详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧。
首先,还是列出一个我们用的DataFrame,注意index一列,如下:

接下来,介绍下各个函数的用法:
1、loc函数
愿意看官方文档的,请戳这里,这里一般最权威。
loc函数是基于“标签”选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例:
1.1 单个label
接受一个“标签”(label)参数,返回一个Series,例如下面这个例子收一个标签,返回通过这个标签定位的行的值,注意这里是通过标签定位,而不是通过中括号中的数字定位第几行,之后我们通过对比iloc函数时还会细说。
test_dict_df.loc[1] #return the row with name 'Bob' test_dict_df.loc[7] #return the row with name 'Time' important!!! # type(test_dict_df.loc[1]) #pandas.core.series.Series
1.2 一个label的array
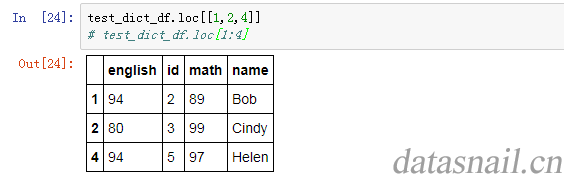
如果键入一个标签的array,那么就返回一个对应的DataFrame:
test_dict_df.loc[[1,2,4]]
结果如下:
1.3 加入一个切片array
test_dict_df.loc[[1:4]]
结果如下:

1.4 行标签,列标签
通过在中括号中加入行标签和列标签来定位一个cell,相当于坐标的定位:
test_dict_df.loc[1,'english'] #result:94
1.5 行标签或者列标签是切片array
test_dict_df.loc[1:4,'english'] # test_dict_df.loc[1:4,'english':'math']
1.6 还可以接受条件,进行选择
例如我们选择英语成绩超过90的所有行:
test_dict_df.loc[test_dict_df['english']>90]

当然,也可以再条件选择后,再加入列选择,列选择的时候可以单列,也可以是切片数组,通过上面的介绍这里就可以灵活处理:
test_dict_df.loc[test_dict_df['english']>90,'english'] #single label test_dict_df.loc[test_dict_df['english']>90,'english':'name'] #slice array test_dict_df.loc[test_dict_df['english']>90,['english','name']] #label array
1.7 接受一个boolean的array
可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值
test_dict_df.loc[[True,False,False,True]]
loc还有很多用法,这里先介绍到这里吧,当然如果你的DataFrame是复合的行或者复合列,写法也是不同的,具体就可以查阅官方文档了!
2、iloc函数
官方文档戳这里。
iloc函数与loc函数不同的是,它接受的是一个数字,代表着要选择数据的位置:
test_dict_df.iloc[6]
这代表我们选择的是第6行,而不是index为6的那一行。当然,也可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值:
test_dict_df.iloc[[True,False,False,True]]
这里iloc也可以接受切片array:
# test_dict_df.iloc[1:2] test_dict_df.iloc[[1,2,4]]
3、ix函数(0.20.0版本后已经弃用)
ix就是一种混合索引,字符串的标签和证书的数据索引都可以作为合法输入,其实相当于loc和iloc的一个混合方法:
test_dict_df.ix['Alice'] test_dict_df.ix[1]
上述两种方法都能得到值,这里我们就不追究这个函数具体是怎样的检索顺序或者工作原理了。因为官方给出的是从pandas0.20.0之后,ix函数已经被弃用。其实在使用的时候,ix函数虽然方便,但是的确有时候会显得比较混乱,所以我们之后也尽量少用这个函数吧,还是按照官方大佬的指导。
4、at函数
at是用来选择单个值的,此时用法类似于loc:
test_dict_df.at[1,'english'] test_dict_df.loc[1,'english']
以上两种方法都能选择到,label为1,列为'english'的那个值,但是据说at速度要快,这点我没有考证过。
5、iat函数
iat函数相对于at函数,就相当于iloc相对于loc函数。iat也只能选择一个值。只不过是用索引位置来选择,注意:行列都是索引位置来选择,从0开始数。
# test_dict_df.iat[1,'english'] #error!!! test_dict_df.iat[2,2] #right!!!
6、概括一下
最后我们概括一下:
1、 loc和iloc函数都是用来选择某行的,iloc与loc的不同是:iloc是按照行索引所在的位置来选取数据,参数只能是整数。而loc是按照索引名称来选取数据,参数类型依索引类型而定;
2、 at和iat函数是只能选择某个位置的值,iat是按照行索引和列索引的位置来选取数据的。而at是按照行索引和列索引来选取数据;
3、 loc和iloc函数的功能包含at和iat函数的功能。
相应的代码连接:github代码
先写到这里,如有新的再补充。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
详解pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧. 首先,还是列出一个我们用的DataFrame,注意index一列,如下: 接下来,介绍下各个函数的用法: 1.loc函数 愿意看官方文档的,请戳这里,这里一般最权威. loc函数是基于"标签"选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例: 1.1 单个label 接受一个"标签"(
-
详解pandas.DataFrame.plot() 画图函数
首先看官网的DataFrame.plot( )函数 DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False,
-

详解pandas.DataFrame中删除包涵特定字符串所在的行
你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除包涵特定字符串所在的行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详解pandas获取Dataframe元素值的几种方法
可以通过遍历的方法: pandas按行按列遍历Dataframe的几种方式:https://www.jb51.net/article/172623.htm 选择列 使用类字典属性,返回的是Series类型 data['w'] 遍历Series for index in data['w'] .index: time_dis = data['w'] .get(index) pandas.DataFrame.at 根据行索引和列名,获取一个元素的值 >>> df = pd.DataFrame(
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
详解pandas绘制矩阵散点图(scatter_matrix)的方法
使用散点图矩阵图,可以两两发现特征之间的联系 pd.plotting.scatter_matrix(frame, alpha=0.5, c,figsize=None, ax=None, diagonal='hist', marker='.', density_kwds=None,hist_kwds=None, range_padding=0.05, **kwds) 1.frame,pandas dataframe对象 2.alpha, 图像透明度,一般取(0,1] 3.figsize,以英寸为单
-
Python pandas 列转行操作详解(类似hive中explode方法)
最近在工作上用到Python的pandas库来处理excel文件,遇到列转行的问题.找了一番资料后成功了,记录一下. 1. 如果需要爆炸的只有一列: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[1]: A B 0 1 [1, 2] 1 2 [1, 2] 如果要爆炸B这一列,可以直接用explode方法(前提是你的pandas的版本要高于或等于0.25) df.explode('B') A B 0 1 1 1 1 2 2 2 1 3
-
详解pandas apply 并行处理的几种方法
1. pandarallel (pip install ) 对于一个带有Pandas DataFrame df的简单用例和一个应用func的函数,只需用parallel_apply替换经典的apply. from pandarallel import pandarallel # Initialization pandarallel.initialize() # Standard pandas apply df.apply(func) # Parallel apply df.parallel_ap