kafka与storm集群环境的安装步骤详解
前言
在开始之前,需要说明下,storm和kafka集群安装是没有必然联系的,我将这两个写在一起,是因为他们都是由zookeeper进行管理的,也都依赖于JDK的环境,为了不重复再写一遍配置,所以我将这两个写在一起。若只需一个,只需挑选自己选择的阅读即可。下面话不多说了,来一起看看详细的介绍吧。
这两者的依赖如下:
- Storm集群:JDK1.8 , Zookeeper3.4,Storm1.1.1;
- Kafa集群 : JDK1.8 ,Zookeeper3.4 ,Kafka2.12;
说明: Storm1.0 和Kafka2.0对JDK要求是1.7以上,Zookeeper3.0以上。
下载地址:
- Zookeeper:https://zookeeper.apache.org/releases.html (本地下载)
- Storm: http://storm.apache.org/downloads.html (本地下载)
- Kafka: http://kafka.apache.org/downloads (本地下载)
JDK安装
每台机器都要安装JDK!!!
说明: 一般CentOS自带了openjdk,但是我们这里使用的是oracle的JDK。所以要写卸载openjdk,然后再安装在oracle下载好的JDK。如果已经卸载,可以跳过此步骤。
首先输入 java -version
查看是否安装了JDK,如果安装了,但版本不适合的话,就卸载

输入
rpm -qa | grep java
查看信息
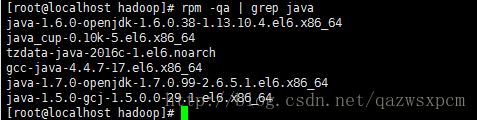
然后输入:
rpm -e --nodeps “你要卸载JDK的信息”
如: rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64

确认没有了之后,解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8。
mv jdk1.8.0_144 /opt/java mv jdk1.8.0_144 jdk1.8
然后编辑 profile 文件,添加如下配置
输入:
vim /etc/profile
添加:
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
添加成功之后,输入
source /etc/profile java -version
查看是否配置成功
Zookeeper 环境安装
1,文件准备
将下载下来的Zookeeper 的配置文件进行解压
在linux上输入:
tar -xvf zookeeper-3.4.10.tar.gz
然后移动到/opt/zookeeper里面,没有就新建,然后将文件夹重命名为zookeeper3.4
输入
mv zookeeper-3.4.10 /opt/zookeeper mv zookeeper-3.4.10 zookeeper3.4
2,环境配置
编辑 /etc/profile 文件
输入:
export ZK_HOME=/opt/zookeeper/zookeeper3.4
export PATH=.:${JAVA_HOME}/bin:${ZK_HOME}/bin:$PATH
输入:
source /etc/profile
使配置生效
3,修改配置文件
3.3.1 创建文件和目录
在集群的服务器上都创建这些目录
mkdir /opt/zookeeper/data mkdir /opt/zookeeper/dataLog
并且在/opt/zookeeper/data目录下创建myid文件
输入:
touch myid
创建成功之后,更改myid文件。
我这边为了方便,将master、slave1、slave2的myid文件内容改为1,2,3
3.3.2 新建zoo.cfg
切换到/opt/zookeeper/zookeeper3.4/conf 目录下
如果没有 zoo.cfg 该文件,就复制zoo_sample.cfg文件并重命名为zoo.cfg。
修改这个新建的zoo.cfg文件
dataDir=/opt/zookeeper/data dataLogDir=/opt/zookeeper/dataLog server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888
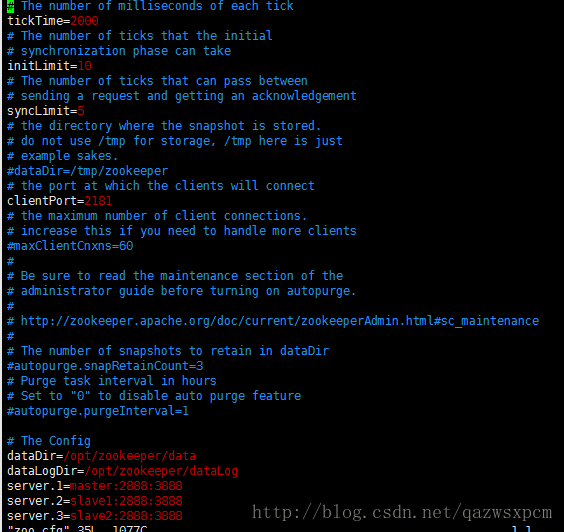
说明:client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。server.1中的这个1需要和master这个机器上的dataDir目录中的myid文件中的数值对应。server.2中的这个2需要和slave1这个机器上的dataDir目录中的myid文件中的数值对应。server.3中的这个3需要和slave2这个机器上的dataDir目录中的myid文件中的数值对应。当然,数值你可以随便用,只要对应即可。2888和3888的端口号也可以随便用,因为在不同机器上,用成一样也无所谓。
1.tickTime:CS通信心跳数
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=10
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=5
依旧将zookeeper传输到其他的机器上,记得更改 /opt/zookeeper/data 下的myid,这个不能一致。
输入:
scp -r /opt/zookeeper root@slave1:/opt scp -r /opt/zookeeper root@slave2:/opt
4、启动zookeeper
因为zookeeper是选举制,它的主从关系并不是像hadoop那样指定的,具体可以看官方的文档说明。
成功配置zookeeper之后,在每台机器上启动zookeeper。
切换到zookeeper目录下
cd /opt/zookeeper/zookeeper3.4/bin
输入:
zkServer.sh start
成功启动之后
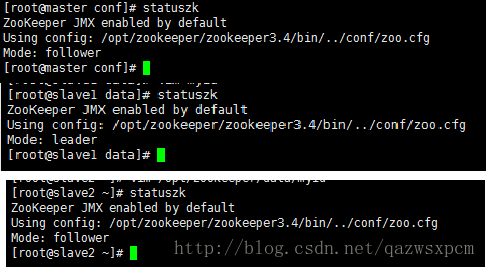
查看状态输入:
zkServer.sh status
可以查看各个机器上zookeeper的leader和follower
Storm 环境安装
1,文件准备
将下载下来的storm的配置文件进行解压
在linux上输入:
tar -xvf apache-storm-1.1.1.tar.gz
然后移动到/opt/storm里面,没有就新建,然后将文件夹重命名为storm1.1
输入
mv apache-storm-1.1.1 /opt/storm mv apache-storm-1.1.1 storm1.1
编辑 /etc/profile 文件
添加:
export STORM_HOME=/opt/storm/storm1.1
export PATH=.:${JAVA_HOME}/bin:${ZK_HOME}/bin:${STORM_HOME}/bin:$PATH
输入 storm version 查看版本信息
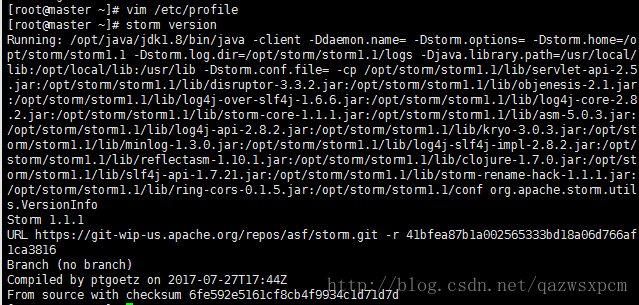
3,修改配置文件
编辑 storm/conf 的 storm.yarm。
进行如下编辑:
输入:
vim storm.yarm
storm.zookeeper.servers: - "master" - "slave1" - "slave2" storm.local.dir: "/root/storm" nimbus.seeds: ["master"] supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
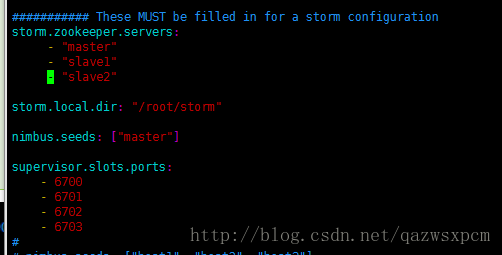
说明:
1、storm.zookeeper.servers是指定zookeeper的服务地址。
因为storm的存储信息在zookeeper上,所以要配置zookeeper的服务地址。如果zookeeper是单机就只用指定一个!
2、storm.local.dir 表示存储目录。
Nimbus和Supervisor守护进程需要在本地磁盘上存储一个目录来存储少量的状态(比如jar,confs等等)。可以在每台机器创建,并给于权限。
3、nimbus.seeds 表示候选的主机。
worker需要知道那一台机器是主机候选(zookeeper集群是选举制),从而可以下载 topology jars 和confs。
4、supervisor.slots.ports 表示worker 端口。
对于每一个supervisor机器,我们可以通过这项来配置运行多少worker在这台机器上。每一个worker使用一个单独的port来接受消息,这个端口同样定义了那些端口是开放使用的。如果你在这里定义了5个端口,就意味着这个supervisor节点上最多可以运行5个worker。如果定义3个端口,则意味着最多可以运行3个worker。在默认情况下(即配置在defaults.yaml中),会有有四个workers运行在 6700, 6701, 6702, and 6703端口。
supervisor并不会在启动时就立即启动这四个worker。而是接受到分配的任务时,才会启动,具体启动几个worker也要根据我们Topology在这个supervisor需要几个worker来确定。如果指定Topology只会由一个worker执行,那么supervisor就启动一个worker,并不会启动所有。
注: 这些配置前面不要有空格!!!,不然会报错。 这里使用的是主机名(做了映射),也可以使用IP。实际的以自己的为准。
可以使用scp命令或者ftp软件将storm复制到其他机器上

成功配置之后,然后就可以启动Storm了,不过要确保JDK、Zookeeper已经正确安装,并且Zookeeper已经成功启动。
4,启动Storm
切换到 storm/bin 目录下
在主节点(master)启动输入:
storm nimbus >/dev/null 2>&1 &
访问web界面(master)输入:
storm ui
从节点(slave1,slave2)输入:
storm supervisor >/dev/null 2>&1 &
在浏览器界面输入: 8080端口
成功打开该界面,表示环境配置成功:

kafka的环境安装
kafka是一个高吞吐量的流式分布式消息系统,用来处理活动流数据,比如网页的访问量pm,日志等,既能够实时处理大数据信息也能离线处理。
1,文件准备
将下载下来的Kafka的配置文件进行解压
在linux上输入:
tar -xvf kafka_2.12-1.0.0.tgz
然后移动到/opt/kafka里面,没有就新建,然后将文件夹重命名为kafka2.12
输入
mv kafka_2.12-1.0.0 /opt/kafka mv kafka_2.12-1.0.0 kafka2.12
2,环境配置
编辑 /etc/profile 文件
输入:
export KAFKA_HOME=/opt/kafka/kafka2.12
export PATH=.:${JAVA_HOME}/bin:${KAFKA_HOME}/bin:${ZK_HOME}/bin:$PATH
输入:
source /etc/profile
使配置生效
3,修改配置文件
注:其实要说的话,如果是单机的话,kafka的配置文件可以不用修改,直接到bin目录下启动就可以了。但是我们这里是集群,所以稍微改下就可以了。
切换到kafka/config 目录下
编辑server.properties 文件
需要更改的是Zookeeper的地址:
找到Zookeeper的配置,指定Zookeeper集群的地址,设置如下修改就可以了
zookeeper.connect=master:2181,slave1:2181,slave2:2181 zookeeper.connection.timeout.ms=6000
其它可以选择更改的有
1 ,num.partitions 表示指定的分区,默认为1
2,log.dirs kafka的日志路径,这个按照个人需求更改就行
...
注:还有其它的配置,可以查看官方文档,如果没有特别要求,使用默认的就可以了。
配置好之后,记得使用scp 命令传输到其它的集群上!
4,启动kafka
集群每台集群都需要操作!
切换到kafka/bin 目录下
输入:
kafka-server-start.sh
然后输入jps名称查看是否成功启动:
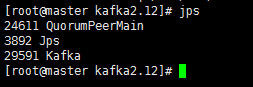
成功启动之后,可以进行简单的测试下
首先创建个topic
输入:
kafka-topics.sh --zookeeper master:2181 --create --topic t_test --partitions 5 --replication-factor 2
说明: 这里是创建了一个名为 t_test 的topic,并且指定了5个分区,每个分区指定了2个副本数。如果不指定分区,默认的分区就是配置文件配置的。
然后进行生产数据
输入:
kafka-console-producer.sh --broker-list master:9092 --topic t_test

可以使用进行Ctrl+D 退出
然后我们再打开一个xshell窗口
进行消费
输入:
kafka-console-consumer.sh --zookeeper master:2181 --topic t_test --from-beginning

可以使用进行Ctrl+C 退出
可以看到数据已经正常消费了。
5,kafka的一些常用命令
1.启动和关闭kafka
bin/kafka-server-start.sh config/server.properties >>/dev/null 2>&1 & bin/kafka-server-stop.sh
2.查看kafka集群中的消息队列和具体队列
查看集群所有的topic
kafka-topics.sh --zookeeper master:2181,slave1:2181,slave2:2181 --list
查看一个topic的信息
kafka-topics.sh --zookeeper master:2181 --describe --topic t_test
3.创建Topic
kafka-topics.sh --zookeeper master:2181 --create --topic t_test --partitions 5 --replication-factor 2
4.生产数据和消费数据
kafka-console-producer.sh --broker-list master:9092 --topic t_test
Ctrl+D 退出
kafka-console-consumer.sh --zookeeper master:2181 --topic t_test --from-beginning
Ctrl+C 退出
5.kafka的删除命令
kafka-topics.sh --delete --zookeeper master:2181 --topic t_test
6,添加分区
kafka-topics.sh --alter --topict_test --zookeeper master:2181 --partitions 10
其它
Storm环境搭建参考官方文档:http://storm.apache.org/releases/1.1.1/Setting-up-a-Storm-cluster.html
Kafka环境搭建参考官方文档:http://kafka.apache.org/quickstart
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
您可能感兴趣的文章:
- Kafka使用Java客户端进行访问的示例代码
- Java API方式调用Kafka各种协议的方法
- Kafka简单客户端编程实例
- kafka生产实践(详解)
- Kafka使用入门教程
- Kafka利用Java实现数据的生产和消费实例教程
相关推荐
-

Kafka简单客户端编程实例
今天,我们给大家带来一篇如何利用Kafka的API进行客户端编程的文章,这篇文章很简单,就是利用Kafka的API创建一个生产者和消费者,生产者不断向Kafka写入消息,消费者则不断消费Kafka的消息.下面是具体的实例代码. 一.创建配置类Config 这个类很简单,只是存放了两个常量,一个是话题TOPIC,一个是线程数THREADS package com.lya.kafka; /** * 配置项 * @author liuyazhuang * */ public class Config
-
Kafka利用Java实现数据的生产和消费实例教程
前言 在上一篇中讲述如何搭建kafka集群,本篇则讲述如何简单的使用 kafka .不过在使用kafka的时候,还是应该简单的了解下kafka. Kafka的介绍 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Kafka 有如下特性: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能. 高吞吐率.即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输. 支持Kafka Serv
-
kafka生产实践(详解)
1.引言 最近接触到一个APP流量分析的项目,类似于友盟.涉及到几个C端(客户端)高并发的接口,这几个接口主要用于C端数据的提交.在没有任何缓冲的情况下,一个接口涉及到5张表的提交.压测的结果很不理想,主要瓶颈就在与RDS的交互. 一台双核,16G机子,单实例,jdbc最大连接数100,吞吐量竟然只有50TPS. 能想到的改造方案就是引入一层缓冲,让C端接口不与RDS直接交互,很自然就想到了rabbitmq,但是rabbitmq对分布式的支持比较一般,我们的数据体量也比较大,所以我们借鉴了友盟,
-
Kafka使用入门教程第1/2页
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topic为单位进行归纳. •将向Kafka topic发布消息的程序成为producers. •将预订topics并消费消息的程序成为consumer. •Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker. producers通过网络将消息发送到Kafka集群,集群
-
Kafka使用Java客户端进行访问的示例代码
本文环境如下: 操作系统:CentOS 6 32位 JDK版本:1.8.0_77 32位 Kafka版本:0.9.0.1(Scala 2.11) 1. maven依赖包 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.9.0.1</version> </dependen
-
Java API方式调用Kafka各种协议的方法
众所周知,Kafka自己实现了一套二进制协议(binary protocol)用于各种功能的实现,比如发送消息,获取消息,提交位移以及创建topic等.具体协议规范参见:Kafka协议 这套协议的具体使用流程为: 1.客户端创建对应协议的请求 2.客户端发送请求给对应的broker 3.broker处理请求,并发送response给客户端 虽然Kafka提供的大量的脚本工具用于各种功能的实现,但很多时候我们还是希望可以把某些功能以编程的方式嵌入到另一个系统中.这时使用Java API的方式就显
-
kafka与storm集群环境的安装步骤详解
前言 在开始之前,需要说明下,storm和kafka集群安装是没有必然联系的,我将这两个写在一起,是因为他们都是由zookeeper进行管理的,也都依赖于JDK的环境,为了不重复再写一遍配置,所以我将这两个写在一起.若只需一个,只需挑选自己选择的阅读即可.下面话不多说了,来一起看看详细的介绍吧. 这两者的依赖如下: Storm集群:JDK1.8 , Zookeeper3.4,Storm1.1.1: Kafa集群 : JDK1.8 ,Zookeeper3.4 ,Kafka2.12: 说明: Sto
-
Spark学习笔记 (二)Spark2.3 HA集群的分布式安装图文详解
本文实例讲述了Spark2.3 HA集群的分布式安装.分享给大家供大家参考,具体如下: 一.下载Spark安装包 1.从官网下载 http://spark.apache.org/downloads.html 2.从微软的镜像站下载 http://mirrors.hust.edu.cn/apache/ 3.从清华的镜像站下载 https://mirrors.tuna.tsinghua.edu.cn/apache/ 二.安装基础 1.Java8安装成功 2.zookeeper安装成功 3.hadoo
-
ceph集群RadosGW对象存储使用详解
目录 什么是对象存储 ceph对象存储的构成 RadosGW存储池作用 RadosGW常用操作详解 操纵radosgw 需要先安装好python3环境,以及python的boto模块 python脚本编写 一个完整的ceph集群,可以提供块存储.文件系统和对象存储. 本节主要介绍对象存储RadosGw功能如何灵活的使用 集群背景: $ ceph -s cluster: id: f0a8789e-6d53-44fa-b76d-efa79bbebbcf health: HEALTH_OK servi
-
Kubernetes集群模拟删除k8s重装详解
目录 一.系统环境 二.前言 三.重装Kubernetes集群 3.1 环境介绍 3.2 删除k8s所有节点(node) 3.3 kubeadm初始化 3.4 添加worker节点到k8s集群 3.5 安装calico 一.系统环境 服务器版本 docker软件版本 CPU架构 CentOS Linux release 7.4.1708 (Core) Docker version 20.10.12 x86_64 二.前言 当我们安装部署好一套Kubernetes集群,使用一段时间之后可能会有重新
-
tomcat 集群监控与弹性伸缩详解
目录 如何给 tomcat 配置合适的线程池 如何监控 tomcat 线程池的工作情况 tomcat 线程池扩缩容 tomcat 是如何避免原生线程池的缺陷的 如何给 tomcat 配置合适的线程池 任务分为 CPU 密集型和 IO 密集型 对于 CPU 密集型的应用来说,需要大量 CPU 计算速度很快,线程池如果过多,则保存和切换上下文开销过高反而会影响性能,可以适当将线程数量调小一些 对于 IO 密集型应用来说常见于普通的业务系统,比如会去查询 mysql.redis 等然后在内存中做简单的
-
MySql 5.7.14 解压版安装步骤详解
下面主要分为五大步给大家介绍mySql 5.7.14 解压版安装教程.感兴趣的朋友一起看看吧. 第一步:下载最近的MySQL文件并且解压: 下载最新版的MySQL–mysql-5.7.12下载地址 将下载到的文件解压缩到自己喜欢的位置,例如我自己的位置是D:\MySQL\mysql-5.7.12-winx64 第二步:配置环境变量 这里不多说,bin目录配置到path下面就行了. 第三步:添加配置文件 直接复制一个解压路径下面的 my-default.ini文件,重命名为my.ini然后编辑该文
-
python的mysqldb安装步骤详解
python的mysqldb安装步骤详解 安装MySQLdb: 一. 什么是MySQLdb? 解释:MySQLdb是Python操作MySQL的一个接口包.这里要理解一个概念,python操作数据库,都是需要一个类似MySQLdb这样的中间层,这些中间层抽象了具体的实现,提供了统一的API供开发者使用. 二. 如何安装MySQLdb? python2环境下: sudo pip install MySQL-python. MySQL-python目前暂时还不支持python3,有些小问题,可以安装
-
python3.8下载及安装步骤详解
1.操作系统:Windows7 64bit Python版本:3.8下载地址:https://www.python.org/downloads/release/python-380/,选择下方的Windows x86-64 executable installer 2.安装步骤: 双击安装文件python-3.8.0-amd64.exe 勾选下方"Add Python 3.8 to PATH",并选择"Customize installation" 3.把Optio
-
Python入门开发教程 windows下搭建开发环境vscode的步骤详解
目录 一.环境介绍 二. 搭建python开发环境 2.1 Python版本介绍 2.2 在windows下安装Python环境 2.3 windows下安装VSCode代码编辑器 一.环境介绍 操作系统: win10 64位 python版本: 3.8 IDE: 采用vscode 用到的相关安装包CSDN打包下载地址: http://xiazai.jb51.net/202107/yuanma/Pytho_jb51.rar 二. 搭建python开发环境 2.1 Python版本介绍 因为Pyt
-
Linux Redis 的安装步骤详解
Linux Redis 的安装步骤详解 前言: Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询. redis 是完全开源免费的,是一个高性能的key-value数据库.Re