基于MATLAB和Python实现MFCC特征参数提取
1、MFCC概述
在语音识别(Speech Recognition)和话者识别(Speaker Recognition)方面,最常用到的语音特征就是梅尔倒谱系数(Mel-scale FrequencyCepstral Coefficients,简称MFCC)。根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。从200Hz到5000Hz的语音信号对语音的清晰度影响较大。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。由于频率较低的声音在内耳蜗基底膜上行波传递的距离大于频率较高的声音,故一般来说,低音容易掩蔽高音,而高音掩蔽低音较困难。在低频处的声音掩蔽的临界带宽较高频要小。所以,人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。因此,这种参数比基于声道模型的LPCC相比具有更好的鲁邦性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
梅尔倒谱系数是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示:

式中f为频率,单位为Hz。下图为Mel频率与线性频率的关系:

2、 MFCC特征参数提取过程详解

(1)预处理
预处理包括预加重、分帧、加窗函数。
预加重:预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。预加重处理其实是将语音信号通过一个高通滤波器:

分帧:先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。
加窗:将每一帧乘以汉明窗,以增加帧左端和右端的连续性。假设分帧后的信号为S(n), n=0,1…,N-1, N为帧的大小,那么乘上汉明窗

后 ,W(n)形式如下:

(2)FFT
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。
(3)谱线能量
对语音信号的频谱取模平方得到语音信号的谱线能量。
(4)计算通过Mel滤波器的能量
将能量谱通过一组Mel尺度的三角形滤波器组,定义一个有M个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为f(m) 。M通常取22-26。各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,如图所示:
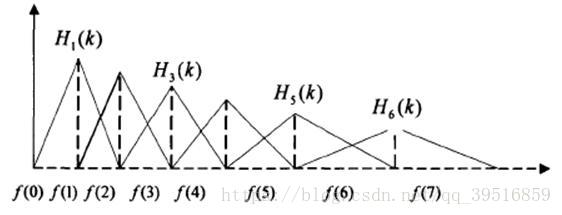
三角滤波器的频率响应定义为:

对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。(因此一段语音的音调或音高,是不会呈现在MFCC 参数内,换句话说,以MFCC 为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响)此外,还可以降低运算量。
计算每个滤波器组输出的对数能量为 :

(5)计算DCT倒谱
经离散余弦变换(DCT)得到MFCC系数 :

将上述的对数能量带入离散余弦变换,求出L阶的Mel参数。L阶指MFCC系数阶数,通常取12-16。这里M是三角滤波器个数。
3、MATLAB实现方法
注:在提取MFCC参数之前需要加载并使用VOICEBOX工具包
Df=5;
fs=8000;
N=fs/Df;
t=0:1./fs:(N-1)./fs;
x=sin(2*pi*200*t);
bank=melbankm(24,256,8000,0,0.5,'t');%Mel滤波器的阶数为24,fft变换的长度为256,采样频率为8000Hz
%归一化mel滤波器组系数
bank=full(bank);
bank=bank/max(bank(:));
% DCT系数,12*p
for k=1:12
n=0:23;
dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24));
end
%归一化倒谱提升窗口
w=1+6*sin(pi*[1:12]./12);
%w=w/max(w);
%语音信号分帧
xx=enframe(x,256,80);%对x 256点分为一帧
%计算每帧的MFCC参数
for i=1:size(xx,1)
y=xx(i,:);
s=y'.*hamming(256);
t=abs(fft(s));%fft快速傅立叶变换
t=t.^2;
c1=dctcoef*log(bank*t(1:129));
c2=c1.*w';
end
plot(c2);title('MFCC');
结果:

4、Python实现方法
import numpy as np
from scipy import signal
from scipy.fftpack import dct
import pylab as plt
def enframe(wave_data, nw, inc, winfunc):
'''将音频信号转化为帧。
参数含义:
wave_data:原始音频型号
nw:每一帧的长度(这里指采样点的长度,即采样频率乘以时间间隔)
inc:相邻帧的间隔(同上定义)
'''
wlen=len(wave_data) #信号总长度
if wlen<=nw: #若信号长度小于一个帧的长度,则帧数定义为1
nf=1
else: #否则,计算帧的总长度
nf=int(np.ceil((1.0*wlen-nw+inc)/inc))
pad_length=int((nf-1)*inc+nw) #所有帧加起来总的铺平后的长度
zeros=np.zeros((pad_length-wlen,)) #不够的长度使用0填补,类似于FFT中的扩充数组操作
pad_signal=np.concatenate((wave_data,zeros)) #填补后的信号记为pad_signal
indices=np.tile(np.arange(0,nw),(nf,1))+np.tile(np.arange(0,nf*inc,inc),(nw,1)).T #相当于对所有帧的时间点进行抽取,得到nf*nw长度的矩阵
indices=np.array(indices,dtype=np.int32) #将indices转化为矩阵
frames=pad_signal[indices] #得到帧信号
win=np.tile(winfunc,(nf,1)) #window窗函数,这里默认取1
return frames*win #返回帧信号矩阵
Df=5
fs=8000
N=fs/Df
t = np.arange(0,(N-1)/fs,1/fs)
wave_data=np.sin(2*np.pi*200*t)
#预加重
#b,a = signal.butter(1,1-0.97,'high')
#emphasized_signal = signal.filtfilt(b,a,wave_data)
#归一化倒谱提升窗口
lifts=[]
for n in range(1,13):
lift =1 + 6 * np.sin(np.pi * n / 12)
lifts.append(lift)
#print(lifts)
#分帧、加窗
winfunc = signal.hamming(256)
X=enframe(wave_data, 256, 80, winfunc) #转置的原因是分帧函数enframe的输出矩阵是帧数*帧长
frameNum =X.shape[0] #返回矩阵行数18,获取帧数
#print(frameNum)
for i in range(frameNum):
y=X[i,:]
#fft
yf = np.abs(np.fft.fft(y))
#print(yf.shape)
#谱线能量
yf = yf**2
#梅尔滤波器系数
nfilt = 24
low_freq_mel = 0
NFFT=256
high_freq_mel = (2595 * np.log10(1 + (fs / 2) / 700)) # 把 Hz 变成 Mel
mel_points = np.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # 将梅尔刻度等间隔
hz_points = (700 * (10**(mel_points / 2595) - 1)) # 把 Mel 变成 Hz
bin = np.floor((NFFT + 1) * hz_points / fs)
fbank = np.zeros((nfilt, int(np.floor(NFFT / 2 + 1))))
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
filter_banks = np.dot(yf[0:129], fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks) # 数值稳定性
filter_banks = 10 * np.log10(filter_banks) # dB
filter_banks -= (np.mean(filter_banks, axis=0) + 1e-8)
#print(filter_banks)
#DCT系数
num_ceps = 12
c2 = dct(filter_banks, type=2, axis=-1, norm='ortho')[ 1 : (num_ceps + 1)] # Keep 2-13
c2 *= lifts
print(c2)
plt.plot(c2)
plt.show()
结果:
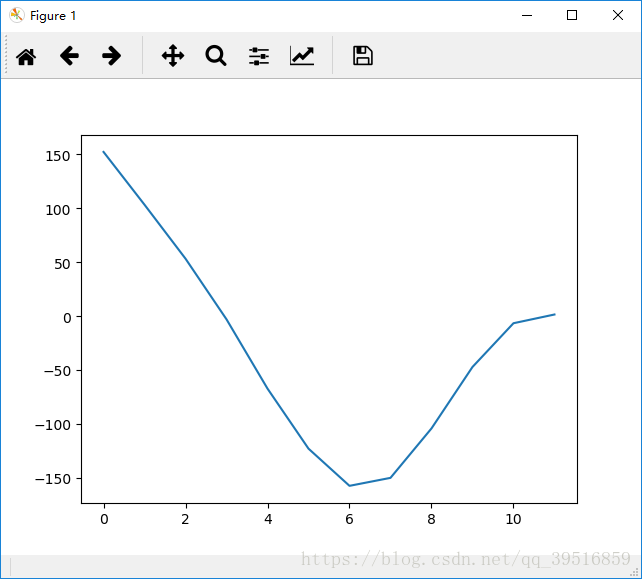
由MATLAB和Python绘制出来的波形可以看出二者计算出来的MFCC倒谱系数的基本走势相同。
参考:http://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

梅尔频率倒谱系数(mfcc)及Python实现
语音识别系统的第一步是进行特征提取,mfcc是描述短时功率谱包络的一种特征,在语音识别系统中被广泛应用. 一.mel滤波器 每一段语音信号被分为多帧,每帧信号都对应一个频谱(通过FFT变换实现),频谱表示频率与信号能量之间的关系.mel滤波器是指多个带通滤波器,在mel频率中带通滤波器的通带是等宽的,但在赫兹(Hertz)频谱内mel滤波器在低频处较密集切通带较窄,高频处较稀疏且通带较宽,旨在通过在较低频率处更具辨别性并且在较高频率处较少辨别性来模拟非线性人类耳朵对声音的感知. 赫兹频率和梅尔频
-
对python中Librosa的mfcc步骤详解
1.对语音数据归一化 如16000hz的数据,会将每个点/32768 2.计算窗函数:(*注意librosa中不进行预处理) 3.进行数据扩展填充,他进行的是镜像填充("reflect") 如原数据为 12345 -> 填充为4的,左右各填充4 即:5432123454321 即:5432-12345-4321 4.分帧 5.加窗:对每一帧进行加窗, 6.进行fft傅里叶变换 librosa中fft计算,可以使用.net中的System.Numerics MathNet.Nume
-
对Python使用mfcc的两种方式详解
1.Librosa import librosa filepath = "/Users/birenjianmo/Desktop/learn/librosa/mp3/in.wav" y,sr = librosa.load(filepath) mfcc = librosa.feature.mfcc( y,sr,n_mfcc=13 ) 返回结构为(13,None)的np.Array,None表示任意数量 2.python_speech_features from python_speech_
-
利用python提取wav文件的mfcc方法
如下所示: import scipy.io.wavfile as wav from python_speech_features import mfcc fs, audio = wav.read("abc.wav") feature_mfcc = mfcc(audio, samplerate=fs) print(feature_mfcc) print(feature_mfcc.shape) 注:python_speech_features 不存在, 通过 pip install pyt
-
基于MATLAB和Python实现MFCC特征参数提取
1.MFCC概述 在语音识别(Speech Recognition)和话者识别(Speaker Recognition)方面,最常用到的语音特征就是梅尔倒谱系数(Mel-scale FrequencyCepstral Coefficients,简称MFCC).根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度.从200Hz到5000Hz的语音信号对语音的清晰度影响较大.两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,
-
基于matlab实现DCT数字水印嵌入与提取
目录 一.离散小波变换的音频信号数字水印技术简介 0 引言 1 音频数字水印技术分类 2 基于DWT的音频水印算法 二.部分源代码 三.运行结果 一.离散小波变换的音频信号数字水印技术简介 0 引言 近年来, 数字水印技术的作用越来越重要.数字水印技术是将一些标识信息直接嵌入数字载体当中, 或间接表示在信号载体中, 且不影响原载体的使用价值.通过隐藏在载体中的这些信息, 可以判断信息是否被篡改, 具有防伪溯源.保护信息安全.版权保护等作用.对于广播转播台站而言, 是广播音频的中转站, 在广播信号
-
基于matlab对比度和结构提取的多模态解剖图像融合实现
目录 一.图像融合简介 二.部分源代码 三.运行结果 四.matlab版本 一.图像融合简介 应用多模态图像的配准与融合技术,可以把不同状态的医学图像有机地结合起来,为临床诊断和治疗提供更丰富的信息.介绍了多模态医学图像配准与融合的概念.方法及意义.最后简单介绍了小波变换分析方法. 二.部分源代码 clear; close all; clc; warning off %% A Novel Multi-Modality Anatomical Image FusionMethod Based on
-
基于matlab MFCC+GMM的安全事件声学检测系统
一.安全事件声学检测简介(附lunwen) 1 选题背景 公共安全问题是社会安全稳定所聚焦的话题之一.近年来,检测技术与监控自动化正深刻地改变着人们的生活.尤其在安防领域,闭路电视CCTV(Closed Circuit Television).视频流分析.智能监控等新技术得到了广泛应用,大大提高了安防监控的管理效率.然而值得注意的是,基于视频流的监控手段不可避免地也具有一定的先天性缺漏,例如存在视野盲区.易受光照影响等问题,对于事件检测,还可能存在语义不明的问题,监控手段不够全面.纯视频手段在枪
-
基于Python和TFIDF实现提取文本中的关键词
目录 前言 词频逆文档频率(TFIDF) Term Frequency Inverse Document Frequency TFIDF Python 中的 TFIDF Python 库准备 准备数据集 文本预处理 TFIDF关键词提取 1.生成 n-gram 并对其进行加权 2. 按 TFIDF 权重对关键短语进行排序 性能评估 附录 前言 关键词提取是从简明概括长文本内容的文档中,自动提取一组代表性短语.关键词是一个简短的短语(通常是一到三个单词),高度概括了文档的关键思想并反映一个文档的内
-
基于Matlab实现数字音频分析处理系统
目录 一.语音处理简介 1语音信号的特点 2语音信号的采集 3语音信号分析技术 4语音信号的时域分析 5语音信号的频域分析 二.部分源代码 三.运行结果 一.语音处理简介 1 语音信号的特点 通过对大量语音信号的观察和分析发现,语音信号主要有下面两个特点: ①在频域内,语音信号的频谱分量主要集中在300-3400Hz的范围内.利用这个特点,可以用一个防混迭的带通滤波器将此范围内的语音信号频率分量取出,然后按8kHz的采样率对语音信号进行采样,就可以得到离散的语音信号. ②在时域内,语音信号具有“
-
实例详解Matlab 与 Python 的区别
一.Python简介 Python是一种面向对象的解释型计算机程序设计语言.Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议[2] .Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进. Python执行: Python在执行时,首先会将.py文件中的源代码编译成Python的byte code(字节码),然后再由Python Virtual Machine(Python虚拟机
-
python 三种方法提取pdf中的图片
有时我们需要将一份或者多份PDF文件中的图片提取出来,如果采取在线的网站实现的话又担心图片泄漏,手动操作又觉得麻烦,其实用Python也可以轻松搞定! 今天就跟大家系统分享几种Python提取 PDF 图片的方法.其实没有非常完美的方法,每种方法提取效率都不是百分之百,因此可以考虑用多种方法进行互补,主要将涉及: 基于 fitz 库和正则搜索提取图片 基于 pdf2image 库的两种方法提取图片 基于 fitz 库和正则搜索 fitz 是 pymupdf 的子模块,需要先用命令行安装 pymu
-
基于Matlab实现BP神经网络交通标志识别
目录 一.BP神经网络交通标志识别简介 二.部分源代码 三.运行结果 一.BP神经网络交通标志识别简介 道路交通标志用以禁止.警告.指示和限制道路使用者有秩序地使用道路, 保障出行安全.若能自动识别道路交通标志, 则将极大减少道路交通事故的发生.但是由于道路交通错综复杂, 且智能识别技术尚未成熟, 为了得到高效实用的道路标志识别系统, 仍需进行大量的研究.限速交通标志的检测识别作为道路交通标志识别系统的一个重要组成部分, 对它的研究具有非常重要的意义. 目前国内已有不少学者针对道路交通标志牌的智
-
基于Matlab LBP实现植物叶片识别功能
目录 一.LBP简介 1.1 课题的提出与研究意义 1.2 国内外相关研究情况 1.3 论文的主要研究工作 1.4 论文结构 二.部分源代码 三.运行结果 一.LBP简介 第一章 引言 植物在我们的身边随处可见,它们从产生发展进化到现在,其间经历了漫长的岁月.地球上的植物种类繁多.数量浩瀚,它们是生物圈的重要组成部分,在维持整个生物界的平衡方面发挥着巨大的作用:它们同时也是构成人类生存环境的重要组成部分,是人类社会延续和发展不可或缺的重要因素.由于植物对于地球和人类都具有如此重要的意义,对它们的