springboot+webmagic实现java爬虫jdbc及mysql的方法
前段时间需要爬取网页上的信息,自己对于爬虫没有任何了解,就了解了一下webmagic,写了个简单的爬虫。
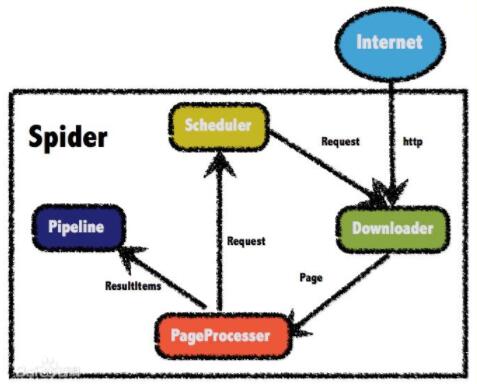
一、首先介绍一下webmagic:
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
实现理念:
Maven依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
jdbc模式:
ublic class CsdnBlogDao {
private Connection conn = null;
private Statement stmt = null;
public CsdnBlogDao() {
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/test?"
+ "user=***&password=***3&useUnicode=true&characterEncoding=UTF8";
conn = DriverManager.getConnection(url);
stmt = conn.createStatement();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public int add(CsdnBlog csdnBlog) {
try {
String sql = "INSERT INTO `test`.`csdnblog` (`keyes`, `titles`, `content` , `dates`, `tags`, `category`, `views`, `comments`, `copyright`) VALUES (?, ?, ?, ?, ?, ?, ?, ?,?);";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, csdnBlog.getKey());
ps.setString(2, csdnBlog.getTitle());
ps.setString(3,csdnBlog.getContent());
ps.setString(4, csdnBlog.getDates());
ps.setString(5, csdnBlog.getTags());
ps.setString(6, csdnBlog.getCategory());
ps.setInt(7, csdnBlog.getView());
ps.setInt(8, csdnBlog.getComments());
ps.setInt(9, csdnBlog.getCopyright());
return ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
return -1;
}
}
实体类:
public class CsdnBlog {
private int key;// 编号
private String title;// 标题
private String dates;// 日期
private String tags;// 标签
private String category;// 分类
private int view;// 阅读人数
private int comments;// 评论人数
private int copyright;// 是否原创
private String content; //文字内容
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public int getKey() {
return key;
}
public void setKey(int key) {
this.key = key;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDates() {
return dates;
}
public void setDates(String dates) {
this.dates = dates;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public int getView() {
return view;
}
public void setView(int view) {
this.view = view;
}
public int getComments() {
return comments;
}
public void setComments(int comments) {
this.comments = comments;
}
public int getCopyright() {
return copyright;
}
public void setCopyright(int copyright) {
this.copyright = copyright;
}
@Override
public String toString() {
return "CsdnBlog [key=" + key + ", title=" + title + ", content=" + content + ",dates=" + dates + ", tags=" + tags + ", category="
+ category + ", view=" + view + ", comments=" + comments + ", copyright=" + copyright + "]";
}
}
启动类:
public class CsdnBlogPageProcessor implements PageProcessor {
private static String username="CHENYUFENG1991"; // 设置csdn用户名
private static int size = 0;// 共抓取到的文章数量
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public Site getSite() {
return site;
}
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public void process(Page page) {
// 列表页
if (!page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/\\d+").match()) {
// 添加所有文章页
page.addTargetRequests(page.getHtml().xpath("//div[@id='article_list']").links()// 限定文章列表获取区域
.regex("/" + username + "/article/details/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 添加其他列表页
page.addTargetRequests(page.getHtml().xpath("//div[@id='papelist']").links()// 限定其他列表页获取区域
.regex("/" + username + "/article/list/\\d+")
.replace("/" + username + "/", "http://blog.csdn.net/" + username + "/")// 巧用替换给把相对url转换成绝对url
.all());
// 文章页
} else {
size++;// 文章数量加1
// 用CsdnBlog类来存抓取到的数据,方便存入数据库
CsdnBlog csdnBlog = new CsdnBlog();
// 设置编号
csdnBlog.setKey(Integer.parseInt(
page.getUrl().regex("http://blog\\.csdn\\.net/" + username + "/article/details/(\\d+)").get()));
// 设置标题
csdnBlog.setTitle(
page.getHtml().xpath("//div[@class='article_title']//span[@class='link_title']/a/text()").get());
//设置内容
csdnBlog.setContent(
page.getHtml().xpath("//div[@class='article_content']/allText()").get());
// 设置日期
csdnBlog.setDates(
page.getHtml().xpath("//div[@class='article_r']/span[@class='link_postdate']/text()").get());
// 设置标签(可以有多个,用,来分割)
csdnBlog.setTags(listToString(page.getHtml().xpath("//div[@class='article_l']/span[@class='link_categories']/a/allText()").all()));
// 设置类别(可以有多个,用,来分割)
csdnBlog.setCategory(listToString(page.getHtml().xpath("//div[@class='category_r']/label/span/text()").all()));
// 设置阅读人数
csdnBlog.setView(Integer.parseInt(page.getHtml().xpath("//div[@class='article_r']/span[@class='link_view']")
.regex("(\\d+)人阅读").get()));
// 设置评论人数
csdnBlog.setComments(Integer.parseInt(page.getHtml()
.xpath("//div[@class='article_r']/span[@class='link_comments']").regex("\\((\\d+)\\)").get()));
// 设置是否原创
csdnBlog.setCopyright(page.getHtml().regex("bog_copyright").match() ? 1 : 0);
// 把对象存入数据库
new CsdnBlogDao().add(csdnBlog);
// 把对象输出控制台
System.out.println(csdnBlog);
}
}
// 把list转换为string,用,分割
public static String listToString(List<String> stringList) {
if (stringList == null) {
return null;
}
StringBuilder result = new StringBuilder();
boolean flag = false;
for (String string : stringList) {
if (flag) {
result.append(",");
} else {
flag = true;
}
result.append(string);
}
return result.toString();
}
public static void main(String[] args) {
long startTime, endTime;
System.out.println("【爬虫开始】...");
startTime = System.currentTimeMillis();
// 从用户博客首页开始抓,开启5个线程,启动爬虫
Spider.create(new CsdnBlogPageProcessor()).addUrl("http://blog.csdn.net/" + username).thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("【爬虫结束】共抓取" + size + "篇文章,耗时约" + ((endTime - startTime) / 1000) + "秒,已保存到数据库,请查收!");
}
}
使用mysql类型:
public class GamePageProcessor implements PageProcessor {
private static final Logger logger = LoggerFactory.getLogger(GamePageProcessor.class);
private static DianJingService d;
private static BannerService bs;
private static SportService ss;
private static YuLeNewsService ys;
private static UpdateService ud ;
// 抓取网站的相关配置,包括:编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public Site getSite() {
return site;
}
// process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
public static void main(String[] args) {
ConfigurableApplicationContext context= SpringApplication.run(GamePageProcessor.class, args);
d = context.getBean(DianJingService.class);
//Spider.create(new GamePageProcessor()).addUrl("网址").thread(5).run();
}
public void process(Page page) {
Selectable url = page.getUrl();
if (url.toString().equals("网址")) {
DianJingVideo dv = new DianJingVideo();
List<String> ls = page.getHtml().xpath("//div[@class='v']/div[@class='v-meta va']/div[@class='v-meta-title']/a/text()").all();
//hrefs
List<String> ls1 = page.getHtml().xpath("//div[@class='v']/div[@class='v-link']/a/@href").all();//获取a标签的href
List<String> ls2 = page.getHtml().xpath("//div[@class='v']/div[@class='v-meta va']/div[@class='v-meta-entry']/div[@class='v-meta-data']/span[@class='r']/text()").all();
//photo
List<String> ls3 = page.getHtml().xpath("//div[@class='v']/div[@class='v-thumb']/img/@src").all();
for (int i = 0; i < 5; i++) {
dv.setTitles(ls.get(i));
dv.setCategory("");
dv.setDates(ls2.get(i));
dv.setHrefs(ls1.get(i));
dv.setPhoto(ls3.get(i));
dv.setSources("");
d.addVideo(dv);
}
}
}
Controller:
@Controller
@RequestMapping(value = "/dianjing")
public class DianJingController {
@Autowired
private DianJingService s;
/*
手游
*/
@RequestMapping("/dianjing")
@ResponseBody
public Object dianjing(){
List<DianJing> list = s.find2();
JSONObject jo = new JSONObject();
if(list!=null){
jo.put("code",0);
jo.put("success",true);
jo.put("count",list.size());
jo.put("list",list);
}
return jo;
}
}
实体类就不展示了
dao层
@Insert("insert into dianjing (titles,dates,category,hrefs,photo,sources) values(#{titles},#{dates},#{category},#{hrefs},#{photo},#{sources})")
int adddj(DianJing dj);
以上这篇springboot+webmagic实现java爬虫jdbc及mysql的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

springboot的java配置方式(实例讲解)
1.创建User实体类. @Data public class User { private String username; private String password; private Integer age; } 2.创建UserDao用于模拟数据库交互. public class UserDao{ public List<User> queryUserList() { List<User> result = new ArrayList<User>(); //
-
SpringBoot之Java配置的实现
Java配置也是Spring4.0推荐的配置方式,完全可以取代XML的配置方式,也是SpringBoot推荐的方式. Java配置是通过@Configuation和@Bean来实现的: 1.@Configuation注解,说明此类是配置类,相当于Spring的XML方式 2.@Bean注解,注解在方法上,当前方法返回的是一个Bean eg: 此类没有使用@Service等注解方式 package com.wisely.heighlight_spring4.ch1.javaconfig; publ
-
浅谈Java(SpringBoot)基于zookeeper的分布式锁实现
通过zookeeper实现分布式锁 1.创建zookeeper的client 首先通过CuratorFrameworkFactory创建一个连接zookeeper的连接CuratorFramework client public class CuratorFactoryBean implements FactoryBean<CuratorFramework>, InitializingBean, DisposableBean { private static final Logger LOGG
-
SpringBoot项目修改访问端口和访问路径的方法
创建SpringBoot项目,启动后,默认的访问路径即主机IP+默认端口号8080:http://localhost:8080/ 此时,我们就可以访问Controller层的接口了,如:http://localhost:8080/hello package com.springboot.test; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.a
-
5分钟快速上手Spring Boot
概述 与一些动态语言(如Ruby.Groovy.Node.js)相比,Java开发显得异常笨重.接触过外包项目的朋友也有所了解,如果要开发一个小型项目,首选的编程语言并不是Java,而是PHP.为什么呢?因为开发起来快!目前很多大型互联网公司的早起编程语言都是类似PHP这种能够快速开发的语言. 既然问题出现了,那必然有解决问题的方案,SpringBoot做到了.SpringBoot是由Pivotal公司所属团队研发,该公司的企业宗旨为: 致力于"改变世界构造软件的方式(We are transf
-
详解SpringBoot实现JPA的save方法不更新null属性
序言:直接调用原生Save方法会导致null属性覆盖到数据库,使用起来十分不方便.本文提供便捷方法解决此问题. 核心思路 如果现在保存某User对象,首先根据主键查询这个User的最新对象,然后将此User对象的非空属性覆盖到最新对象. 核心代码 直接修改通用JpaRepository的实现类,然后在启动类标记此实现类即可. 一.通用CRUD实现类 public class SimpleJpaRepositoryImpl<T, ID> extends SimpleJpaRepository&l
-
java Springboot实现多文件上传功能
前端采用layui框架,讲解多文件上传的完整实现功能. 前端html重点代码如下: <div class="layui-form-item"> <label class="layui-form-label">上传文件</label> <div class="layui-input-block"> <div class="layui-upload"> <butto
-
java~springboot~ibatis数组in查询的实现方法
在ibatis的xml文件里,我们去写sql语句,对应mapper类的方法,这些sql语句与控制台上没什么两样,但在有些功能上需要注意,如where in这种从数组里查询符合条件的集合里,需要在xml里进行特别的处理. <update id="batchUpdate" parameterType="map"> update customer_info set status=#{status},appoint_time=#{appointTime} whe
-
SpringBoot文件上传控制及Java 获取和判断文件头信息
之前在使用SpringBoot进行文件上传时,遇到了很多问题.于是在翻阅了很多的博文之后,总算将上传功能进行了相应的完善,便在这里记录下来,供自己以后查阅. 首先,是建立一个标准的SpringBoot 的工程,这里使用的IDE是Intellij Idea,为了方便配置,将默认的配置文件替换为了application.yml. 1.在index.html中进行文件上传功能,这里使用的文件上传方式是ajax,当然也可以按照自己的具体要求使用传统的表单文件上传. <!DOCTYPE html> &l
-
springboot+webmagic实现java爬虫jdbc及mysql的方法
前段时间需要爬取网页上的信息,自己对于爬虫没有任何了解,就了解了一下webmagic,写了个简单的爬虫. 一.首先介绍一下webmagic: webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取.页面下载.内容抽取.持久化),支持多线程抓取,分布式抓取,并支持自动重试.自定义UA/cookie等功能. 实现理念: Maven依赖: <dependency> <groupId>us.codecraft</groupId> <artifactId
-
springBoot+webMagic实现网站爬虫的实例代码
前端时间公司项目需要抓取各类数据,py玩的不6,只好研究Java爬虫方案,做一个总结. 开发环境: springBoot 2.2.6.jdk1.8. 1.导入依赖 <!--WebMagic核心包--> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version&g
-
Java基于jdbc连接mysql数据库操作示例
本文实例讲述了Java基于jdbc连接mysql数据库操作.分享给大家供大家参考,具体如下: import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class MySQLDemo { private Connection conn = null; pri
-
java基于jdbc连接mysql数据库功能实例详解
本文实例讲述了java基于jdbc连接mysql数据库的方法.分享给大家供大家参考,具体如下: 一.JDBC简介 Java 数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法.JDBC也是Sun Microsystems的商标.它JDBC是面向关系型数据库的. 1.JDBC架构: JDBC API支持两层和三层处理模型进行数据库访问,但在一般的JDBC体系结构由
-
Java使用JDBC向MySQL数据库批次插入10W条数据(测试效率)
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(100000),如何提高效率呢? 在JDBC编程接口中Statement 有两个方法特别值得注意: 通过使用addBatch()和executeBatch()这一对方法可以实现批量处理数据. 不过值得注意的是,首先需要在数据库链接中设置手动提交,connection.setAutoCommit(false),然后在执行Statement之后执行connection.commit(). import java.io.Bu
-
Java使用jdbc连接MySQL数据库实例分析
本文实例讲述了Java使用jdbc连接MySQL数据库的方法.分享给大家供大家参考,具体如下: 使用jdbc连接数据库: 可以直接在方法中定义url.user.psd等信息,也可以读取配置文件,但是在web项目中肯定是要使用第二种方式的,为了统一,只介绍第二种方式. 步骤 1.创建配置文件db.properties 无论是eclipse还是myeclipse,在工程下右键->new->file,以properties为后缀名就好了. 配置文件内容: #连接数据库的url,如果主机地址是loca
-
Java之jdbc连接mysql数据库的方法步骤详解
Java:jdbc连接mysql数据库 安装eclipse和mysql的步骤这里不赘述了. 1.一定要下jar包 要想实现连接数据库,要先下载mysql-connector-java-5.1.47(或者其他版本)的jar包.低版本的jar包不会出现时差问题的异常. 建议在下载界面点右边的"Looking for previous GA versions?"下载低版本的. https://www.jb51.net/article/190860.htm我看的是这个教程. 2.mysql前期
-
详解Java使用JDBC连接MySQL数据库
一:什么是数据库,为什么要有数据库? 数据,数据库,数据库管理系统和数据库系统是与数据库技术密切相关的四个基本概念. 数据库相信大家都耳熟能详了,其实数据库顾名思义就是存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的~ 可能有朋友就要打断我施法了,停停停,我们Java程序猿在IDEA里面和控制台你侬我侬,没有对象new个对象存储在内存JVM的堆上就行了,学数据库干啥啊? 这时候我们就需要了解到:内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运
-
Java使用JDBC连接数据库的实现方法
本文实例讲述了Java使用JDBC连接数据库的实现方法,是Java数据库程序设计里非常实用的重要技巧.分享给大家供大家参考.具体如下: JDBC(Java Data Base Connectivity)数据库连接,通常我们在编写web应用或java应用程序要连接数据库时就要使用JDBC.使用JDBC连接数据库一般步骤有: 1.加载驱动程序 Class.forName(driver); 2.创建连接对象 Connection con = DriverManager.getConnection(ur
-
Java爬虫实现Jsoup利用dom方法遍历Document对象
先给出网页地址: https://wall.alphacoders.com/featured.php?lang=Chinese 主要步骤: 利用Jsoup的connect方法获取Document对象 String html = "https://wall.alphacoders.com/featured.php?lang=Chinese"; Document doc = Jsoup.connect(html).get(); 内容过长,就不再显示. 我们以这部分为例: <ul cl