详解基于docker 如何部署surging分布式微服务引擎
1、前言
转眼间surging 开源已经有1年了,经过1年的打磨,surging已从最初在window 部署的分布式微服务框架,到现在的可以在docker部署利用rancher 进行服务编排的分布式微服务引擎,再把业务进行剥离, 通过配置路径就能驱动加载业务模块,这样的细粒度设计,能更加灵活从业务中针对于对象加以细分,能更加灵活的拆分聚合服务。而这篇文章我们来谈谈基于docker 如何部署
2、概述
容器,就是用来存放镜像的器皿,而镜像是构建成的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。
程序被构建成镜像放到容器中,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。所以为何容器能流行起来, 而容器技术兴起让Docke也渐渐的映入大家的眼帘,

那么Docker又是什么呢?
- Docker是基于Go语言开发并开源的容器引擎
- Docker将应用软件运行时所需的一切都打包成互相隔离的容器
- Docker可以自动执行并配置开发/线上环境,快速构建,测试和运行复杂的多容器应用程序
- 对拥有数千个节点或容器的应用程序,Docker也能快速的扩展和调配
- 可以运行在主流的Linux系统,Mac以及Windows上,并且保证无论软件在哪里部署,都能正常运行并得到相同的结果
相关概念介绍
Image镜像和Container容器:你可以把两者理解为类和实例对象,或者是ISO系统镜像和虚拟机的关系。不同的Image所包含的软件或者环境是不同的,但是你可以使用Dockerfile(docker特有语法规则所创建的文件)进行管理。而Container则是以Image作为模板,可以独立运行的微型系统,一个Image可以创建出来多个Container容器的实例
Registry:Docker Hub镜像仓库,为每个人提供庞大的镜像资源进行拉取和使用
Dockerfile:是一个将镜像命令组合在一起的文件,用于Image的自动构建
3、环境搭建
系统环境
宿主机:Windows 10 专业版
Linux服务器: CentOS 3.10
1.安装Docker
Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 。
通过 uname -r 命令查看你当前的内核版本
[root@runoob ~]# uname -r 3.10.0-862.E17.X86_64
# yum install docker-engine 安装docker包
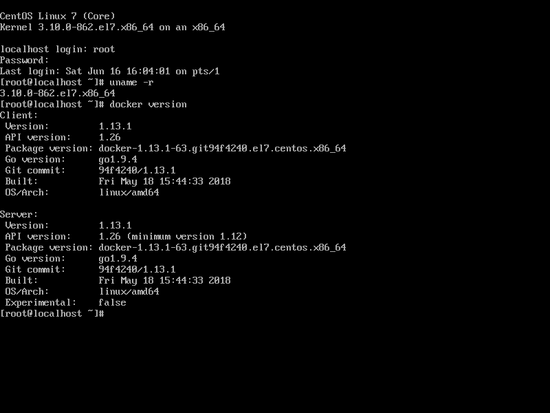
安装成功后,使用docker version命令查看是否安装成功,安装成功后------如下图
启动 Docker
systemctl start docker
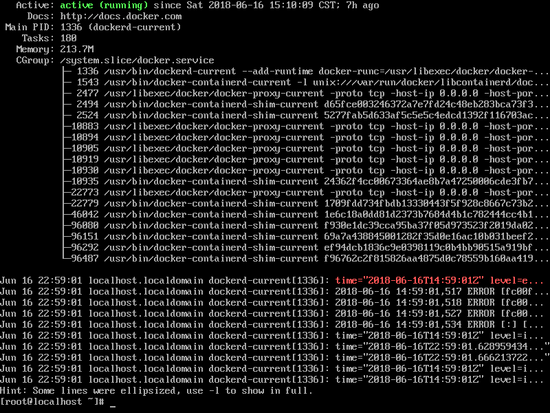
查看docker信息,如下图
systemctl status docker
测试运行 hello-world
#docker run hello-world
2.安装rancher
下载镜像
docker pull rancher/server
启动 rancher
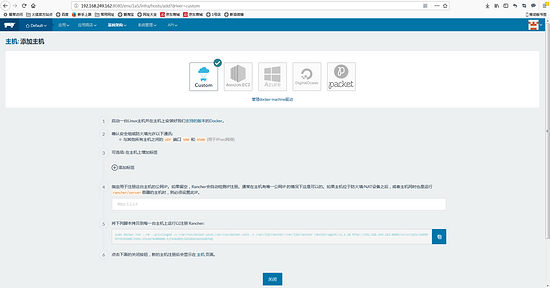
docker run -d --restart=always -p 8080:8080 rancher/server
安装成功后,通过http://ip:8080访问,如下图所示
3.安装rabbitmq
下载镜像
docker run -d --restart=always -p 8080:8080 rancher/server
#docker run -d --name rabbitmq --publish 5672:5672 --publish 4369:4369 --publish 25672:25672 --publish 15671:15671 --publish 15672:15672 \rabbitmq:management
安装成功后,通过http://ip:15672访问,如下图所示

4.安装Consul
下载镜像
#docker pull docker.io/consul:latest
创建 Consul 配置
#vim /opt/platform/consul/server.json
{
"datacenter": "quark-consul",
"data_dir": "/consul/data",
"server": true,
"ui": true,
"bind_addr": "192.168.249.162",
"client_addr": "192.168.249.162",
"bootstrap_expect": 1,
"retry_interval": "10s",
"rejoin_after_leave": false,
"skip_leave_on_interrupt": true
}
配置说明
官方在启动容器的时候是将一部分配置作为 docker run 的参数,而我是把参数写到了配置文件里。
- datacenter:数据中心名称(库名)
- data_dir:数据存储目录
- server:运行在server模式
- ui:使用UI界面
- bind_addr:内部集群通信绑定的地址。默认是 0.0.0.0 ,如果有多块网卡,需要指定,否则启动报错
- client_addr:客户端接口绑定的地址,默认是 127.0.0.1 ;
- retry_join:重新加入集群
- retry_interval:重试时间
- rejoin_after_leave:在离开集群之后才重试加入
- skip_leave_on_interrupt:在启动后,是否 Ctrl+C 优雅退出,我们是容器模式,所以不用管,直接 true 就好了。
启动 consul-server
docker run -d --net=host --name consul -v /opt/platform/consul/config:/consul/config -v /opt/platform/consul/data:/consul/data consul agent
安装成功后,通过http://ip:8500访问,如下图所示

5. 安装dotnetcore 2.1 runtime
下载镜像
#sudo docker pull microsoft/dotnet:2.1-runtime
启动
#sudo docker run -it microsoft/dotnet:2.1-runtime
三、部署程序
1. 部署surging引擎,无需引用任何业务模块,新建Dockerfile文件
FROM microsoft/dotnet:2.1-runtime WORKDIR /app COPY . . ENTRYPOINT ["dotnet", "Surging.Services.Server.dll"]
发布程序
dotnet publish -r centos.7-x64 -c release
使用Dockerfile创建镜像
#docker build -t surgingserver .
启动
#docker run --name surgingserver --env Mapping_ip=192.168.249.162 --env Mapping_Port=198 --env RootPath=/home/fanly --env Register_Conn=192.168.249.162:8500 --env EventBusConnection=172.17.0.4 --env Surging_Server_IP=0.0.0.0 -v /home/fanly:/home/fanly -it -p 198:198 surgingserver
配置说明
- Mapping_ip:映射的外部IP(环境变量)
- Mapping_port :映射的外部端口 (环境变量)
- RootPath:业务模块存储的根路径 (环境变量)
- Register_Conn:注册中心地址 (环境变量)
- EventBusConnection:eventbus 地址 (环境变量)
- Surging_Server_IP:容器内部IP (环境变量)
启动后在rancher如下图所示

因为方便,把宿主机的目录进行了挂载,microsurging 为分布式微服务引擎,Modules 为业务模块目录,surgingapi为网关

2. 部署surging网关, 新建Dockerfile文件
FROM microsoft/dotnet:2.1-runtime WORKDIR /app COPY . . ENTRYPOINT ["dotnet", "Surging.ApiGateway.dll"]
发布程序
dotnet publish -r centos.7-x64 -c release
使用Dockerfile创建镜像
docker build -t surgingapi .
启动
#docker run --name surgingapi -it -p 729:729 --env Register_Conn=192.168.249.162:8500 surgingapi
启动后在rancher如下图所示

可以通过http://ip:729进行访问


然后可以通过postman 来测试网关,如下图

四、总结
通过1年的开发,surging 也趋于完善,性能非常不错,平均访问在0.12ms 左右
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解Spring Boot微服务如何集成fescar解决分布式事务问题
什么是fescar? 关于fescar的详细介绍,请参阅fescar wiki. 传统的2PC提交协议,会持有一个全局性的锁,所有局部事务预提交成功后一起提交,或有一个局部事务预提交失败后一起回滚,最后释放全局锁.锁持有的时间较长,会对并发造成较大的影响,死锁的风险也较高. fescar的创新之处在于,每个局部事务执行完立即提交,释放本地锁:它会去解析你代码中的sql,从数据库中获得事务提交前的事务资源即数据,存放到undo_log中,全局事务协调器在回滚的时候直接使用undo_log中的数据覆
-

springboot 打包部署 共享依赖包(分布式开发集中式部署微服务)
1.此文初衷 平常我们在进行微服务开发完毕后,单个微服务理应部署单个虚机上(docker也可),然后服务集中发布到服务注册中心上,但是有些小的项目,这样做未免太过繁杂增加了部署难度,这里主要讲述的是如何在单机上通过共享jar包的方式来部署多个微服务,解决以上部署难度同时在带宽不够或者网速慢的情况下如何快速的发布部署. 2.部署目录结构 部署目录解答-> 各个微服务与依赖包(lib文件夹下)在同一级目录下,此为图1内容.图二内容展示的是单个微服务内的文件结构,部署配置文件以及所打的jar包,这
-
Spring Cloud微服务架构的构建:分布式配置中心(加密解密功能)
前言 要会用,首先要了解.图懒得画,借鉴网上大牛的图吧,springcloud组建架构如图: 微服务架构的应用场景: 1.系统拆分,多个子系统 2.每个子系统可部署多个应用,应用之间负载均衡实现 3.需要一个服务注册中心,所有的服务都在注册中心注册,负载均衡也是通过在注册中心注册的服务来使用一定策略来实现. 4.所有的客户端都通过同一个网关地址访问后台的服务,通过路由配置,网关来判断一个URL请求由哪个服务处理.请求转发到服务上的时候也使用负载均衡. 5.服务之间有时候也需要相互访问.例如有一个
-
微服务和分布式的区别详解
分布式架构是分布式计算技术的应用和工具,目前成熟的技术包括J2EE, CORBA和.NET(DCOM),这些技术牵扯的内容非常广,相关的书籍也非常多,也没有涉及这些技术的细节,只是从各种分布式系统平台产生的背景和在软件开发中应用的情况来探讨它们的主要异同. 微服务架构是一项在云中部署应用和服务的新技术.大部分围绕微服务的争论都集中在容器或其他技术是否能很好的实施微服务,而红帽说API应该是重点. 微服务可以在"自己的程序"中运行,并通过"轻量级设备与HTTP型API进行沟通&
-
详解基于docker 如何部署surging分布式微服务引擎
1.前言 转眼间surging 开源已经有1年了,经过1年的打磨,surging已从最初在window 部署的分布式微服务框架,到现在的可以在docker部署利用rancher 进行服务编排的分布式微服务引擎,再把业务进行剥离, 通过配置路径就能驱动加载业务模块,这样的细粒度设计,能更加灵活从业务中针对于对象加以细分,能更加灵活的拆分聚合服务.而这篇文章我们来谈谈基于docker 如何部署 surging源码下载 2.概述 容器,就是用来存放镜像的器皿,而镜像是构建成的一个轻量的.独立的.可执行
-
详解基于docker搭建lanproxy内网穿透服务
文档更新说明 2018年04月06日 v1.0 内网穿透相信是后端开发者经常遇到的需求,可是怎么实现呢?其实有现成的服务:花生壳.ngrok等,但是,最近花生壳宣布,免费版的内网穿透将不支持80端口映射了,而免费版的ngrok也不够稳定,于是乎,我就开始需找新的解决方案了 本文使用了docker.nginx,要全部搞懂的话需要一定的后端基础(当然,基本上入个门就可以了),个人认为还是有一定阅读门槛的,但是你如果只是想把服务搭建起来,按照步骤来做是不难的 1.概述 内网穿透其实就是用服务器做一个中
-
详解基于docker-swarm搭建持续集成集群服务
前言 本文只为自己搭建过程中的一些简单的记录.如果实践中有疑问,可以一起探讨. 为了能在本机(macOS)模拟集群环境,使用了vb和docker-machine.整体持续集成的几个机器设施如下: 1.服务节点:三个manager节点,一个worker节点.manager需要占用更多的资源,manager配置尽量高一些.swarm的manager节点的容错率是 (N-1)/2 .N是manager节点数.也就是如果有3个manager,那就能容忍一个manager节点挂掉.官方的算法说明:Raft
-
详解基于Docker的服务部署流程
本次总结涉及到Docker-io.Docker-ce的安装.CentOS7镜像的制作.Docker私有仓库搭建.CentOS6.7环境下从CentOS7私有仓库拉取私有镜像.Docker容器运行.CentOS6.5及CentOS7一起运行时兼容性处理等内容. 一.Docker基本组件及DevOps运作流程 DockerImage:Docker镜像是一个运行容器的只读模板. DockerContainer:Docker容器是一个运行应用的标准化单元. DockerRegistry:Docker注册
-
详解使用Docker快速部署ELK环境(最新5.5.1版本)
在Linux服务器上安装Docker以后,Pull相关的官方Docker镜像: docker pull docker.elastic.co/elasticsearch/elasticsearch:5.5.1 docker pull docker.elastic.co/kibana/kibana:5.5.1 docker pull docker.elastic.co/logstash/logstash:5.5.1 启动Elastic Search容器: docker run -p 9200:920
-
详解使用 docker compose 部署 golang 的 Athens 私有代理问题
目录 go中私有代理搭建 前言 为什么选择 athens 使用 docker-compose 部署 配置私有仓库的认证信息 配置下载模式 部署 使用秘钥的方式认证私有仓库 1.配置秘钥 2.配置 HTTP 与 SSH 重写规则 3.配置 SSH 来绕过主机 SSH 键验证 参考 go中私有代理搭建 前言 最近公司的代理出现问题了,刚好借这个机会来学习下,athens 如何构建私有代理 为什么选择 athens 私有化代理的选取标准无非就是下面的几点 1.托管私有模块: 2.排除对公有模块的访问:
-
详解基于深度学习的两种信源信道联合编码
概述 经典端对端无线通信系统如下图所示: 信源 xx使用信源编码,去除冗余得到比特流 ss. 对 ss进行信道编码(如 Turbo.LDPC 等)得到 yy,增加相应的校验位来抵抗信道噪声. 对比特流 yy进行调制(如 BPSK.16QAM 等)得到 zz,并经物理信道发送. 接收端对经信道后的符号 \bar{z}zˉ 进行解调.解码操作得到 \bar{x}xˉ. 根据定义信道方式不同,基于深度学习的信源信道联合编码(Deep JSCC)可以分为两类. 第一类,受无编码传输的启发,将信源编码.信
-
详解用Docker快速搭建一个博客网站
目录 一.准备工作 二.部署流程 三.访问测试 Halo 是一款现代化的个人独立博客系统,给习惯写博客的同学多一个选择. 官网地址:https://halo.run/ 一.准备工作 本章教程基于Docker搭建,所以需要你提前在服务器上安装好Docker环境. Docker安装教程:https://www.jb51.net/article/94067.htm 二.部署流程 (1)创建工作目录 mkdir ~/.halo && cd ~/.halo (2)下载配置文件到工作目录 wget
-
zabbix 4.04 安装文档教程详解(基于CentOS 7.6)
1 安装前准备: 1.1 安装JDK 卸载openjdk # rpm -qa | grep java # yum remove java-1.8.0-openjdk # yum remove java-1.8.0-openjdk-headless 安装JDK包 # rpm -ivh jdk-8u191-linux-x64.rpm 1.2 安装依赖包 # yum install -y net-snmp net-snmp-devel OpenIPMI-devel libssh2-dev
-
详解用Docker构建MySQL主从环境
前言 本篇文章记录我使用 docker-compose 以及 dockerfile 来构建基于 binlog 的 MySQL 主从环境.如果你严格按照文中的步骤进行配置,相信很快就可以搭建好一个基础的 MySQL 主从环境. 介绍 MySQL 主从同步分为 3 个步骤: master 节点将数据的更新记录写到 binary log 中. slave 节点开启 IO 线程连接 master 节点,请求获取指定 binary log 文件的指定位置之后的日志. master 节点的 binary l