基于Python的SQL Server数据库实现对象同步轻量级
缘由
日常工作中经常遇到类似的问题:把某个服务器上的某些指定的表同步到另外一台服务器。
类似需求用SSIS或者其他ETL工作很容易实现,比如用SSIS的话,就会会存在相当一部分反复的手工操作。
建源的数据库信息,目标的数据库信息,如果是多个表,需要一个一个地拉source和target,然后一个一个地mapping,然后运行实现数据同步。
然后很可能,这个workflow使用也就这么一次,就寿终正寝了,却一样要浪费时间去做这个ETL。
快速数据同步实现
于是在想,可不可能快速实现类似需求,尽最大程度减少重复的手工操作?类似基于命令行的方式,简单快捷,不需要太多的手动操作。
于是就有了本文,基于Python(目的是顺便熟悉一下Python的语法),快速实现SQL Server的数据库之间的数据同步操作,后面又稍微扩展了一下,可以实现不同服务器的数据库之间的表结构,表对应的数据,存储过程,函数,用户自定义类型表(user define table type)的同步
目前支持在两个SQL Server数据源之间:每次同步一张或者多张表/存储过程,也可以同步整个数据库的所有表/存储过程(以及表/存储过程依赖的其他数据库对象)。
支持sqlserver2012以上版本
需要考虑到一些基本的校验问题:在源服务器上,需要同步的对象是否存在,或者输入的对象是否存在于源服务器的数据库里。
在目标服务器上,对于表的同步:
1,表的存在依赖于schema,需要考虑到表的schema是否存在,如果不存在先在target库上创建表对应的schema
2,target表中是否有数据?如果有数据,是否以覆盖的方式执行
对于存储过程的同步:
1,类似于表,需要考虑存储过程的schema是否存在,如果不存在先在target库上创建表对应的schema
2,类似于表,arget数据库中是否已经存在对应的存储过程,是否以覆盖的方式执行
3,存储过程可能依赖于b表,某些函数,用户自定义表变量等等,同步存储过程的时候需要先同步依赖的对象,这一点比较复杂,实现过程中遇到在很多很多的坑
可能存在对象A依赖于对象B,对象B依赖于对象C……,这里有点递归的意思
这一点导致了重构大量的代码,一开始都是直来直去的同步,无法实现这个逻辑,切实体会到代码的“单一职责”原则
参数说明
参数说明如下,大的包括四类:
1,源服务器信息 (服务器地址,实例名,数据库名称,用户名,密码),没有用户名密码的情况下,使用windows身份认证模式
2,目标服务器信息(服务器地址,实例名,数据库名称,用户名,密码),没有用户名密码的情况下,使用windows身份认证模式
3,同步的对象类型以及对象
4,同步的对象在目标服务器上存在的情况下,是否强制覆盖

其实在同步数据的时候,也可以把需要同步的行数提取出来做参数,比较简单,这里暂时没有做。
比如需要快速搭建一个测试环境,需要同步所有的表结构和每个表的一部分数据即可。
表以及数据同步
表同步的原理是,创建目标表,遍历源数据的表,生成insert into values(***),(***),(***)格式的sql,然后插入目标数据库,这里大概步骤如下:
1,表依赖于schema,所以同步表之前先同步schema
2,强制覆盖的情况下,会drop掉目标表(如果存在的话),防止目标表与源表结构不一致,非强制覆盖的情况下,如果字段不一致,则抛出异常
3,同步表结构,包括字段,索引,约束等等,但是无法支持外键,刻意去掉了外键,想想为什么?因吹斯汀。
4,需要筛选出来非计算列字段,insert语句只能是非计算列字段(又导致重构了部分代码)
5,转义处理,在拼凑SQL的时候,需要进行转义处理,否则会导致SQL语句错误,目前处理了字符串中的'字符,二进制字段,时间字段的转义处理(最容易发生问题的地方)
6,鉴于insert into values(***),(***),(***)语法上允许的最大值是1000,因此每生成1000条数据,就同步一次
7,自增列的identity_insert 标识打开与关闭处理
使用如下参数,同步源数据库的三张表到目标数据库,因为这里是在本机命名实例下测试,因此实例名和端口号输入
执行同步的效果
说明:
1,如果输入obj_type="tab" 且-obj=为None的情况下,会同步源数据库中的所有表。
2,这个效率取决于机器性能和网络传输,本机测试的话,每秒中可以提交3到4次,也就是每秒钟可以提交3000~4000行左右的数据。
已知的问题:
1,当表的索引为filter index的时候,无法生成包含where条件的索引创建语句,那个看起来蛋疼的表结构导出语句,暂时没时间改它。
2,暂时不支持其他少用的类型字段,比如地理空间字段什么的。
存储过程对象的同步
存储过程同步的原理是,在源数据库上生成创建存储过程的语句,然后写入目标库,这里大概步骤如下:
1,存储过程依赖于schema,所以同步存储过程之前先同步schema(同表)
2,同步的过程会检查依赖对象,如果依赖其他对象,暂停当前对象同步,先同步依赖对象
3,重复第二步骤,直至完成
4,对于存储过程的同步,如果是强制覆盖的话,强制覆盖仅仅对存储过程自己生效(删除&重建),对依赖对象并不生效,如果依赖对象不存在,就创建,否则不做任何事情
使用如下参数,同步源数据库的两个存储过程到目标数据库,因为这里是在本机命名实例下测试,因此实例名和端口号输入
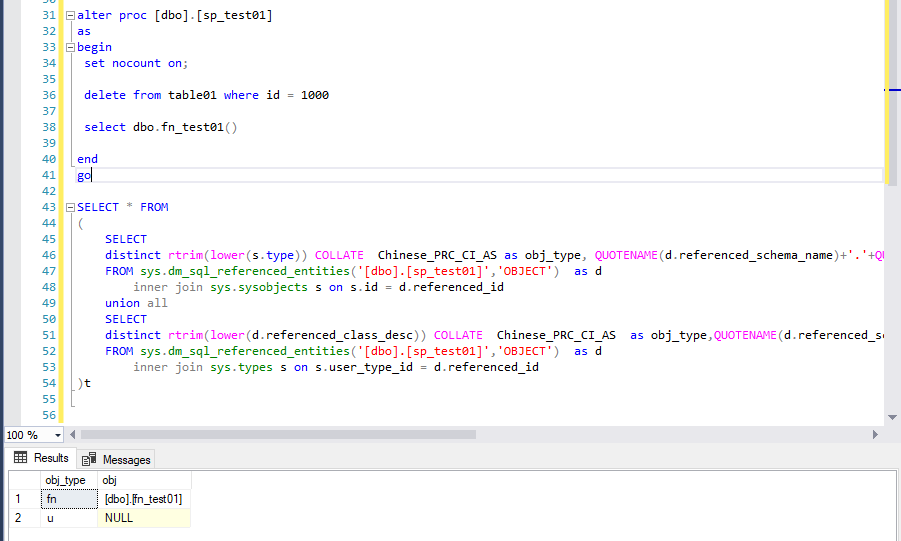
说明:测试要同步的存储过程之一为[dbo].[sp_test01],它依赖于其他两个对象:dbo.table01和dbo.fn_test01()
create proc [dbo].[sp_test01] as begin set no count on; delete from dbo.table01 where id = 1000 select dbo.fn_test01() end
而dbo.fn_test01()的如下,依赖于另外一个对象:dbo.table02
create function [dbo].[fn_test01] ( ) RETURNS int AS BEGIN declare @count int = 0 select @count = count(1) from dbo.table02 return @count END
因此,这个测试的[dbo].[sp_test01]就依赖于其他对象,如果其依赖的对象不存在,同步的时候,仅仅同步这个存储过程本身,是没有意义的
同步某一个对象的依赖对象,使用如下SQL查出来对象依赖信息,因此这里就层层深入,同步依赖对象。
这里就类似于同步A的时候,A依赖于B和C,然后停止同步A,先同步B和C,同步B或者C的时候,可能又依赖于其他对象,然后继续先同步其依赖对象。
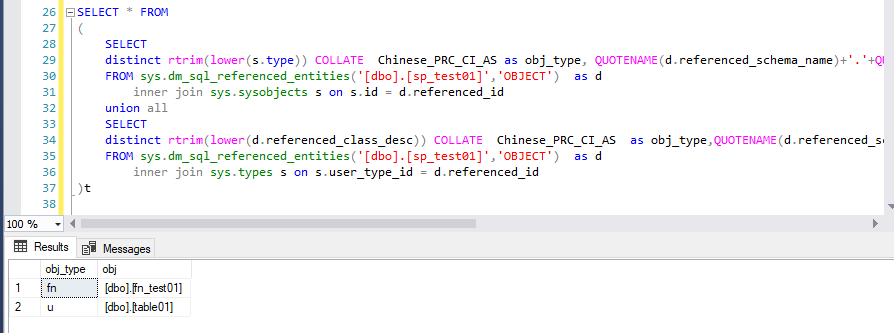
效果如下
如果输入obj_type="sp" 且-obj=为None的情况下,会同步源数据库中的所有存储过程以及其依赖对象
已知的问题:
1,加密的存储过程或者函数是无法实现同步的,因为无法生成创建对象的脚本
1,table type的同步也是一个蛋疼的过程,目前支持,但是支持的并不好,原因是创建table type之前,先删除依赖于table type的对象,否则无法删除与创建。
特别说明
依赖对象的解决,还是比较蛋疼的
如果在默认schema为dbo的对象,在存储过程或者函数中没有写schema(参考如下修改后的sp,不写相关表的schema dbo,dbo.test01==>test01),
使用 sys.dm_sql_referenced_entities这个系统函数是无法找到其依赖的对象的,奇葩的是可以找到schema的类型,却没有返回对象本身。
这一点导致在代码中层层深入,进行了长时间的debug,完全没有想到这个函数是这个鸟样子,因为这里找到依赖对象的类型,却找不到对象本身,次奥!!!
另外一种情况就是动态SQL了,无法使用 sys.dm_sql_referenced_entities这个系统函数找到其依赖的对象。
其他对象的同步
支持其他数据库对象的同步,比如function,table type等,因为可以在同步其他存储过程对象的时候附带的同步function,table type,这个与表或者存储过程类似,不做过多说明。
已知问题:
1,201906122030:经测试,目前暂时不支持Sequence对象的同步。
需要改进的地方
1,代码结构优化,更加清晰和条例的结构(一开始用最直接简单粗暴的方式快速实现,后面重构了很多代码,现在自己看起来还有很多不舒服的痕迹)
2,数据同步的效率问题,对于多表的导入导出操作,依赖于单线程,多个大表导出串行的话,可能存在效率上的瓶颈,如何根据表的数据量,尽可能平均地分配多多个线程中,提升效率
3,更加友好清晰的异常提示以及日志记录,生成导出日志信息。
4,异构数据同步,MySQL《==》SQL Server《==》Oracle《==》PGSQL
代码端午节写好了,这几天抽空进行了一些测试以及bug fix,应该还潜在不少未知的bug,工作量比想象中的大的多了去了。
# -*- coding: utf-8 -*-
# !/usr/bin/env python3
__author__ = 'MSSQL123'
__date__ = '2019-06-07 09:36'
import os
import sys
import time
import datetime
import pymssql
from decimal import Decimal
usage = '''
-----parameter explain-----
source database parameter
-s_h : soure database host ----- must require parameter
-s_i : soure database instace name ----- default instance name MSSQL
-s_d : soure database name ----- must require parameter
-s_u : soure database login ----- default windows identifier
-s_p : soure database login password ----- must require when s_u is not null
-s_P : soure database instance port ----- default port 1433
target database parameter
-t_h : target database host ----- must require parameter
-t_i : target database instace name ----- default instance name MSSQL
-t_d : target database name ----- must require parameter
-t_u : target database login ----- default windows identifier
-t_p : target database login password ----- must require when s_u is not null
-t_P : target database instance port ----- default port 1433
sync object parameter
-obj_type : table or sp or function or other databse object ----- tab or sp or fn or tp
-obj : table|sp|function|type name ----- whick table or sp sync
overwirte parameter
-f : force overwirte target database object ----- F or N
--help: help document
Example:
python DataTransfer.py -s_h=127.0.0.1 -s_P=1433 -s_i="MSSQL" -s_d="DB01" -obj_type="tab" -obj="dbo.t1,dbo.t2" -t_h=127.0.0.1 -t_P=1433 -t_i="MSSQL" -t_d="DB02" -f="Y"
python DataTransfer.py -s_h=127.0.0.1 -s_P=1433 -s_i="MSSQL" -s_d="DB01" -obj_type="sp" -obj="dbo.sp1,dbo.sp2" -t_h=127.0.0.1 -t_P=1433 -t_i="MSSQL" -t_d="DB02" -f="Y"
'''
class SyncDatabaseObject(object):
# source databse
s_h = None
s_i = None
s_P = None
s_u = None
s_p = None
s_d = None
# obj type
s_obj_type = None
# sync objects
s_obj = None
# target database
t_h = None
t_i = None
t_P = None
t_u = None
t_p = None
t_d = None
f = None
file_path = None
def __init__(self, *args, **kwargs):
for k, v in kwargs.items():
setattr(self, k, v)
# connect to sqlserver
def get_connect(self, _h, _i, _P, _u, _p, _d):
cursor = False
try:
if (_u) and (_p):
conn = pymssql.connect(host=_h,
server=_i,
port=_P,
user=_u,
password=_p,
database=_d)
else:
conn = pymssql.connect(host=_h,
server=_i,
port=_P,
database=_d)
if (conn):
return conn
except:
raise
return conn
# check connection
def validated_connect(self, _h, _i, _P, _u, _p, _d):
if not (self.get_connect(_h, _i, _P, _u, _p, _d)):
print("connect to " + str(_h) + " failed,please check you parameter")
exit(0)
'''
this is supposed to be a valid object name just like xxx_name,or dbo.xxx_name,or [schema].xxx_name or schema.[xxx_name]
then transfer this kind of valid object name to format object name like [dbo].[xxx_name](give a default dbo schema name when no schema name)
other format object name consider as unvalid,will be rasie error in process
format object name
1,xxx_name ======> [dbo].[xxx_name]
2,dbo.xxx_name ======> [dbo].[xxx_name]
3,[schema].xxx_name ======> [dbo].[xxx_name]
3,schema.xxx_name ======> [schema].[xxx_name]
4,[schema].[xxx_name] ======> [schema].[xxx_name]
5,[schema].[xxx_name ======> rasie error format message
'''
@staticmethod
def format_object_name(name):
format_name = ""
if ("." in name):
schema_name = name[0:name.find(".")]
object_name = name[name.find(".") + 1:]
if not ("[" in schema_name):
schema_name = "[" + schema_name + "]"
if not ("[" in object_name):
object_name = "[" + object_name + "]"
format_name = schema_name + "." + object_name
else:
if ("[" in name):
format_name = "[dbo]." + name
else:
format_name = "[dbo]." + "[" + name + "]"
return format_name
'''
check user input object is a valid object
'''
def exits_object(self, conn, name):
conn = conn
cursor_source = conn.cursor()
# get object by name from source db
sql_script = r'''select top 1 1 from
(
select concat(QUOTENAME(schema_name(schema_id)),'.',QUOTENAME(name)) as obj_name from sys.objects
union all
select concat(QUOTENAME(schema_name(schema_id)),'.',QUOTENAME(name)) as obj_name from sys.types
)t where obj_name = '{0}'
'''.format(self.format_object_name(name))
cursor_source.execute(sql_script)
result = cursor_source.fetchall()
if not result:
return 0
else:
return 1
conn.cursor.close()
conn.close()
# table variable sync
def sync_table_variable(self, tab_name, is_reference):
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
if (self.exits_object(conn_source, self.format_object_name(tab_name))) > 0:
pass
else:
print("----------------------- warning message -----------------------")
print("--------warning: object " + tab_name + " not existing in source database ------------")
print("----------------------- warning message -----------------------")
print()
return
exists_in_target = 0
sql_script = r'''select top 1 1
from sys.table_types tp
where is_user_defined = 1
and concat(QUOTENAME(schema_name(tp.schema_id)),'.',QUOTENAME(tp.name)) = '{0}' ''' \
.format((self.format_object_name(tab_name)))
# if the table schema exists in target server,skip
cursor_target.execute(sql_script)
exists_in_target = cursor_target.fetchone()
# weather exists in target server database
if (self.f == "Y"):
if (is_reference != "Y"):
# skiped,table type can not drop when used by sp
sql_script = r'''
if OBJECT_ID('{0}') is not null
drop type {0}
'''.format(self.format_object_name(tab_name))
cursor_target.execute(sql_script)
conn_target.commit()
else:
if exists_in_target:
print("----------------------- warning message -----------------------")
print("the target table type " + tab_name + " exists ,skiped sync table type from source")
print("----------------------- warning message -----------------------")
print()
return
sql_script = r'''
DECLARE @SQL NVARCHAR(MAX) = ''
SELECT @SQL =
'CREATE TYPE ' + '{0}' + 'AS TABLE' + CHAR(13) + '(' + CHAR(13) +
STUFF((
SELECT CHAR(13) + ' , [' + c.name + '] ' +
CASE WHEN c.is_computed = 1
THEN 'AS ' + OBJECT_DEFINITION(c.[object_id], c.column_id)
ELSE
CASE WHEN c.system_type_id != c.user_type_id
THEN '[' + SCHEMA_NAME(tp.[schema_id]) + '].[' + tp.name + ']'
ELSE '[' + UPPER(y.name) + ']'
END +
CASE
WHEN y.name IN ('varchar', 'char', 'varbinary', 'binary')
THEN '(' + CASE WHEN c.max_length = -1
THEN 'MAX'
ELSE CAST(c.max_length AS VARCHAR(5))
END + ')'
WHEN y.name IN ('nvarchar', 'nchar')
THEN '(' + CASE WHEN c.max_length = -1
THEN 'MAX'
ELSE CAST(c.max_length / 2 AS VARCHAR(5))
END + ')'
WHEN y.name IN ('datetime2', 'time2', 'datetimeoffset')
THEN '(' + CAST(c.scale AS VARCHAR(5)) + ')'
WHEN y.name = 'decimal'
THEN '(' + CAST(c.[precision] AS VARCHAR(5)) + ',' + CAST(c.scale AS VARCHAR(5)) + ')'
ELSE ''
END +
CASE WHEN c.collation_name IS NOT NULL AND c.system_type_id = c.user_type_id
THEN ' COLLATE ' + c.collation_name
ELSE ''
END +
CASE WHEN c.is_nullable = 1
THEN ' NULL'
ELSE ' NOT NULL'
END +
CASE WHEN c.default_object_id != 0
THEN ' CONSTRAINT [' + OBJECT_NAME(c.default_object_id) + ']' +
' DEFAULT ' + OBJECT_DEFINITION(c.default_object_id)
ELSE ''
END
END
From sys.table_types tp
Inner join sys.columns c on c.object_id = tp.type_table_object_id
Inner join sys.types y ON y.system_type_id = c.system_type_id
WHERE tp.is_user_defined = 1 and y.name<>'sysname'
and concat(QUOTENAME(schema_name(tp.schema_id)),'.',QUOTENAME(tp.name)) = '{0}'
ORDER BY c.column_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 7, ' ')
+ ');'
select @SQL as script
'''.format(self.format_object_name(self.format_object_name((tab_name))))
cursor_target = conn_target.cursor()
cursor_source.execute(sql_script)
row = cursor_source.fetchone()
try:
if not exists_in_target:
# execute the script on target server
cursor_target.execute(str(row[0])) # drop current stored_procudre if exists
conn_target.commit()
print("*************table type " + self.format_object_name(tab_name) + " synced *********************")
print() # give a blank row when finish
except:
print("----------------------- error message -----------------------")
print("-----------table type " + self.format_object_name(tab_name) + " synced error ---------------")
print("----------------------- error message -----------------------")
print()
# raise
cursor_source.close()
conn_source.close()
cursor_target.close()
conn_target.close()
# schema sync
def sync_schema(self):
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
arr_schema = []
# get all table in database when not define table name
schema_result = cursor_source.execute(r'''
select name from sys.schemas where schema_id>4 and schema_id<16384
''')
for row in cursor_source.fetchall():
cursor_target.execute(r''' if not exists(select * from sys.schemas where name = '{0}')
begin
exec('create schema [{0}]')
end
'''.format(str(row[0])))
conn_target.commit()
cursor_source.close()
conn_source.close()
cursor_target.close()
conn_target.close()
def sync_table_schema_byname(self, tab_name, is_reference):
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
if (self.exits_object(conn_source, self.format_object_name(tab_name)) == 0):
print("----------------------- warning message -----------------------")
print("---------------warning: object " + tab_name + " not existing in source database ----------------")
print("----------------------- warning message -----------------------")
print()
return
# if exists a reference table for sp,not sync the table agagin
if (self.exits_object(conn_target, self.format_object_name(tab_name)) > 0):
if (self.f != "Y"):
print("----------------------- warning message -----------------------")
print("---------------warning: object " + tab_name + " existing in target database ----------------")
print("----------------------- warning message -----------------------")
print()
return
sql_script = r''' select top 1 1 from sys.tables
where type_desc = 'USER_TABLE'
and concat(QUOTENAME(schema_name(schema_id)),'.',QUOTENAME(name)) = '{0}'
'''.format((self.format_object_name(tab_name)))
# if the table schema exists in target server,skip
cursor_target.execute(sql_script)
exists_in_target = cursor_target.fetchone()
if exists_in_target:
if (self.f == "Y"):
if (is_reference != "Y"):
cursor_target.execute("drop table {0}".format(tab_name))
else:
print("----------------------- warning message -----------------------")
print("the target table " + tab_name + " exists ,skiped sync table schema from source")
print("----------------------- warning message -----------------------")
print()
return
sql_script = r''' DECLARE
@object_name SYSNAME
, @object_id INT
SELECT
@object_name = '[' + s.name + '].[' + o.name + ']'
, @object_id = o.[object_id]
FROM sys.objects o WITH (NOWAIT)
JOIN sys.schemas s WITH (NOWAIT) ON o.[schema_id] = s.[schema_id]
WHERE QUOTENAME(s.name) + '.' + QUOTENAME(o.name) = '{0}'
AND o.[type] = 'U'
AND o.is_ms_shipped = 0
DECLARE @SQL NVARCHAR(MAX) = ''
;WITH index_column AS
(
SELECT
ic.[object_id]
, ic.index_id
, ic.is_descending_key
, ic.is_included_column
, c.name
FROM sys.index_columns ic WITH (NOWAIT)
JOIN sys.columns c WITH (NOWAIT) ON ic.[object_id] = c.[object_id] AND ic.column_id = c.column_id
WHERE ic.[object_id] = @object_id
),
fk_columns AS
(
SELECT
k.constraint_object_id
, cname = c.name
, rcname = rc.name
FROM sys.foreign_key_columns k WITH (NOWAIT)
JOIN sys.columns rc WITH (NOWAIT) ON rc.[object_id] = k.referenced_object_id AND rc.column_id = k.referenced_column_id
JOIN sys.columns c WITH (NOWAIT) ON c.[object_id] = k.parent_object_id AND c.column_id = k.parent_column_id
WHERE k.parent_object_id = @object_id
)
SELECT @SQL = 'CREATE TABLE ' + @object_name + '' + '(' + '' + STUFF((
SELECT '' + ', [' + c.name + '] ' +
CASE WHEN c.is_computed = 1
THEN 'AS ' + cc.[definition]
ELSE UPPER(tp.name) +
CASE WHEN tp.name IN ('varchar', 'char', 'varbinary', 'binary', 'text')
THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length AS VARCHAR(5)) END + ')'
WHEN tp.name IN ('nvarchar', 'nchar')
THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length / 2 AS VARCHAR(5)) END + ')'
WHEN tp.name IN ('datetime2', 'time2', 'datetimeoffset')
THEN '(' + CAST(c.scale AS VARCHAR(5)) + ')'
WHEN tp.name = 'decimal'
THEN '(' + CAST(c.[precision] AS VARCHAR(5)) + ',' + CAST(c.scale AS VARCHAR(5)) + ')'
ELSE ''
END +
CASE WHEN c.collation_name IS NOT NULL THEN ' COLLATE ' + c.collation_name ELSE '' END +
CASE WHEN c.is_nullable = 1 THEN ' NULL' ELSE ' NOT NULL' END +
CASE WHEN dc.[definition] IS NOT NULL THEN ' DEFAULT' + dc.[definition] ELSE '' END +
CASE WHEN ic.is_identity = 1 THEN ' IDENTITY(' + CAST(ISNULL( /*ic.seed_value*/ 1, '0') AS CHAR(1)) + ',' + CAST(ISNULL(ic.increment_value, '1') AS CHAR(1)) + ')' ELSE '' END
END + ''
FROM sys.columns c WITH (NOWAIT)
JOIN sys.types tp WITH (NOWAIT) ON c.user_type_id = tp.user_type_id
LEFT JOIN sys.computed_columns cc WITH (NOWAIT) ON c.[object_id] = cc.[object_id] AND c.column_id = cc.column_id
LEFT JOIN sys.default_constraints dc WITH (NOWAIT) ON c.default_object_id != 0 AND c.[object_id] = dc.parent_object_id AND c.column_id = dc.parent_column_id
LEFT JOIN sys.identity_columns ic WITH (NOWAIT) ON c.is_identity = 1 AND c.[object_id] = ic.[object_id] AND c.column_id = ic.column_id
WHERE c.[object_id] = @object_id
ORDER BY c.column_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '' + ' ')
+ ISNULL((SELECT '' + ', CONSTRAINT [' + k.name + '] PRIMARY KEY (' +
(SELECT STUFF((
SELECT ', [' + c.name + '] ' + CASE WHEN ic.is_descending_key = 1 THEN 'DESC' ELSE 'ASC' END
FROM sys.index_columns ic WITH (NOWAIT)
JOIN sys.columns c WITH (NOWAIT) ON c.[object_id] = ic.[object_id] AND c.column_id = ic.column_id
WHERE ic.is_included_column = 0
AND ic.[object_id] = k.parent_object_id
AND ic.index_id = k.unique_index_id
FOR XML PATH(N''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, ''))
+ ')' + ''
FROM sys.key_constraints k WITH (NOWAIT)
WHERE k.parent_object_id = @object_id
AND k.[type] = 'PK'), '') + ')' + ''
+ ISNULL((SELECT (
SELECT '' +
'ALTER TABLE ' + @object_name + ' WITH'
+ CASE WHEN fk.is_not_trusted = 1
THEN ' NOCHECK'
ELSE ' CHECK'
END +
' ADD CONSTRAINT [' + fk.name + '] FOREIGN KEY('
+ STUFF((
SELECT ', [' + k.cname + ']'
FROM fk_columns k
WHERE k.constraint_object_id = fk.[object_id] and 1=2
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
+ ')' +
' REFERENCES [' + SCHEMA_NAME(ro.[schema_id]) + '].[' + ro.name + '] ('
+ STUFF((
SELECT ', [' + k.rcname + ']'
FROM fk_columns k
WHERE k.constraint_object_id = fk.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
+ ')'
+ CASE
WHEN fk.delete_referential_action = 1 THEN ' ON DELETE CASCADE'
WHEN fk.delete_referential_action = 2 THEN ' ON DELETE SET NULL'
WHEN fk.delete_referential_action = 3 THEN ' ON DELETE SET DEFAULT'
ELSE ''
END
+ CASE
WHEN fk.update_referential_action = 1 THEN ' ON UPDATE CASCADE'
WHEN fk.update_referential_action = 2 THEN ' ON UPDATE SET NULL'
WHEN fk.update_referential_action = 3 THEN ' ON UPDATE SET DEFAULT'
ELSE ''
END
+ '' + 'ALTER TABLE ' + @object_name + ' CHECK CONSTRAINT [' + fk.name + ']' + ''
FROM sys.foreign_keys fk WITH (NOWAIT)
JOIN sys.objects ro WITH (NOWAIT) ON ro.[object_id] = fk.referenced_object_id
WHERE fk.parent_object_id = @object_id
FOR XML PATH(N''), TYPE).value('.', 'NVARCHAR(MAX)')), '')
+ ISNULL(((SELECT
'' + 'CREATE' + CASE WHEN i.is_unique = 1 THEN ' UNIQUE' ELSE '' END
+ ' NONCLUSTERED INDEX [' + i.name + '] ON ' + @object_name + ' (' +
STUFF((
SELECT ', [' + c.name + ']' + CASE WHEN c.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END
FROM index_column c
WHERE c.is_included_column = 0
AND c.index_id = i.index_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ')'
+ ISNULL('' + 'INCLUDE (' +
STUFF((
SELECT ', [' + c.name + ']'
FROM index_column c
WHERE c.is_included_column = 1
AND c.index_id = i.index_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ')', '') + ''
FROM sys.indexes i WITH (NOWAIT)
WHERE i.[object_id] = @object_id
AND i.is_primary_key = 0
AND i.[type] = 2
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)')
), '')
select @SQL as script '''.format(self.format_object_name(tab_name))
cursor_target = conn_target.cursor()
cursor_source.execute(sql_script)
row = cursor_source.fetchone()
if not row[0]:
return
try:
cursor_target.execute(row[0]) # drop current table schema if exists
conn_target.commit()
print("*************schema " + self.format_object_name(tab_name) + " synced *************")
print() # give a blank row when finish
except:
print("----------------------- warning message -----------------------")
print("-----------schema " + self.format_object_name(tab_name) + " synced failed---------------")
print("----------------------- warning message -----------------------")
print()
cursor_source.close()
conn_source.close()
cursor_target.close()
conn_target.close()
def get_table_column(self, conn, tab_name):
column_names = ""
conn = conn
cursor_source = conn.cursor()
# get object by name from source db
sql_script = r'''select name from sys.columns
where object_id = object_id('{0}') and is_computed=0 order by object_id
'''.format(self.format_object_name(tab_name))
cursor_source.execute(sql_script)
result = cursor_source.fetchall()
for row in result:
column_names = column_names + row[0] + ","
return column_names[0:len(column_names) - 1]
conn.cursor.close()
conn.close()
def sync_table_schema(self):
#default not sync by referenced other object
is_reference = "N"
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
arr_table = []
if (self.s_obj):
for tab_name in self.s_obj.split(","):
if (tab_name) and (self.exits_object(conn_source, tab_name)>0):
self.sync_table_schema_byname(tab_name, is_reference)
else:
print("----------------------- warning message -----------------------")
print("-----------schema " + self.format_object_name(tab_name) + " not existing in source database---------------")
print("----------------------- warning message -----------------------")
print()
else:
# sync all tables
# get all table in database when not define table name
sql_script = ''' SELECT QUOTENAME(s.name)+'.'+ QUOTENAME(o.name)
FROM sys.objects o WITH (NOWAIT)
JOIN sys.schemas s WITH (NOWAIT) ON o.[schema_id] = s.[schema_id]
WHERE o.[type] = 'U' AND o.is_ms_shipped = 0
'''
cursor_source.execute(sql_script)
for row in cursor_source.fetchall():
self.sync_table_schema_byname(str(row[0]), is_reference)
# sync data from soure table to target table
def sync_table_data(self):
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
arr_table = []
if (self.s_obj):
arr_table = self.s_obj.split(',')
for tab_name in arr_table:
if (self.exits_object(conn_target, self.format_object_name(tab_name)) == 0):
arr_table.remove(tab_name)
print("----------------- warning message -----------------------")
print("----------------- warning: table " + tab_name + " not existing in target database ---------------------")
print("----------------- warning message -----------------------")
else:
# get all table in database when not define table name
tab_result = cursor_source.execute(r''' SELECT QUOTENAME(s.name)+'.'+ QUOTENAME(o.name)
FROM sys.objects o WITH (NOWAIT)
JOIN sys.schemas s WITH (NOWAIT) ON o.[schema_id] = s.[schema_id]
WHERE o.[type] = 'U'
AND o.is_ms_shipped = 0
''')
for row in cursor_source.fetchall():
arr_table.append(str(row[0]))
insert_columns = ""
insert_columns = self.get_table_column(conn_source, tab_name)
for tab_name in arr_table:
if (self.f != "Y"):
sql_script = "select top 1 {0} from {1} ".format(insert_columns, tab_name)
# if exists data in target table,break
cursor_target.execute(sql_script)
exists = cursor_target.fetchone()
if exists:
print("----------------------- warning message -----------------------")
print("the target table " + tab_name + " exists data,skiped sync table type from source")
print("----------------------- warning message -----------------------")
print()
continue
else:
sql_script = "truncate table {0} ".format(tab_name)
# if exists data in target table,break
cursor_target.execute(sql_script)
conn_target.commit()
insert_columns = ""
insert_columns = self.get_table_column(conn_source, tab_name)
insert_prefix = ""
# weather has identity column
cursor_source.execute(r'''select 1 from sys.columns
where object_id = OBJECT_ID('{0}') and is_identity =1
'''.format(tab_name))
exists_identity = None
exists_identity = cursor_source.fetchone()
if (exists_identity):
insert_prefix = "set identity_insert {0} on; ".format(tab_name)
# data source
insert_sql = ""
values_sql = ""
current_row = ""
counter = 0
sql_script = r''' select {0} from {1} '''.format(insert_columns, tab_name)
cursor_source.execute(sql_script)
# create insert columns
'''
for field in cursor_source.description:
insert_columns = insert_columns + str(field[0]) + ","
insert_columns = insert_columns[0:len(insert_columns) - 1]
'''
insert_prefix = insert_prefix + "insert into {0} ({1}) values ".format(tab_name, insert_columns)
for row in cursor_source.fetchall():
counter = counter + 1
for key in row:
if (str(key) == "None"):
current_row = current_row + r''' null, '''
else:
if (type(key) is datetime.datetime):
current_row = current_row + r''' '{0}', '''.format(str(key)[0:23])
elif (type(key) is str):
# 我槽!!!,这里又有一个坑:https://blog.csdn.net/dadaowuque/article/details/81016127
current_row = current_row + r''' '{0}', '''.format(
key.replace("'", "''").replace('\u0000', '').replace('\x00', ''))
elif (type(key) is Decimal):
d = Decimal(key)
s = '{0:f}'.format(d)
current_row = current_row + r''' '{0}', '''.format(s)
elif (type(key) is bytes):
# print(hex(int.from_bytes(key, 'big', signed=True) ))
current_row = current_row + r''' {0}, '''.format(
hex(int.from_bytes(key, 'big', signed=False)))
else:
current_row = current_row + r''' '{0}', '''.format(key)
current_row = current_row[0:len(current_row) - 2] # remove the the last one char ","
values_sql = values_sql + "(" + current_row + "),"
current_row = ""
# execute the one batch when
if (counter == 1000):
insert_sql = insert_prefix + values_sql
insert_sql = insert_sql[0:len(insert_sql) - 1] # remove the the last one char ","
if (exists_identity):
insert_sql = insert_sql + " ;set identity_insert {0} off;".format(tab_name)
try:
cursor_target.execute(insert_sql)
except:
print(
"----------------------error " + tab_name + " data synced failed-------------------------")
raise
conn_target.commit()
insert_sql = ""
values_sql = ""
current_row = ""
counter = 0
print(time.strftime("%Y-%m-%d %H:%M:%S",
time.localtime()) + "*************** " + self.format_object_name(
tab_name) + " " + str(1000) + " rows synced *************")
if (values_sql):
insert_sql = insert_prefix + values_sql
insert_sql = insert_sql[0:len(insert_sql) - 1] # remove the the last one char ","
if (exists_identity):
insert_sql = insert_sql + " ; set identity_insert {0} off;".format(tab_name)
# execute the last batch
try:
cursor_target.execute(insert_sql)
except:
print("------------------error " + tab_name + " data synced failed------------------------")
raise
conn_target.commit()
insert_sql = ""
values_sql = ""
current_row = ""
print(time.strftime("%Y-%m-%d %H:%M:%S",
time.localtime()) + "*************** " + self.format_object_name(
tab_name) + " " + str(
counter) + " rows synced *************")
print(time.strftime("%Y-%m-%d %H:%M:%S",
time.localtime()) + "----------------synced " + self.format_object_name(
tab_name) + " data finished---------------")
print()
cursor_source.close()
conn_source.close()
cursor_target.close()
conn_target.close()
def sync_dependent_object(self, obj_name):
# 强制覆盖,不需要对依赖对象生效,如果是因为属于依赖对象而被同步的,先检查target中是否存在,如果存在就不继续同步,这里打一个标记来实现
is_refernece = "Y"
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
'''
find dependent objects
if exists dependent objects,sync Dependent objects objects in advance
'''
sql_check_dependent = r'''
SELECT * FROM
(
SELECT
distinct rtrim(lower(s.type)) COLLATE Chinese_PRC_CI_AS as obj_type,
QUOTENAME(d.referenced_schema_name)+'.'+QUOTENAME(d.referenced_entity_name) COLLATE Chinese_PRC_CI_AS as obj
FROM sys.dm_sql_referenced_entities('{0}','OBJECT') as d
inner join sys.sysobjects s on s.id = d.referenced_id
union all
SELECT
distinct rtrim(lower(d.referenced_class_desc)) COLLATE Chinese_PRC_CI_AS as obj_type,
QUOTENAME(d.referenced_schema_name)+'.'+QUOTENAME(d.referenced_entity_name) COLLATE Chinese_PRC_CI_AS as obj
FROM sys.dm_sql_referenced_entities('{0}','OBJECT') as d
inner join sys.types s on s.user_type_id = d.referenced_id
)t
'''.format(self.format_object_name(obj_name))
cursor_source.execute(sql_check_dependent)
result = cursor_source.fetchall()
for row in result:
if row[1]:
if (row[0] == "u"):
if (row[1]):
self.sync_table_schema_byname(row[1], is_refernece)
elif (row[0] == "fn" or row[0] == "if"):
if (row[1]):
self.sync_procudre_by_name("f", row[1], is_refernece)
elif (row[0] == "type"):
if (row[1]):
self.sync_table_variable(row[1], is_refernece)
def sync_procudre_by_name(self, type, obj_name, is_reference):
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
if (self.exits_object(conn_source, self.format_object_name(obj_name)) == 0):
print("---------------warning message----------------")
print("---------------warning: object " + obj_name + " not existing in source database ----------------")
print("---------------warning message----------------")
print()
return
if (self.exits_object(conn_target, self.format_object_name(obj_name)) > 0):
if (self.f != "Y"):
print("---------------warning message----------------")
print("---------------warning: object " + obj_name + " existing in target database ----------------")
print("---------------warning message----------------")
print()
return
'''
本来想直接生成删除语句的:
这里有一个该死的转义,怎么都弄不好,中午先去吃饭吧,
下午回来想了一下,换一种方式,不要死磕转义问题了
sql_script =
select
'if object_id('+''''+QUOTENAME(schema_name(uid))+ '' + QUOTENAME(name)+''''+') is not null '
+' drop proc '+QUOTENAME(schema_name(uid))+ '.' + QUOTENAME(name) ,
OBJECT_DEFINITION(id)
from sys.sysobjects where xtype = 'P' and uid not in (16,19)
'''
sql_script = r'''
select
QUOTENAME(schema_name(uid))+'.'+QUOTENAME(name),
OBJECT_DEFINITION(id)
from sys.sysobjects where xtype in ('P','IF','FN') and uid not in (16,19)
'''
if (obj_name):
sql_script = sql_script + " and QUOTENAME(schema_name(uid))+ '.' + QUOTENAME(name) ='{0}' ".format(
self.format_object_name(obj_name))
cursor_source.execute(sql_script)
row = cursor_source.fetchone()
try:
if type == "f":
sql_script = r'''
if object_id('{0}') is not null
drop function {0}
'''.format(self.format_object_name(row[0]))
elif type == "p":
sql_script = r'''
if object_id('{0}') is not null
drop proc {0}
'''.format(self.format_object_name(row[0]))
cursor_target.execute(sql_script) # drop current stored_procudre if exists
conn_target.commit()
# sync dependent object
if (is_reference != "N"):
self.sync_dependent_object(self.format_object_name(row[0]))
# sync object it self
cursor_target.execute(str(row[1])) # execute create stored_procudre script
conn_target.commit()
print("*************sync sp: " + self.format_object_name(row[0]) + " finished *****************")
print()
except:
print("---------------error message----------------")
print("------------------ sync " + row[0] + "sp error --------------------------")
print("---------------error message----------------")
print()
cursor_source.close()
conn_source.close()
cursor_target.close()
conn_target.close()
def sync_procudre(self, type):
is_reference = "N"
conn_source = self.get_connect(self.s_h, self.s_i, self.s_P, self.s_u, self.s_p, self.s_d)
conn_target = self.get_connect(self.t_h, self.t_i, self.t_P, self.t_u, self.t_p, self.t_d)
cursor_source = conn_source.cursor()
cursor_target = conn_target.cursor()
if (self.s_obj):
for proc_name in self.s_obj.split(","):
self.sync_dependent_object(proc_name)
self.sync_procudre_by_name(type, proc_name, is_reference)
# sync all sp and function
else:
sql_script = r'''
select
QUOTENAME(schema_name(uid))+'.'+QUOTENAME(name),
OBJECT_DEFINITION(id)
from sys.sysobjects where xtype = upper('{0}') and uid not in (16,19)
'''.format(type)
cursor_source.execute(sql_script)
for row in cursor_source.fetchall():
self.sync_dependent_object(row[0])
self.sync_procudre_by_name(type, row[0], is_reference)
if __name__ == "__main__":
'''
sync = SyncDatabaseObject(s_h="127.0.0.1",
s_i = "sql2017",
s_P = 49744,
s_d="DB01",
t_h="127.0.0.1",
t_i="sql2017",
t_P=49744,
t_d="DB02",
s_obj_type = "sp",
s_obj = "dbo.sp_test01",
f="Y")
sync.sync_procudre("p")
'''
p_s_h = ""
p_s_i = "MSSQL"
p_s_P = 1433
p_s_d = ""
p_s_u = None
p_s_p = None
p_s_obj = ""
p_type = ""
p_t_s = ""
p_t_i = "MSSQL"
p_t_P = "1433"
p_t_d = ""
p_t_u = None
p_t_p = None
# force conver target database object,default not force cover target database object
p_f = "N"
# sync obj type table|sp
p_obj_type = None
# sync whick database object
p_obj = None
if len(sys.argv) == 1:
print(usage)
sys.exit(1)
elif sys.argv[1] == '--help':
print(usage)
sys.exit()
elif len(sys.argv) >= 2:
for i in sys.argv[1:]:
_argv = i.split('=')
# source server name
if _argv[0] == '-s_h':
p_s_h = _argv[1]
# source server instance name
if _argv[0] == '-s_i':
if (_argv[1]):
p_s_i = _argv[1]
# source server instance PORT
if _argv[0] == '-s_P':
if (_argv[1]):
p_s_P = _argv[1]
# source database name
if _argv[0] == '-s_d':
p_s_d = _argv[1]
if _argv[0] == '-s_u':
p_s_u = _argv[1]
if _argv[0] == '-s_p':
p_s_p = _argv[1]
if _argv[0] == '-t_h':
p_t_h = _argv[1]
if _argv[0] == '-t_i':
if (_argv[1]):
p_t_i = _argv[1]
if _argv[0] == '-t_P':
if (_argv[1]):
p_t_P = _argv[1]
if _argv[0] == '-t_d':
p_t_d = _argv[1]
if _argv[0] == '-t_u':
p_t_u = _argv[1]
if _argv[0] == '-t_p':
p_t_p = _argv[1]
if _argv[0] == '-f':
if (_argv[1]):
p_f = _argv[1]
# object type
if _argv[0] == '-obj_type':
if not (_argv[1]):
print("-obj_type can not be null (-obj=tab|-obj=sp|-obj=fn|-obj=type)")
exit(0)
else:
p_obj_type = _argv[1]
# object name
if _argv[0] == '-obj':
if (_argv[1]):
p_obj = _argv[1]
# require para
if p_s_h.strip() == "":
print("source server host cannot be null")
exit(0)
if p_s_d.strip() == "":
print("source server host database name cannot be null")
exit(0)
if p_t_h.strip() == "":
print("target server host cannot be null")
exit(0)
if p_t_d.strip() == "":
print("target server host database name cannot be null")
exit(0)
sync = SyncDatabaseObject(s_h=p_s_h,
s_i=p_s_i,
s_P=p_s_P,
s_d=p_s_d,
s_u=p_s_u,
s_p=p_s_p,
s_obj=p_obj,
t_h=p_t_h,
t_i=p_t_i,
t_P=p_t_P,
t_d=p_t_d,
t_u=p_t_u,
t_p=p_t_p,
f=p_f)
sync.validated_connect(p_s_h, p_s_i, p_s_P, p_s_d, p_s_u, p_s_p)
sync.validated_connect(p_t_h, p_t_i, p_t_P, p_t_d, p_t_u, p_t_p)
if (p_f.upper() == "Y"):
confirm = input("confirm you want to overwrite the target object? ")
if confirm.upper() != "Y":
exit(0)
print("-------------------------- sync begin ----------------------------------")
print()
if (p_obj_type == "tab"):
# sync schema
sync.sync_schema()
# sync table schema
sync.sync_table_schema()
# sync data
sync.sync_table_data()
elif (p_obj_type == "sp"):
# sync schema
sync.sync_schema()
# sync sp
sync.sync_procudre("p")
elif (p_obj_type == "fn"):
# sync schema
sync.sync_schema()
# sync sp
sync.sync_procudre("fn")
elif (p_obj_type == "tp"):
# sync schema
sync.sync_schema()
# sync sp
sync.sync_table_variable()
else:
print("-obj_type is not validated")
print()
print("-------------------------- sync finish ----------------------------------")
总结
以上所述是小编给大家介绍的基于Python的SQL Server数据库实现对象同步轻量级,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-
Python连接SQLServer2000的方法详解
本文实例讲述了Python连接SQLServer2000的方法.分享给大家供大家参考,具体如下: http://pymssql.sourceforge.net/ 介绍PYTHON 连接MSSQL的好地址的哦! Python好的一个方法就是能够在网上找到很多现成的模块然后直接下载拿过来用就可以了.具体快速开发的一个原因也就是这个了.现在就是主要来研究一个pymssql这个模块的操作功能了! 可以安装之后直接查询帮助文档进行查看到这个模块的一些功能帮助文档. 1.一个解决乱码问题的方法: s.de
-
python访问sqlserver示例
最近遇到了Python访问SqlServer的问题,这里总结下. 一.Windows下配置Python访问Sqlserver 环境:Windows 7 + Sqlserver 2008 1.下载并安装pyodbc 下载地址:http://code.google.com/p/pyodbc/downloads/list 2.访问SqlServer 复制代码 代码如下: >>> import pyodbc>>>cnxn = pyodbc.connect('DRIVER={SQ
-
Python实现读取SQLServer数据并插入到MongoDB数据库的方法示例
本文实例讲述了Python实现读取SQLServer数据并插入到MongoDB数据库的方法.分享给大家供大家参考,具体如下: # -*- coding: utf-8 -*- import pyodbc import os import csv import pymongo from pymongo import ASCENDING, DESCENDING from pymongo import MongoClient import binascii '''连接mongoDB数据库''' clie
-
Windows和Linux下使用Python访问SqlServer的方法介绍
经常用Python写demo来验证方案的可行性,最近遇到了Python访问SqlServer的问题,这里总结下. 一.Windows下配置Python访问Sqlserver 环境:Windows 7 + Sqlserver 2008 1.下载并安装pyodbc 下载地址:http://code.google.com/p/pyodbc/downloads/list 2.访问SqlServer 复制代码 代码如下: >>> import pyodbc >>>cnxn = p
-
Python3连接SQLServer、Oracle、MySql的方法
环境: python3.4 64bit pycharm2018社区版 64bit Oracle 11 64bit SQLServer· Mysql 其中三种不同的数据库安装在不同的服务器上,通过局域网相连 步骤1:在pycharm上安装相应的包,可通过pip或者其他方式 步骤2:import这些包 import pymysql,pymssql,cx_Oracle #导入数据库相关包 步骤3: db_sqls = pymssql.connect(host='192.168.10.172',port
-
基于Python的SQL Server数据库实现对象同步轻量级
缘由 日常工作中经常遇到类似的问题:把某个服务器上的某些指定的表同步到另外一台服务器. 类似需求用SSIS或者其他ETL工作很容易实现,比如用SSIS的话,就会会存在相当一部分反复的手工操作. 建源的数据库信息,目标的数据库信息,如果是多个表,需要一个一个地拉source和target,然后一个一个地mapping,然后运行实现数据同步. 然后很可能,这个workflow使用也就这么一次,就寿终正寝了,却一样要浪费时间去做这个ETL. 快速数据同步实现 于是在想,可不可能快速实现类似需求,尽最大
-

python连接sql server数据库的方法实战
目录 一.安装第三方模块 二.连接数据库 三.遇到的问题 总结 一.安装第三方模块 首先要下载名为"pymssql"的模块,然后import该模块 安装方法 :1.第一种方法:按win+r----> 输入cmd—>输入以下命令即可 pip install pymssql 2.第二种方法:打开pycharm,点击File,再点击settings,点击settings之后再点击project下面的project Interpreter,在界面中点击+号,直接搜索pymssql模
-
Python基于Pymssql模块实现连接SQL Server数据库的方法详解
本文实例讲述了Python基于Pymssql模块实现连接SQL Server数据库的方法.分享给大家供大家参考,具体如下: 数据库版本:SQL Server 2012. 按照Python版本来选择下载pymssql模块,这样才能连接上sql server. 我安装的python版本是3.5 ,64位的,所以下载的pymssql模块是:pymssql-2.1.3-cp35-cp35m-win_amd64.whl 我把文件下载后放到E盘,安装pymssql模块: C:\Users\Administr
-
Python操作Sql Server 2008数据库的方法详解
本文实例讲述了Python操作Sql Server 2008数据库的方法.分享给大家供大家参考,具体如下: 最近由于公司的一个项目需要,需要使用Sql Server 2008数据库,开发语言使用Python,并基于windows平台上的Wing IDE4.0进行. 之前并未使用过Sql Server数据库,这次也当作一次练手,并把这次数据库前期开发过程中遇到的一些问题进行记录. 一.关于pyodbc库和pymssql库的选择 在使用python语言进行开发之前,需要确定使用哪种第三方的数据库操作
-
Linux下通过python访问MySQL、Oracle、SQL Server数据库的方法
本文档主要描述了Linux下python数据库驱动的安装和配置,用来实现在Linux平台下通过python访问MySQL.Oracle.SQL Server数据库. 其中包括以下几个软件的安装及配置: unixODBC FreeTDS pyodbc cx_Oracle 欢迎转载,请注明作者.出处. 作者:张正 QQ:176036317 如有疑问,欢迎联系. 本文档主要描述了Linux下python数据库驱动的安装和配置,用来实现在Linux平台下通过python访问MySQL.Oracle.SQ
-
SQL Server数据库基本概念、组成、常用对象与约束
目录 二.基本概念 1.数据库 2.数据库管理系统 3.数据库系统 二.数据库的组成 1.文件 2.文件组 三.数据库常用对象 1.表 2.字段 3.视图 4.索引 5.存储过程 6.触发器 7.约束 8.缺省值 四.数据库约束 一.定义 二.分类 1.主键约束 2.外键约束 3.Unique约束 4.Check约束 5.Default约束 二.基本概念 1.数据库 数据库(DB):即DataBase的缩写,是按照一定的数据结构来组织.存储和管理数据的一个仓库.是存储在一起的相关数据的一个集合.
-
SQL Server数据库入门学习总结
一图胜"十"言:SQL Server 数据库总结 一个大概的总结 经过一段时间的学习,也对数据库有了一些认识. 数据库基本是由表,关系,操作组成:对于初学者首先要学的: 1.数据库是如何存储数据的 表,约束,触发器 2.数据库是如何操作数据的 insert,update,delete T-sql 函数 存储过程 触发器 3.数据库是如何显示数据的 select SQLServer数据库学习总结 1.SQL基础 SQL Server2000安装.配置,服务器启动.停止,企业管理器.查询分
-
SQL Server 数据库的备份详细介绍及注意事项
SQL Server 备份 前言 为什么要备份?理由很简单--为了还原/恢复.当然,如果不备份,还可以通过磁盘恢复来找回丢失的文件,不过SQL Server很生气,后果很严重.到时候你就知道为什么先叫你备份一次再开始看文章了.∩__∩.本系列将介绍SQL Server所有可用的备份还原功能,并尽可能用实例说话. 什么是备份?SQL Server基于Windows,以文件形式存放资料,所以备份就是Windows上SQL Server相关文件的一个某个时间点的副本.根据备份类型的不同,副本的种类和内
-
SQL SERVER 数据库备份的三种策略及语句
1.全量数据备份 备份整个数据库,恢复时恢复所有.优点是简单,缺点是数据量太大,非常耗时 全数据库备份因为容易实施,被许多系统优先采用.在一天或一周中预定的时间进行全数据库备份使你不用动什么脑筋.使用这种类型的备份带来的问题是非常缺乏灵活性,而且当数据库被冲掉后,你面临丢失大量数据的潜在威胁.例如,假设你每天在午夜备份数据库. 如果服务器在晚上11点崩溃了,你将丢失前面23个小时对数据所做的全部修改.对大多数系统来说,这是无法接受的.对此规则,为数不多的例外如下: 1.系统中所存的数据可以很容易
-
SQL Server中Sequence对象用法
一.Sequence简介 Sequence对象对于Oracle用户来说是最熟悉不过的数据库对象了, 在SQL SERVER2012终于也可以看到这个对象了.Sequence是SQL Server2012推出的一个新特性.这个特性允许数据库级别的序列号在多表或多列之间共享. 二.Sequence基本概念 Oracle中有Sequence的功能,SQL server类似的功能要使用identity列实现,但是identity列有很大的局限性.微软终于在2012中添加了Sequence对象.与以往id