详解Pandas之容易让人混淆的行选择和列选择
在刚学Pandas时,行选择和列选择非常容易混淆,在这里进行一下讨论和归纳
本文的数据来源:https://github.com/fivethirtyeight/data/tree/master/fandango
import pandas as pd
fandango = pd.read_csv('fandango_score_comparison.csv')
原始的数据如下(截取了一部分)
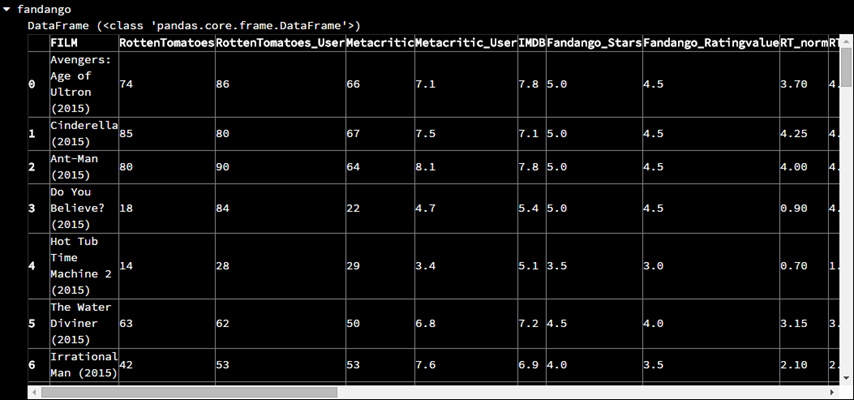
行选择
Pandas进行行选择一般有三种方法:
- 连续多行的选择用类似于python的列表切片
- 按照指定的索引选择一行或多行,使用loc[]方法
- 按照指定的位置选择一行多多行,使用iloc[]方法
第一种,使用类似于python的列表切片
n = fandango[1:3]

从结果可以看到,和python的列表切片一样,索引号从0开始,选择了索引号1和2的数据(不包括3)
第二种,按照指定的索引选择一行或多行,使用loc[]方法
o = fandango.loc[1] p = fandango.loc[1:3]

可以看到,o是一个Series,选择了索引号为1的那一行数据,注意p,它与第一种的列表索引最大的不同是包含了索引号为3的那一行数据
u = fandango.loc[[1,3]]
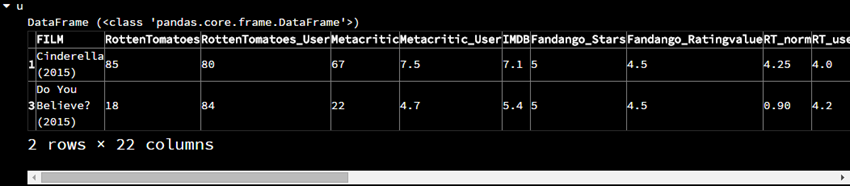
这里按照索引号选择不连续的行
第三种,按照指定的位置选择一行多多行,使用iloc[]方法
在上面的数据中,使用iloc[]和loc[]的效果是一样的,因为索引号都是从0开始并且连续不断,现在我要删除索引号为1和2的这两行
fandango_drop = fandango.drop([1,2], axis=0)
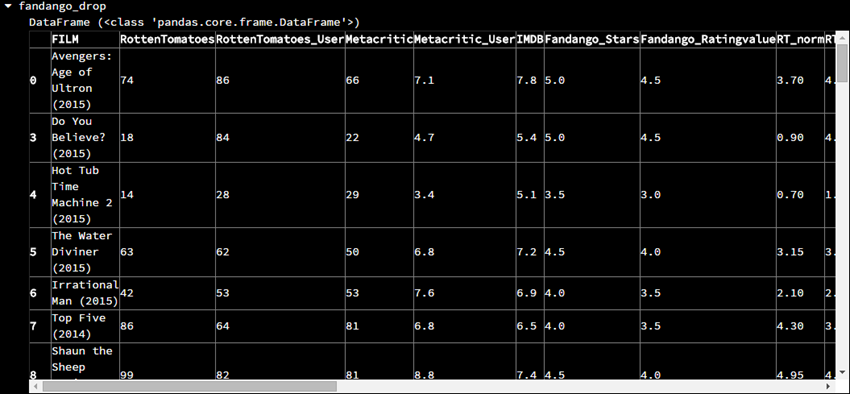
可以看到的确删除了两行数据
此时我仍然用loc[]来索引行号为2的那一行,就会出错
s = fandango_drop.loc[2]
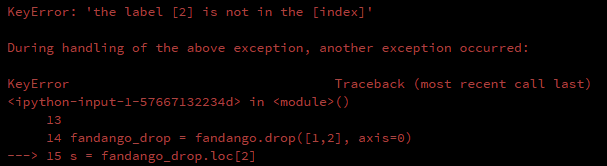
但是,我使用iloc[]来进行一次
t = fandango_drop.iloc[2]

看到了吧,iloc[2]的意思是选择第三行的数据,也就是索引号为4的那一行数据,因为iloc[]的计算也是从0开始的,所以iloc[]适用于数据进行了筛选后造成索引号与原来不一致的情况
loc[]与iloc[]方法之间还有一个巨大的差别,那就是loc[]里的参数是对应的索引值即可,所以参数可以是整数,也可以是字符串。而iloc[]里的参数表示的是第几行的数据,所以只能是整数
列选择
列选择比较简单,只要直接把列名传递过去即可,如果有多列的数据,要单独指出列名或列的索引号
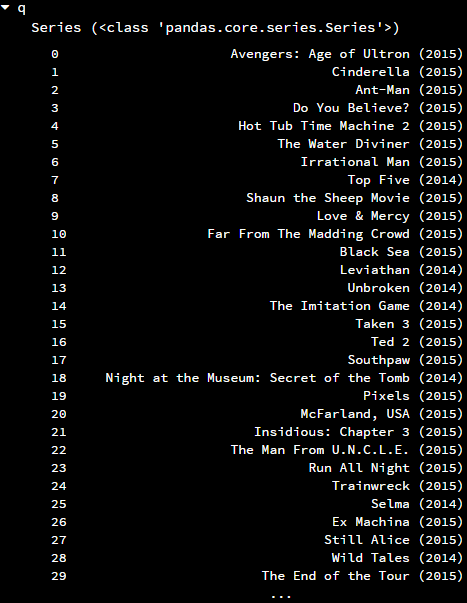
第一种,选择单列,选择了电影名称那一列
q = fandango['FILM']
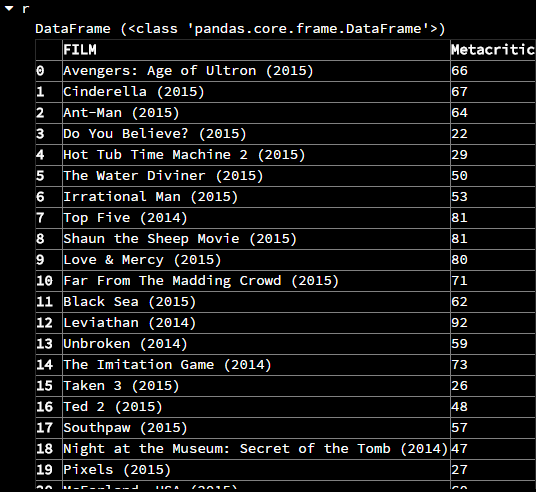
第二种,通过指定列名选择多列
r = fandango[['FILM','Metacritic']]
第三种,非常容易让人混淆的,通过列的索引号选择多列
v = fandango[[0,1,2]]

其实,列也是有一个索引号的,看到这里不禁想问,那我要选择前5列呢?我不想写一个长列表,又不想逐个写出这5列的名称,能否用切片呢?
x = fandango[[0:5]]
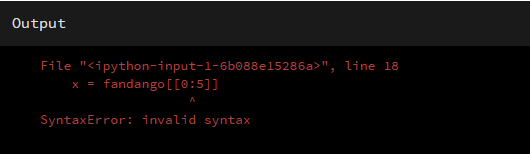
事实证明,这是不行的,更好的方法是在参数中构建一个列表
w = fandango[list(range(5))]
更多的参考资料:http://pandas.pydata.org/pandas-docs/version/0.17.0/api.html
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
对pandas的行列名更改与数据选择详解
记录一些pandas选择数据的内容,此前首先说行列名的获取和更改,以方便获取数据.此文作为学习巩固. 这篇博的内容顺序大概就是: 行列名的获取 -> 行列名的更改 -> 数据选择 一.pandas的行列名获取和更改 1. 获取: df.index() df.columns() 首先,举个例子,做一个DataFrame如下: >>>import pandas as pd >>>import numpy as np >>>data = pd.D
-
python pandas dataframe 行列选择,切片操作方法
SQL中的select是根据列的名称来选取:Pandas则更为灵活,不但可根据列名称选取,还可以根据列所在的position(数字,在第几行第几列,注意pandas行列的position是从0开始)选取.相关函数如下: 1)loc,基于列label,可选取特定行(根据行index): 2)iloc,基于行/列的position: 3)at,根据指定行index及列label,快速定位DataFrame的元素: 4)iat,与at类似,不同的是根据position来定位的: 5)ix,为loc与i
-
pandas 选择某几列的方法
如下所示: col_n = ['名称','收盘价','日期'] a = pd.DataFrame(df,columns = col_n) 以上这篇pandas 选择某几列的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-

详解Pandas之容易让人混淆的行选择和列选择
在刚学Pandas时,行选择和列选择非常容易混淆,在这里进行一下讨论和归纳 本文的数据来源:https://github.com/fivethirtyeight/data/tree/master/fandango import pandas as pd fandango = pd.read_csv('fandango_score_comparison.csv') 原始的数据如下(截取了一部分) 行选择 Pandas进行行选择一般有三种方法: 连续多行的选择用类似于python的列表切片 按照指
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
详解Pandas如何高效对比处理DataFrame的两列数据
目录 楔子 combine_first combine update 楔子 我们在用 pandas 处理数据的时候,经常会遇到用其中一列数据替换另一列数据的场景.比如 A 列和 B 列,对 A 列中不为空的数据不作处理,对 A 列中为空的数据使用 B 列对应索引的数据进行替换.这一类的需求估计很多人都遇到,当然还有其它更复杂的. 解决这类需求的办法有很多,这里我们来推荐几个. combine_first 这个方法是专门用来针对空值处理的,我们来看一下用法. import pandas as pd
-
详解pandas绘制矩阵散点图(scatter_matrix)的方法
使用散点图矩阵图,可以两两发现特征之间的联系 pd.plotting.scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds) 1.frame,pandas dataframe对象 2.alpha, 图像透明度,一般取(0,1] 3.figsize,以英寸为单
-
详解pandas获取Dataframe元素值的几种方法
可以通过遍历的方法: pandas按行按列遍历Dataframe的几种方式:https://www.jb51.net/article/172623.htm 选择列 使用类字典属性,返回的是Series类型 data['w'] 遍历Series for index in data['w'] .index: time_dis = data['w'] .get(index) pandas.DataFrame.at 根据行索引和列名,获取一个元素的值 >>> df = pd.DataFrame(
-
详解pandas.DataFrame.plot() 画图函数
首先看官网的DataFrame.plot( )函数 DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False,
-
详解Pandas 处理缺失值指令大全
前言 运用pandas 库对所得到的数据进行数据清洗,复习一下相关的知识. 1 数据清洗 1.1 处理缺失数据 对于数值型数据,分为缺失值(NAN)和非缺失值,对于缺失值的检测,可以通过Python中pandas库的Series类对象的isnull方法进行检测. import pandas as pd import numpy as np string_data = pd.Series(['Benzema', 'Messi', np.nan, 'Ronaldo']) string_data.is
-
详解pandas赋值失败问题解决
一.pandas对整列赋值 这个比较正常,一般直接赋值就可以: x = pd.DataFrame({'A': ['1', '2', '3', None, None], 'B': ['4', '5', '6', '7', None]}) x['A'] = ['10', '11', '12', '13', '14'] 二.pandas对非整列赋值 1.用单个值赋值 x = pd.DataFrame({'A': ['1', '2', '3', None, None], 'B': ['4', '5',
-
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详解pandas映射与数据转换
在 pandas 中提供了利用映射关系来实现某些操作的函数,具体如下: replace() 函数:替换元素: map() 函数:新建一列: rename() 函数:替换索引. 一.replace() 用映射替换元素 在数据处理时,经常会遇到需要将数据结构中原来的元素根据实际需求替换成新元素的情况.要想用新元素替换原来元素,就需要定义一组映射关系.在映射关系中,将旧元素作为键,新元素作为值. 例如,创建字典 fruits 用于指明水果标识和水果名称的映射关系. fruits={101:'orang