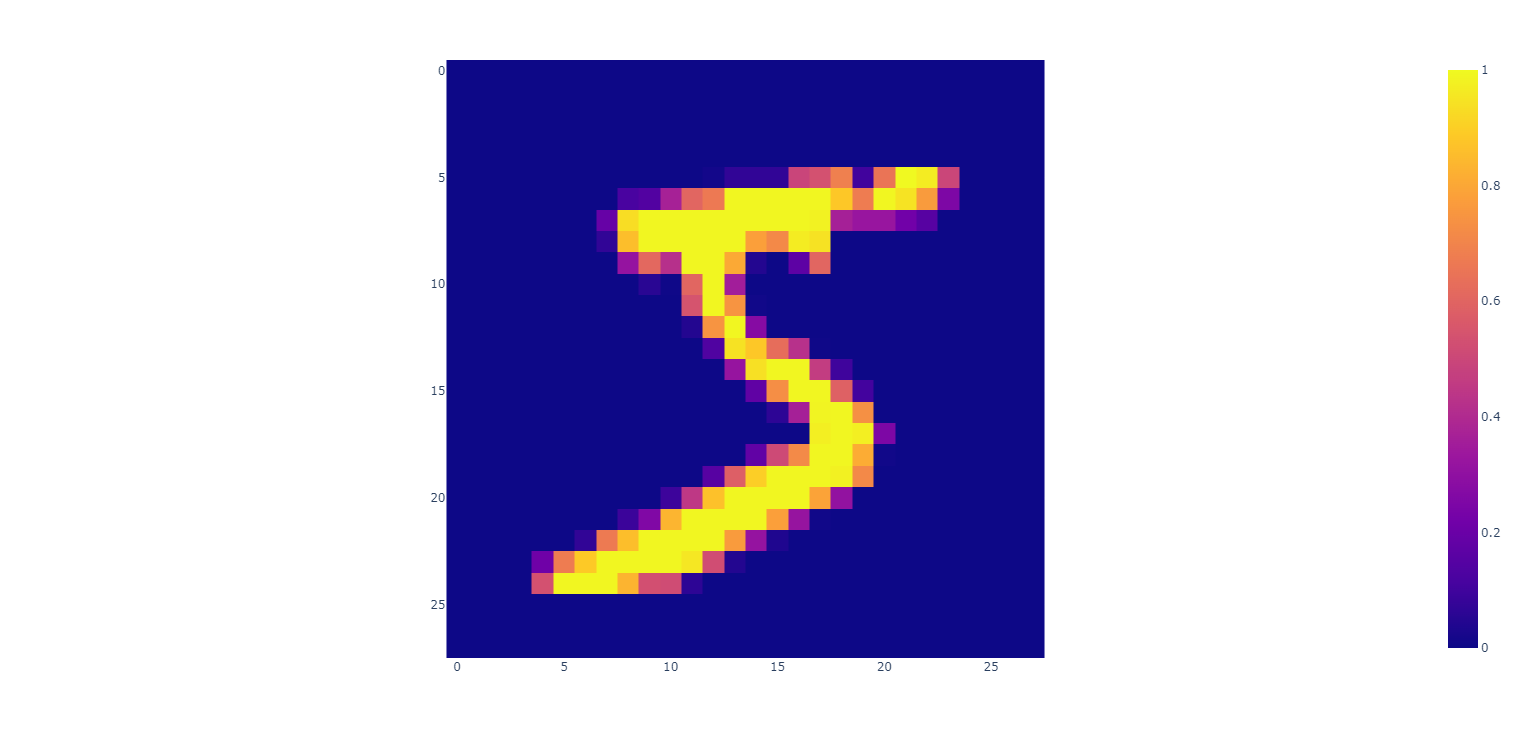
mnist单样本分拆显示
#mnist单样本分割 分割成4*4小格子显示出来, 以确认分割的对不对。 以下代码是正确的分割。 主要逻辑是: (7,4,7,4) [h, :, w, :]
fig:plotly.graph_objects.Figure=plotly.subplots.make_subplots(rows=7,cols=7,shared_xaxes=True,shared_yaxes=True,vertical_spacing=0,horizontal_spacing=0)
xTrain0Img:torch.Tensor=xTrain[0].reshape((PIC_H,PIC_W))
plotly.express.imshow(img=xTrain0Img).show()
xTrain0ImgCells:torch.Tensor=xTrain0Img.reshape((7,4,7,4))
for h in range(7):
for w in range(7):
print(f"h,w:{h},{w}")
fig.add_trace(trace=plotly.express.imshow(xTrain0ImgCells[h,:,w,:]).data[0],col=h+1,row=w+1)
fig.show()
mnist单样本分拆显示结果: 由此图可知 (7,4,7,4) [h, :, w, :] 是正常的取相邻的像素点出而形成的4*4的小方格 ,这正是所需要的

上图显示 的 横坐标拉伸比例大于纵坐标 所以看起来像一个被拉横了的手写数字5 ,如果能让plotly把横纵拉伸比例设为相等 上图会更像手写数字5
可以用torch.swapdim进一步改成以下代码
"""
mnist单样本分割 分割成4*4小格子显示出来, 重点逻辑是: (7, 4, 7, 4) [h, :, w, :]
:param xTrain:
:return:
"""
fig: plotly.graph_objects.Figure = plotly.subplots.make_subplots(rows=7, cols=7, shared_xaxes=True, shared_yaxes=True, vertical_spacing=0, horizontal_spacing=0)
xTrain0Img: torch.Tensor = xTrain[0].reshape((PIC_H, PIC_W))
plotly.express.imshow(img=xTrain0Img).show()
xTrain0ImgCells: torch.Tensor = xTrain0Img.reshape((7, 4, 7, 4))
xTrain0ImgCells=torch.swapdims(input=xTrain0ImgCells,dim0=1,dim1=2)#交换 (7, 4, 7, 4) 维度1、维度2 即 (0:7, 1:4, 2:7, 3:4)
for h in range(7):
for w in range(7):
print(f"h,w:{h},{w}")
fig.add_trace(trace=plotly.express.imshow(xTrain0ImgCells[h, w]).data[0], col=h + 1, row=w + 1) # [h, w, :, :] 或 [h, w]
fig.show()
mnist单样本错误的分拆显示
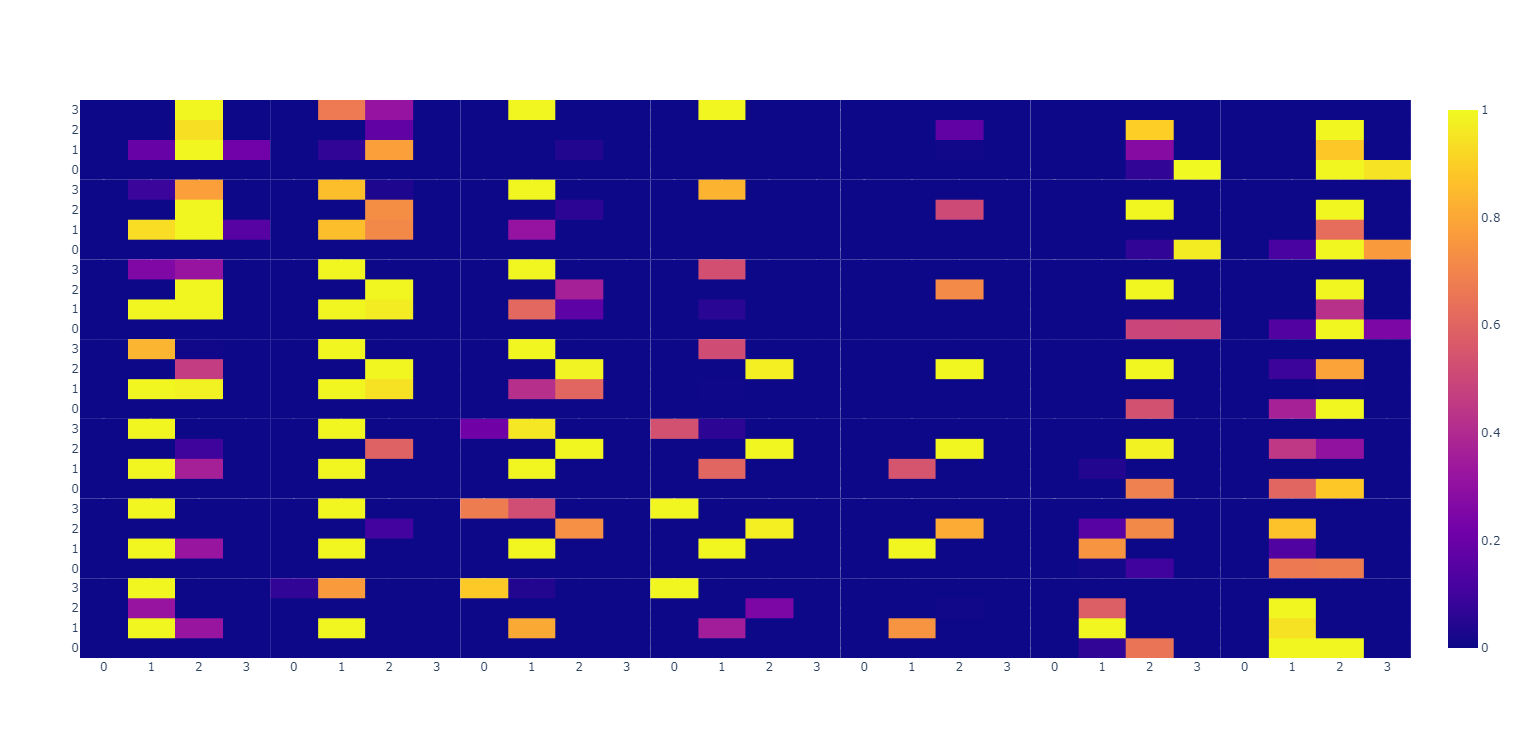
以下 mnist单样本错误的分拆显示:
# mnist单样本错误的分拆显示:
fig: plotly.graph_objects.Figure = plotly.subplots.make_subplots(rows=7, cols=7, shared_xaxes=True, shared_yaxes=True, vertical_spacing=0, horizontal_spacing=0)
xTrain0Img: torch.Tensor = xTrain[0].reshape((PIC_H, PIC_W))
plotly.express.imshow(img=xTrain0Img).show()
xTrain0ImgCells: torch.Tensor = xTrain0Img.reshape((4,7, 4, 7)) #原本是: (7,4,7,4)
for h in range(7):
for w in range(7):
print(f"h,w:{h},{w}")
fig.add_trace(trace=plotly.express.imshow(xTrain0ImgCells[:, h, :, w]).data[0], col=h + 1, row=w + 1) #原本是: [h,:,w,:]
fig.show()
其结果为: 由此图可知 (4,7, 4, 7) [:, h, :, w] 是间隔的取出而形成的4*4的小方格
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Python可视化工具Plotly的应用教程
目录 一.简介 二.各图运用 1.柱状图 2.散点图 3.冒泡散点图 4.旭日图 5.地图图形 三.实战案例 一.简介 发展由来: 随着信息技术的发展和硬件设备成本的降低,当今的互联网存在海量的数据,要想快速从这些数据中获取更多有效的信息,数据可视化是重要的一环.对于Python语言来说,比较传统的数据可视化模块是Matplotlib,但它存在不够美观.静态性.不易分享等缺点,限制了Python在数据可视化方面的发展. 为了解决这个问题,新型的动态可视化开源模块Plotly应运而生.由于Plot
-
python可视化plotly 图例(legend)设置
目录 一.图例(legend) 二.update_layout(legend={}) 相关参数及示例 一.图例(legend) import plotly.io as pio import plotly.express as px import plotly.graph_objects as go from plotly.subplots import make_subplots import pandas as pd import numpy as np # 设置plotly默认主题 pio.
-
Python MNIST手写体识别详解与试练
[人工智能项目]MNIST手写体识别实验及分析 1.实验内容简述 1.1 实验环境 本实验采用的软硬件实验环境如表所示: 在Windows操作系统下,采用基于Tensorflow的Keras的深度学习框架,对MNIST进行训练和测试. 采用keras的深度学习框架,keras是一个专为简单的神经网络组装而设计的Python库,具有大量预先包装的网络类型,包括二维和三维风格的卷积网络.短期和长期的网络以及更广泛的一般网络.使用keras构建网络是直接的,keras在其Api设计中使用的语义是面向层
-
由浅入深学习TensorFlow MNIST 数据集
目录 MNIST 数据集介绍 LeNet 模型介绍 卷积 池化 (下采样) 激活函数 (ReLU) LeNet 逐层分析 1. 第一个卷积层 2. 第一个池化层 3. 第二个卷积层 4. 第二个池化层 5. 全连接卷积层 6. 全连接层 7. 全连接层 (输出层) 代码实现 导包 读取 & 查看数据 数据预处理 模型建立 训练模型 保存模型 流程总结 完整代码 MNIST 数据集介绍 MNIST 包含 0~9 的手写数字, 共有 60000 个训练集和 10000 个测试集. 数据的格式为单通道
-
Python实战之MNIST手写数字识别详解
目录 数据集介绍 1.数据预处理 2.网络搭建 3.网络配置 关于优化器 关于损失函数 关于指标 4.网络训练与测试 5.绘制loss和accuracy随着epochs的变化图 6.完整代码 数据集介绍 MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片,且内置于keras.本文采用Tensorflow下Keras(Keras中文文档)神经网络API进行网络搭建. 开始之前,先回忆下机器学习
-
python用plotly实现绘制局部放大图
目录 最终效果展示 实现思路 导入库 随机生成一些数据 封装绘图代码 开始绘制 总结 最终效果展示 实现思路 在绘图区域插入一个嵌入图,嵌入图与原图的绘画保持一致,通过限制嵌入图的x轴和y轴的显示范围,达到缩放的效果,并在原图上绘画一个矩形框,以凸显缩放的区域,最后通过两条直线凸显缩放关系. 导入库 import plotly.io as pio import plotly.graph_objects as go import pandas as pd import numpy as np #
-
plotly分割显示mnist的方法详解
目录 加载mnist plotly显示多个mnist样本 plotly显示单个图片 mnist单样本分拆显示 mnist单样本错误的分拆显示 总结 加载mnist import numpy def loadMnist() -> (numpy.ndarray,numpy.ndarray,numpy.ndarray,numpy.ndarray): """ :return: (xTrain,yTrain,xTest,yTest) """ glob
-
Java实现大文件的分割与合并的方法详解
目录 一.题目描述-合并多个文本文件 1.题目 2.解题思路 3.代码详解 二.题目描述-对大文件进行分割处理 1.题目 2.解题思路 3.代码详解 三.题目描述-分割后又再次合并 1.题目 2.解题思路 3.代码详解 4.多学一个知识点 一.题目描述-合并多个文本文件 1.题目 题目:做一个合并多个文本文件的工具. 2.解题思路 创建一个类:TextFileConcatenation 使用TextFileConcatenation继承JFrame构建窗体 读取文本文件时,用的是Buffered
-
Android操作SQLite数据库(增、删、改、查、分页等)及ListView显示数据的方法详解
本文实例讲述了Android操作SQLite数据库(增.删.改.查.分页等)及ListView显示数据的方法.分享给大家供大家参考,具体如下: 由于刚接触android开发,故此想把学到的基础知识记录一下,以备查询,故此写的比较啰嗦: 步骤如下: 一.介绍: 此文主要是介绍怎么使用android自带的数据库SQLite,以及把后台的数据用ListView控件显示 二.新建一个android工程--DBSQLiteOperate 工程目录: 三.清单列表AndroidManifest.xml的配置
-
C#隐式/显示实现接口方法详解
接口定义了一系列的行为规范,为类型定义一种Can-Do的功能.例如,实现IEnumerable接口定义了GetEnumerator方法,用于获取一个枚举数,该枚举数支持在集合上进行迭代,也就是我们常说的foreach.接口只是定义行为,具体的实现需要由具体类型负责,实现接口的方法又分为隐式实现与显示实现. 一.隐式/显示实现接口方法 简单的说,我们平时"默认"使用的都是隐式的实现方式.例如: interface ILog { void Log(); } public class Fil
-
Python实现matplotlib显示中文的方法详解
本文实例讲述了Python实现matplotlib显示中文的方法.分享给大家供大家参考,具体如下: [注意] 可能与本文主题无关,不过我还是想指出来:使用matplotlib库时,下面两种导入方式是等价的(我指的是等效,当然这个说法可以商榷:) import matplotlib.pyplot as plt import pylab as plt [效果图] [方式一]FontProperties import matplotlib.pyplot as plt from matplotlib.f
-
Django框架实现分页显示内容的方法详解
本文实例讲述了Django框架实现分页显示内容的方法.分享给大家供大家参考,具体如下: 分页 1.作用 数据加载优化 2.前端引入bootstrap样式: {# 引入bootstrap样式的cdn资源 #} <link href="https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.min.css" rel="external nofollow" rel="stylesheet">
-
Python+OpenCV实现阈值分割的方法详解
目录 一.全局阈值 1.效果图 2.源码 二.滑动改变阈值(滑动条) 1.效果图 2.源码 三.自适应阈值分割 1.效果图 2.源码 3.GaussianBlur()函数去噪 四.参数解释 一.全局阈值 原图: 整幅图采用一个阈值,与图片的每一个像素灰度进行比较,重新赋值: 1.效果图 2.源码 import cv2 import matplotlib.pyplot as plt #设定阈值 thresh=130 #载入原图,并转化为灰度图像 img_original=cv2.imread(r'
-
MFC修改编辑框光标显示位置方法详解
当前的开发环境:VS2010,32位 MFC框架 使用MFC中系统CComboBox控件时,会有三种风格,其中有一种风格:CBN_DROPDWON,该编辑框是可以进行编辑的. 更改多CComboBox高度的友友们就会发现这样一个问题,控件高度变高后,edit编辑控件的高度光标一直处于左上角的位置,看起来很是不美观,如下图所示: 其实,想要实现光标处于垂直状态,如下图所示: 这种效果看着就比较顺眼了,此时,有人想要问,怎么改变编辑框的高度呢? 有人使用系统的MoveWindow,居然不生效?这个问
-
WPF实现在控件上显示Loading等待动画的方法详解
WPF 如何在控件上显示 Loading 等待动画 框架使用.NET40: Visual Studio 2022; 使用方式需引入命名空间后设置控件的附加属性 wd:Loading.IsShow="true",即可显示默认等待动画效果如下: 如需自定义 Loading 一定要 先设置 wd:Loading.Child 在设置 IsShow="true" . 显示不同 Loading 内容需 wd:Loading.Child ={x:Static wd:NormalL
-
对python3 Serial 串口助手的接收读取数据方法详解
其实网上已经有许多python语言书写的串口,但大部分都是python2写的,没有找到一个合适的python编写的串口助手,只能自己来写一个串口助手,由于我只需要串口能够接收读取数据就可以了,故而这个串口助手只实现了数据的接收读取. 创建串口助手首先需要创建一个类,重构类的实现过程如下: #coding=gb18030 import threading import time import serial class ComThread: def __init__(self, Port='COM3