Linux 内核通用链表学习小结
描述
在linux内核中封装了一个通用的双向链表库,这个通用的链表库有很好的扩展性和封装性,它给我们提供了一个固定的指针域结构体,我们在使用的时候,只需要在我们定义的数据域结构体中包含这个指针域结构体就可以了,具体的实现、链接并不需要我们关心,只要调用提供给我们的相关接口就可以完成了。
传统的链表结构
struct node{
int key;
int val;
node* prev;
node* next;
}
linux 内核通用链表库结构
提供给我们的指针域结构体:
struct list_head {
struct list_head *next, *prev;
};
我们只需要包含它就可以:
struct node{
int val;
int key;
struct list_head* head;
}
可以看到通过这个 list_head 结构就把我们的数据层跟驱动层分开了,而内核提供的各种操作方法接口也只关心 list_head 这个结构,也就是具体链接的时候也只链接这个list_head 结构,并不关心你数据层定义了什么类型.
一些接口宏定义
//初始化头指针
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
//遍历链表
#define __list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
//获取节点首地址(不是list_head地址,是数据层节点首地址)
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
//container_of在Linux内核中是一个常用的宏,用于从包含在某个
//结构中的指针获得结构本身的指针,通俗地讲就是通过结构体变
//量中某个成员的首地址进而获得整个结构体变量的首地址
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
#define offsetof(s,m) (size_t)&(((s *)0)->m)
使用方式
typedef struct node{
int val;
int key;
struct list_head* list;
}node;
//初始化头指针
LIST_HEAD(head);
//创建节点
node* a = malloc(sizeof(node));
node* b = malloc(sizeof(node));
//插入链表 方式一
list_add(&a->list,&head);
list_add(&b->list,&head);
//插入链表 方式二
list_add_tail(&a->list,&head);
list_add_tail(&b->list,&head);
//遍历链表
struct list_head* p;
struct node* n;
__list_for_each(p,head){
//返回list_head地址,然后再通过list_head地址反推
//节点结构体首地址.
n = list_entry(pos,struct node,list);
}
list_add 接口,先入后出原则,有点类似于栈
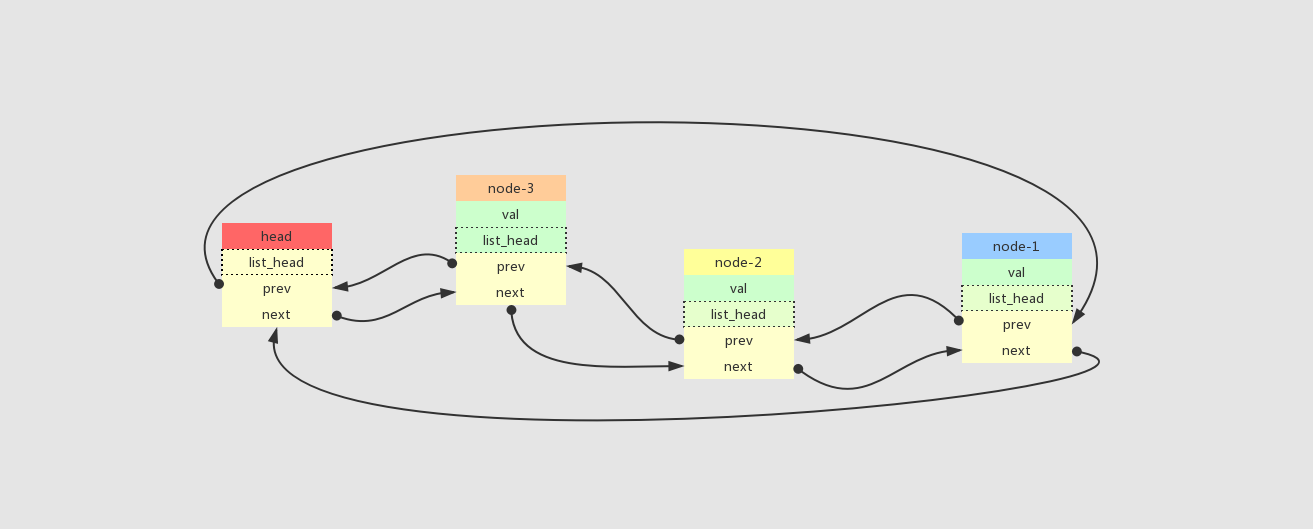
list_add-先入后出模式
list_add_tail 接口,先入先出原则,有点类似于fifo
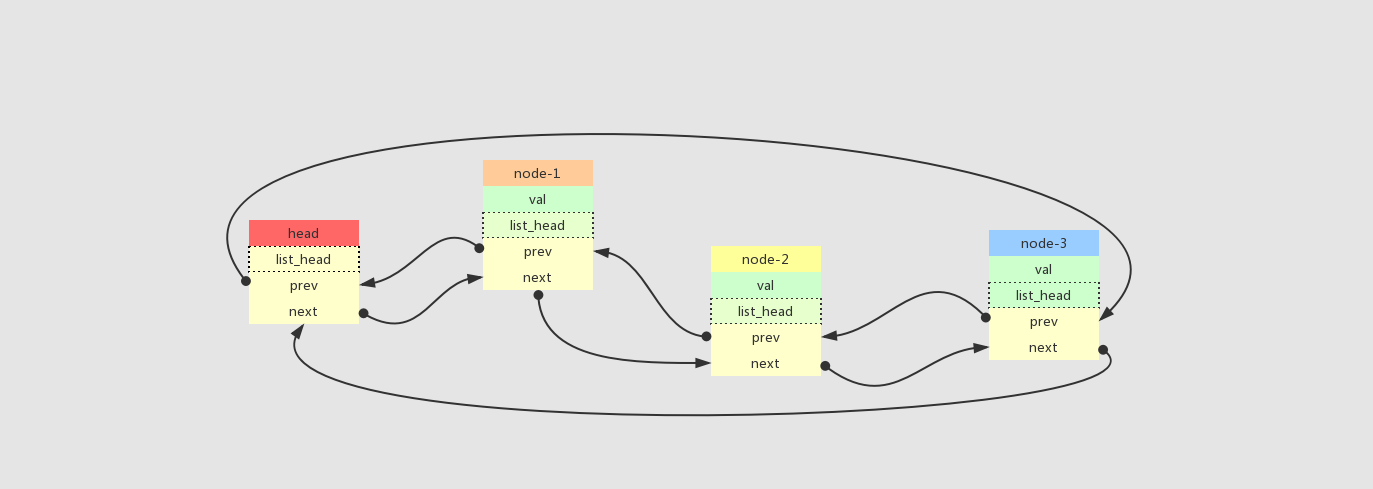
list_add-先入先出模式
我们的链表节点,实际在内存中的展示形态
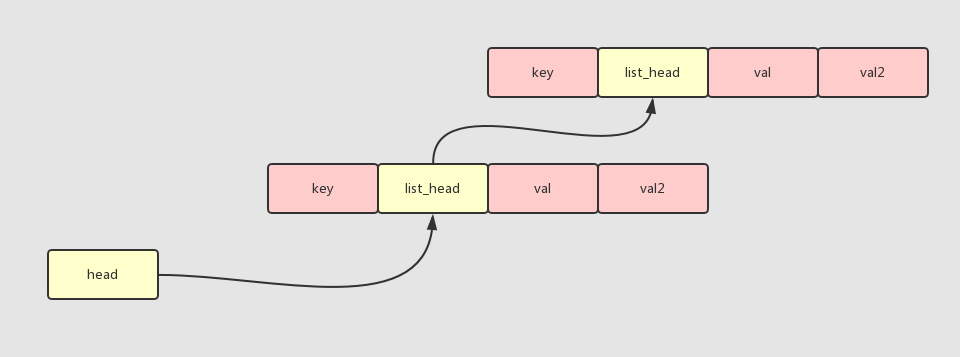
节点描述
可以看到最终的形态是,通过指向每个结构体里面的 list_head 类型指针,然后把它们串联起来的
list_entry 接口,通过结构体变量某个成员的地址,反推结构体首地址,就像 __list_for_each 接口只返回 list_head 地址,所以我们要通过这个成员地址在去获取它本身的结构体首地址,底层实现方法 container_of 宏

反推结构体首地址
举个例子
这个例子包括简单的增、删、遍历
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/list.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("David Xie");
MODULE_DESCRIPTION("List Module");
MODULE_ALIAS("List module");
struct student //代表一个实际节点的结构
{
char name[100];
int num;
struct list_head list; //内核链表里的节点结构
};
struct student *pstudent;
struct student *tmp_student;
struct list_head student_list;
struct list_head *pos;
int mylist_init(void)
{
int i = 0;
//初始化一个链表,其实就是把student_list的prev和next指向自身
INIT_LIST_HEAD(&student_list);
pstudent = kmalloc(sizeof(struct student)*5,GFP_KERNEL);//向内核申请5个student结构空间
memset(pstudent,0,sizeof(struct student)*5); //清空,这两个函数可以由kzalloc单独做到
for(i=0;i<5;i++)
{ //为结构体属性赋值
sprintf(pstudent[i].name,"Student%d",i+1);
pstudent[i].num = i+1;
//加入链表节点,list_add的话是在表头插入,list_add_tail是在表尾插入
list_add( &(pstudent[i].list), &student_list);//参数1是要插入的节点地址,参数2是链表头地址
}
list_for_each(pos,&student_list) //list_for_each用来遍历链表,这是个宏定义
//pos在上面有定义
{
//list_entry用来提取出内核链表节点对应的实际结构节点,即根据struct list_head来提取struct student
//第三个参数list就是student结构定义里的属性list
//list_entry的原理有点复杂,也是linux内核的一个经典实现,这个在上面那篇链接文章里也有讲解
tmp_student = list_entry(pos,struct student,list);
//打印一些信息,以备验证结果
printk("<0>student %d name: %s/n",tmp_student->num,tmp_student->name);
}
return 0;
}
void mylist_exit(void)
{
int i ;
/* 实验:将for换成list_for_each来遍历删除结点,观察要发生的现象,并考虑解决办法 */
for(i=0;i<5;i++)
{
//额,删除节点,只要传个内核链表节点就行了
list_del(&(pstudent[i].list));
}
//释放空间
kfree(pstudent);
}
module_init(mylist_init);
module_exit(mylist_exit);
结束
linux 内核提供的这个通用链表库里面还有很多其他的接口,这里没有详细的一一举例,有兴趣的可以自己去看看,在源码包 include/linux/list.h 文件里面,不过通过阅读一些源代码确实对我们也有很大的提高,可以看看高手是如何去设计并实现,还可以学到一些技巧以及对代码细节的掌握~~.
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Linux内核链表实现过程
关于双链表实现,一般教科书上定义一个双向链表节点的方法如下: 复制代码 代码如下: struct list_node{stuct list_node *pre;stuct list_node *next;ElemType data; } 即一个链表节点包含:一个指向前向节点的指针.一个指向后续节点的指针,以及数据域共三部分.但查看linux内核代码中的list实现时,会发现其与教科书上的方法有很大的差别.来看看linux是如何实现双链表.双链表节点定义 复制代码 代码如下: struct lis
-
Linux中的内核链表实例详解
Linux中的内核链表实例详解 链表中一般都要进行初始化.插入.删除.显示.释放链表,寻找节点这几个操作,下面我对这几个操作进行简单的介绍,因为我的能力不足,可能有些东西理解的不够深入,造成一定的错误,请各位博友指出. A.Linux内核链表中的几个主要函数(下面是内核中的源码拿出来给大家分析一下) 1)初始化: #define INIT_LIST_HEAD(ptr) do { \ (ptr)->next = (ptr); (ptr)->prev = (ptr); \ } while (0)
-

Linux 内核通用链表学习小结
描述 在linux内核中封装了一个通用的双向链表库,这个通用的链表库有很好的扩展性和封装性,它给我们提供了一个固定的指针域结构体,我们在使用的时候,只需要在我们定义的数据域结构体中包含这个指针域结构体就可以了,具体的实现.链接并不需要我们关心,只要调用提供给我们的相关接口就可以完成了. 传统的链表结构 struct node{ int key; int val; node* prev; node* next; } linux 内核通用链表库结构 提供给我们的指针域结构体: struct list
-
Linux内核设备驱动之内核中链表的使用笔记整理
/******************** * 内核中链表的应用 ********************/ (1)介绍 在Linux内核中使用了大量的链表结构来组织数据,包括设备列表以及各种功能模块中的数据组织.这些链表大多采用在include/linux/list.h实现的一个相当精彩的链表数据结构. 链表数据结构的定义很简单: struct list_head { struct list_head *next, *prev; }; list_head结构包含两个指向list_head结构的
-
Linux内核中红黑树算法的实现详解
一.简介 平衡二叉树(BalancedBinary Tree或Height-Balanced Tree) 又称AVL树.它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1.若将二叉树上结点的平衡因子BF(BalanceFactor)定义为该结点的左子树的深度减去它的右子树的深度,则平衡二叉树上所有结点的平衡因子只可能是-1.0和1.(此段定义来自严蔚敏的<数据结构(C语言版)>) 红黑树 R-B Tree,全称是Red-B
-
解析Linux内核的基本的模块管理与时间管理操作
内核模块管理 Linux设备驱动会以内核模块的形式出现,因此学会编写Linux内核模块编程是学习linux设备驱动的先决条件. Linux内核的整体结构非常庞大,其包含的组件非常多.我们把需要的功能都编译到linux内核,以模块方式扩展内核功能. 先来看下最简单的内核模块 #include <linux/init.h> #include <linux/module.h> static int __init hello_init(void) { printk(KERN_ALERT &
-
详解Linux内核中的container_of函数
前言 在linux 内核中,container_of 函数使用非常广,例如 linux内核链表 list_head.工作队列work_struct中. 在linux内核中大名鼎鼎的宏container_of() ,其实它的语法很简单,只是一些指针的灵活应用,它分两步: 第一步,首先定义一个临时的数据类型(通过typeof( ((type *)0)->member )获得)与ptr相同的指针变量__mptr,然后用它来保存ptr的值. 第二步,用(char *)__mptr减去member在结构体
-
探索Linux内核:Kconfig的秘密
深入了解Linux配置/构建系统是如何工作的. 自从Linux内核代码迁移到Git之后,Linux内核配置/构建系统(也称为Kconfig/kBuild)已经存在了很长时间.然而,作为支持基础设施,它很少受到关注:即使在日常工作中使用它的内核开发人员也从未真正考虑过它. 为了探索Linux内核是如何编译的,本文将深入研究Kconfig/kBuild内部进程,解释.config文件和vmlinux/bzImage文件是如何生成的,并介绍一个用于依赖性跟踪的智能技巧. Kconfig 构建内核的第一
-
增强Linux内核中访问控制安全的方法
背景 前段时间,我们的项目组在帮客户解决一些操作系统安全领域的问题,涉及到windows,Linux,macOS三大操作系统平台.无论什么操作系统,本质上都是一个软件,任何软件在一开始设计的时候,都不能百分之百的满足人们的需求,所以操作系统也是一样,为了尽可能的满足人们需求,不得不提供一些供人们定制操作系统的机制.当然除了官方提供的一些机制,也有一些黑魔法,这些黑魔法不被推荐使用,但是有时候面对具体的业务场景,可以作为一个参考的思路. Linux中常见的拦截过滤 本文着重介绍Linux平台上常见
-
Linux内核设备驱动之内核的时间管理笔记整理
/****************** * linux内核的时间管理 ******************/ (1)内核中的时间概念 时间管理在linux内核中占有非常重要的作用. 相对于事件驱动而言,内核中有大量函数是基于时间驱动的. 有些函数是周期执行的,比如每10毫秒刷新一次屏幕: 有些函数是推后一定时间执行的,比如内核在500毫秒后执行某项任务. 要区分: *绝对时间和相对时间 *周期性产生的事件和推迟执行的事件 周期性事件是由系统系统定时器驱动的 (2)HZ值 内核必须在硬件定时器的帮
-
高并发nginx服务器的linux内核优化配置讲解
由于默认的linux内核参数考虑的是最通用场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,是的Nginx可以拥有更高的性能: 在优化内核时,可以做的事情很多,不过,我们通常会根据业务特点来进行调整,当Nginx作为静态web内容服务器.反向代理或者提供压缩服务器的服务器时,期内核参数的调整都是不同的,这里针对最通用的.使Nginx支持更多并发请求的TCP网络参数做简单的配置: 以下linux 系统内核优化配置均经在线业务系统测试,并发10万左右服务器运行