详解pandas删除缺失数据(pd.dropna()方法)
1.创建带有缺失值的数据库:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 随机产生5行3列的数据
df.ix[1, :-1] = np.nan # 将指定数据定义为缺失
df.ix[1:-1, 2] = np.nan
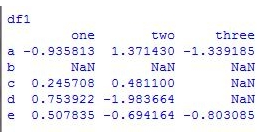
print('\ndf1') # 输出df1,然后换行
print(df)
查看数据内容:
2.通常情况下删除行,使用参数axis = 0,删除列的参数axis = 1,通常不会这么做,那样会删除一个变量。
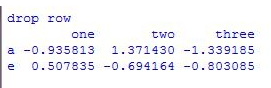
print('\ndrop row')
print(df.dropna(axis = 0))
删除后结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Pandas:Series和DataFrame删除指定轴上数据的方法
如下所示: import numpy as np import pandas as pd from pandas import Series,DataFrame 一.drop方法:产生新对象 1.Series o = Series([1,3,4,7],index=['d','c','b','a']) print(o.drop(['d','b'])) c 3 a 7 dtype: int64 2.DataFrame data = {'水果':['苹果','梨','草莓'], '数量':[3,2,5
-
pandas 数据归一化以及行删除例程的方法
如下所示: #coding:utf8 import pandas as pd import numpy as np from pandas import Series,DataFrame # 如果有id列,则需先删除id列再进行对应操作,最后再补上 # 统计的时候不需要用到id列,删除的时候需要考虑 # delete row def row_del(df, num_percent, label_len = 0): #print list(df.count(axis=1)) col_num = l
-
Pandas删除数据的几种情况(小结)
开始之前,pandas中DataFrame删除对象可能存在几种情况 1.删除具体列 2.删除具体行 3.删除包含某些数值的行或者列 4.删除包含某些字符.文字的行或者列 本文就针对这四种情况探讨一下如何操作. 数据准备 模拟了一份股票交割的记录. In [1]: import pandas as pd In [2]: data = { ...: '证券名称' : ['格力电器','视觉中国','成都银行','中国联通','格力电器','视觉中国','成都银行','中国联通'], ...: '摘要
-
详解pandas删除缺失数据(pd.dropna()方法)
1.创建带有缺失值的数据库: import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 随机产生5行3列的数据 df.ix[1, :-1] = np.nan # 将指定数据定义为缺失 df.ix[1:-1, 2] = np.nan print('\ndf1') # 输出df1,
-

Pandas||过滤缺失数据||pd.dropna()函数的用法说明
看代码吧~ DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values. pd.dropna()函数(官方文档)用于过滤数据中的缺失数据. 缺失数据在pandas中用NaN标记. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index = lis
-
详解pandas中缺失数据处理的函数
目录 一.缺失值类型 1.np.nan 2.None 3.NA标量 二.缺失值判断 1.对整个dataframe判断缺失 2.对某个列判断缺失 三.缺失值统计 1.列缺失 2.行缺失 3.缺失率 四.缺失值筛选 五.缺失值填充 六.缺失值删除 1.全部直接删除 2.行缺失删除 3.列缺失删除 4.按缺失率删除 七.缺失值参与计算 1.加法 2.累加 3.计数 4.聚合分组 五.源码 今天分享一篇pandas缺失值处理的操作指南! 一.缺失值类型 在pandas中,缺失数据显示为NaN.缺失值有3
-
详解pandas apply 并行处理的几种方法
1. pandarallel (pip install ) 对于一个带有Pandas DataFrame df的简单用例和一个应用func的函数,只需用parallel_apply替换经典的apply. from pandarallel import pandarallel # Initialization pandarallel.initialize() # Standard pandas apply df.apply(func) # Parallel apply df.parallel_ap
-
详解pandas绘制矩阵散点图(scatter_matrix)的方法
使用散点图矩阵图,可以两两发现特征之间的联系 pd.plotting.scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds) 1.frame,pandas dataframe对象 2.alpha, 图像透明度,一般取(0,1] 3.figsize,以英寸为单
-
详解pandas的外部数据导入与常用方法
外部数据导入 导入excel文件 pandas导入excel用read_excel()方法: import pandas as pd excel_file1 = pd.read_excel('data/测试.xlsx',encoding='utf-8') 姓名 年龄 工作 工资 0 张三 25 学生 200 1 李四 24 工人 3000 2 王伟 28 NaN 5000 3 王二毛 22 自由职业 6000
-
详解springmvc之json数据交互controller方法返回值为简单类型
当controller方法的返回值为简单类型比如String时,该如何与json交互呢? 使用@RequestBody 比如代码如下: @RequestMapping(value="/ceshijson",produces="application/json;charset=UTF-8") @ResponseBody public String ceshijson(@RequestBody String channelId) throws IOException{
-
详解mybatis 批量更新数据两种方法效率对比
上节探讨了批量新增数据,这节探讨批量更新数据两种写法的效率问题. 实现方式有两种, 一种用for循环通过循环传过来的参数集合,循环出N条sql, 另一种 用mysql的case when 条件判断变相的进行批量更新 下面进行实现. 注意第一种方法要想成功,需要在db链接url后面带一个参数 &allowMultiQueries=true 即: jdbc:mysql://localhost:3306/mysqlTest?characterEncoding=utf-8&allowMulti
-
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详解Pandas如何高效对比处理DataFrame的两列数据
目录 楔子 combine_first combine update 楔子 我们在用 pandas 处理数据的时候,经常会遇到用其中一列数据替换另一列数据的场景.比如 A 列和 B 列,对 A 列中不为空的数据不作处理,对 A 列中为空的数据使用 B 列对应索引的数据进行替换.这一类的需求估计很多人都遇到,当然还有其它更复杂的. 解决这类需求的办法有很多,这里我们来推荐几个. combine_first 这个方法是专门用来针对空值处理的,我们来看一下用法. import pandas as pd