从列表或字典创建Pandas的DataFrame对象的方法

介绍
每当我使用pandas进行分析时,我的第一个目标是使用众多可用选项中的一个将数据导入Pandas的DataFrame 。
对于绝大多数情况下,我使用的 read_excel , read_csv 或 read_sql 。
但是,有些情况下我只需要几行数据或包含这些数据里的一些计算。
在这些情况下,了解如何从标准python列表或字典创建DataFrames会很有帮助。
基本过程并不困难,但因为有几种不同的选择,所以有助于理解每种方法的工作原理。
我永远记不住我是否应该使用 from_dict , from_records , from_items 或默认的 DataFrame 构造函数。
通常情况下,通过一些反复试验和错误,我能搞定它。但由于它仍然让我感到困惑,我想我会通过以下几个例子来澄清这些不同的方法。
在本文的最后,我简要介绍了在生成Excel报表时如何使用它。
从Python的数据结构中生成DataFrame
您可以使用多种方法来获取标准python数据结构并创建Pandas的DataFrame。
出于这些示例的目的,我将为3个虚构公司创建一个包含3个月销售信息的DataFrame。

字典
在展示下面的示例之前,我假设已执行以下导入:
import pandas as pd from collections import OrderedDict from datetime import date
从python创建DataFrame的“默认”方式是使用字典列表。在这种情况下,每个字典键用于列标题。将自动创建默认索引:
sales = [{'account': 'Jones LLC', 'Jan': 150, 'Feb': 200, 'Mar': 140},
{'account': 'Alpha Co', 'Jan': 200, 'Feb': 210, 'Mar': 215},
{'account': 'Blue Inc', 'Jan': 50, 'Feb': 90, 'Mar': 95 }]
df = pd.DataFrame(sales)

如您所见,这种方法非常“面向行”。如果您想以“面向列”的方式创建DataFrame,您可以使用 from_dict
sales = {'account': ['Jones LLC', 'Alpha Co', 'Blue Inc'],
'Jan': [150, 200, 50],sheng cheng
'Feb': [200, 210, 90],
'Mar': [140, 215, 95]}
df = pd.DataFrame.from_dict(sales)
使用此方法,您可以获得与上面相同的结果。需要考虑的关键点是哪种方法更容易理解您独特的使用场景。
有时,以面向行的方式获取数据更容易,而其他时候以列为导向的则更容易。
了解这些选项将有助于使您的代码更简单,更易于理解,以满足您的特定需求。
大多数人会注意到列的顺序看起来不对。这个问题出现的原因是标准的python字典不保留其键的顺序。
如果要控制列顺序,则有两种方式。
第一种,您可以手动重新排序列:
df = df[['account', 'Jan', 'Feb', 'Mar']]
或者你可以使用python中的OrderedDict 创建你的有序字典 。
sales = OrderedDict([ ('account', ['Jones LLC', 'Alpha Co', 'Blue Inc']),
('Jan', [150, 200, 50]),
('Feb', [200, 210, 90]),
('Mar', [140, 215, 95]) ] )
df = pd.DataFrame.from_dict(sales)
这两种方法都会按照您可能期望的顺序为您提供结果。

由于我在下面概述的原因,我倾向于专门重新排序我的列,尽管使用OrderedDict一直是一个很好理解的选项。
列表
从python创建DataFrame的另一个选择是将数据包含在列表结构中。
第一种方法是使用pandas进行面向行的方法 from_records 。此方法类似于字典方法,但您需要显式调出列标签。
sales = [('Jones LLC', 150, 200, 50),
('Alpha Co', 200, 210, 90),
('Blue Inc', 140, 215, 95)]
labels = ['account', 'Jan', 'Feb', 'Mar']
df = pd.DataFrame.from_records(sales, columns=labels)
第二种方法是 from_items 面向列的,实际上看起来类似于 OrderedDict 上面的例子。
sales = [('account', ['Jones LLC', 'Alpha Co', 'Blue Inc']),
('Jan', [150, 200, 50]),
('Feb', [200, 210, 90]),
('Mar', [140, 215, 95]),
]
df = pd.DataFrame.from_items(sales)
这两个示例都将生成以下DataFrame:

各种选项的直观总结
为了保持各种选项在我的脑海中清晰,我将这个简单的图形放在一起,以显示字典与列表选项以及行与列导向的方法。
这是一个2X2的网格,所以我希望所有来询问的人都留下深刻的印象!
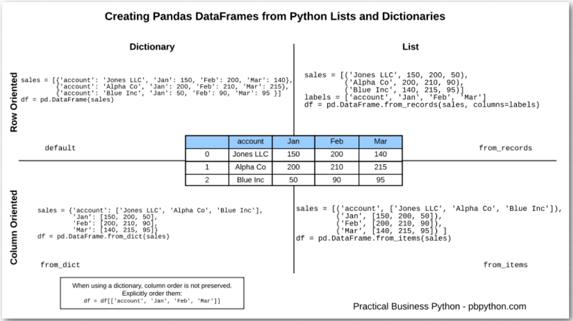
为简单起见,我没有展示 OrderedDict 方法,因为这种 from_items 方法可能更像是一个现实世界的解决方案。
如果这有点难以阅读,您也可以获得PDF版本。
简单的例子
对于一个简单的概念,这似乎有很多解释。
但是,我经常使用这些方法来构建小型DataFrame,并将其与更复杂的分析结合起来。
举一个例子,假设我们要保存我们的DataFrame并包含一个页脚,以便我们知道它何时被创建以及它是由谁创建的。
如果我们填充DataFrame并将其写入Excel比我们尝试将单个单元格写入Excel更容易。
拿我们现有的DataFrame:
sales = [('account', ['Jones LLC', 'Alpha Co', 'Blue Inc']),
('Jan', [150, 200, 50]),
('Feb', [200, 210, 90]),
('Mar', [140, 215, 95]),
]
df = pd.DataFrame.from_items(sales)
现在构建一个页脚(以列为导向):
from datetime import date
create_date = "{:%m-%d-%Y}".format(date.today())
created_by = "CM"
footer = [('Created by', [created_by]), ('Created on', [create_date]), ('Version', [1.1])]
df_footer = pd.DataFrame.from_items(footer)

合并进入一个Excel中的一个sheet:
writer = pd.ExcelWriter('simple-report.xlsx', engine='xlsxwriter')
df.to_excel(writer, index=False)
df_footer.to_excel(writer, startrow=6, index=False)
writer.save()
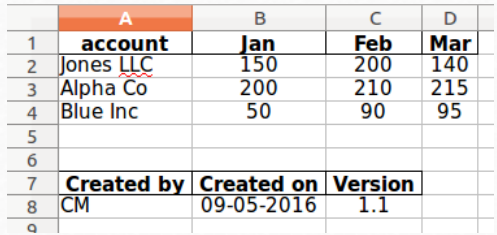
这里的秘诀是使用 startrow 在销售数据框架下面写入页脚DataFrame。还有一个相应的startcol,所以你可以控制成为你想要的列布局。
这使得基本 to_excel 功能具有很大的灵活性。
总结
大多数Pandas用户很快就熟悉了电子表格,CSV和SQL数据的摄取。
但是,有时您会在基本列表或字典中包含数据并希望填充DataFrame。
Pandas提供了几种选择,但可能并不总是立即明确何时使用哪种选择。
没有一种方法是“最好的”,它实际上取决于您的需求。
我倾向于喜欢基于列表的方法,因为我通常关心排序,列表确保我保留顺序。
最重要的是要知道这些选项是可用的,这样您就可以聪明地使用最简单的选项来满足您的特定情况。
从表面上看,这些代码样例看似简单,但我发现使用这些方法生成快速的信息片非常常见,他们可以增加或澄清更复杂的分析。
DataFrame中数据的好处在于它很容易转换为其他格式,如Excel,CSV, HTML,LaTeX等。
这种灵活性对于临时报告生成非常方便。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-
Python中pandas模块DataFrame创建方法示例
本文实例讲述了Python中pandas模块DataFrame创建方法.分享给大家供大家参考,具体如下: DataFrame创建 1. 通过列表创建DataFrame 2. 通过字典创建DataFrame 3. 通过Numpy数组创建DataFrame DataFrame这种列表式的数据结构和Excel工作表非常类似,其设计初衷是讲Series的使用场景由一维扩展到多维. DataFrame由按一定顺序的多列数据组成,各列的数据类型可以有所不同(数值.字符串.布尔值). Series对象的Ind
-
pandas创建新Dataframe并添加多行的实例
处理数据的时候,偶然遇到要把一个Dataframe中的某些行添加至一个空白的Dataframe中的问题. 最先想到的方法是创建Dataframe,从原有的Dataframe中逐行筛选出指定的行(类型为pandas的Series),并使用append方法进行添加.这种方法速度很慢,而且添加之后总会出现奇怪的问题,数据类型也不对. 较快的方法为,首先创建空的list,对原有的Dataframe进行逐行筛选,筛选出的行转化为dict类型,append进list中.全部添加完毕后,再将整个list转化为
-
利用Pandas 创建空的DataFrame方法
平时写pyhton的时候习惯初始化一些list啊,tuple啊,dict啊这样的.一用到Pandas的DataFrame数据结构也就总想着初始化一个空的DataFrame,虽然没什么太大的用处,不过还是记录一下: # 创建一个空的 DataFrame df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D']) 上面创建的DataFrame有4列,每一行没有成员是空的. 输出一下结果: Empty DataFrame Columns: [A, B,
-
从列表或字典创建Pandas的DataFrame对象的方法
介绍 每当我使用pandas进行分析时,我的第一个目标是使用众多可用选项中的一个将数据导入Pandas的DataFrame . 对于绝大多数情况下,我使用的 read_excel , read_csv 或 read_sql . 但是,有些情况下我只需要几行数据或包含这些数据里的一些计算. 在这些情况下,了解如何从标准python列表或字典创建DataFrames会很有帮助. 基本过程并不困难,但因为有几种不同的选择,所以有助于理解每种方法的工作原理. 我永远记不住我是否应该使用 from_dic
-
pandas如何使用列表和字典创建 Series
目录 01 使用列表创建 Series 02 使用 name 参数创建 Series 03 使用简写的列表创建 Series 04 使用字典创建 Series 05 如何使用 Numpy 函数创建 Series 06 如何获取 Series 的索引和值 07 如何在创建 Series 时指定索引 08 如何获取 Series 的大小和形状 09 如何获取 Series 开始或末尾几行数据 10 使用切片获取 Series 子集 前言: Pandas 纳入了大量库和一些标准的数据模型,提供了高效地
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
pandas修改DataFrame列名的方法
在做数据挖掘的时候,想改一个DataFrame的column名称,所以就查了一下,总结如下: 数据如下: >>>import pandas as pd >>>a = pd.DataFrame({'A':[1,2,3], 'B':[4,5,6], 'C':[7,8,9]}) >>> a A B C 0 1 4 7 1 2 5 8 2 3 6 9 方法一:暴力方法 >>>a.columns = ['a','b','c'] >>
-
使用pandas的DataFrame的plot方法绘制图像的实例
使用了pandas的Series方法绘制图像体验之后感觉直接用matplotlib的功能好用了不少,又试用了DataFrame的方法之后发现这个更加人性化. 写代码如下: from pandas import Series,DataFrame from numpy.random import randn import numpy as np import matplotlib.pyplot as plt df = DataFrame(randn(10,5),columns=['A','B','C
-
Python中使用Counter进行字典创建以及key数量统计的方法
这里的Counter是指collections中的Counter,通过Counter可以实现字典的创建以及字典key出现频次的统计.然而,使用的时候还是有一点需要注意的小事项. 使用Counter创建字典通常有4种方式.其中,第一种方式是不带任何参数创建一个空的字典.剩下的三种分别在下面通过简单的代码进行演示. 创建方法2示范代码: need python.' cell1 =(2,2,3,5,5,4,3,2,1,1,2,3,3,2,2) list1 =[2,2,3,5,5,4,3,2,1,1,2
-
从DataFrame中提取出Series或DataFrame对象的方法
如下所示: df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'], 'data1': range(6)}) type(df['data1']) pandas.core.series.Series type(df[['data1']]) pandas.core.frame.DataFrame 以上这篇从DataFrame中提取出Series或DataFrame对象的方法就是小编分享给大家的全部内容了,
-

Pandas数据结构详细说明及如何创建Series,DataFrame对象方法
目录 1. Pandas的两种数据类型 2. Series类型 通过numpy array 通过Python字典 通过标量值(Scalar) name属性 3. DataFrame类型 通过包含列表的Python List 通过包含Python 字典的Python List 通过Series 在网络上的Pandas教程中,很多都提到了如何使用Pandas将已有的数据(如csv,如hdfs等)直接加载成Pandas数据对象,然后在其基础上进行数据分析操作,但是,很多时候,我们需要自己创建Panda
-
详细介绍pandas的DataFrame的append方法使用
官方文档介绍链接:append方法介绍 DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None) 功能说明:向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加 other:DataFrame.series.dict.list这样的数据结构 ignore_index:默认值为False,如果为True则不使用index标签 verify_int
-
Pandas之DataFrame对象的列和索引之间的转化
约定: import pandas as pd DataFrame对象的列和索引之间的转化 我们常常需要将DataFrame对象中的某列或某几列作为索引,或者将索引转化为对象的列.pandas提供了set_index()/reset_index() 来供我们使用. 一.列转化为索引 df1=pd.DataFrame({'X':range(5),'Y':range(5),'S':list("aaabb"),'Z':[1,1,2,2,2]}) df1 代码结果: S X Y Z 0 a 0